數據工程師的重要數據結構和算法
數據工程是有效管理大量數據的實踐,從存儲和處理到分析和可視化。因此,數據工程師必須精通數據結構和算法,以幫助他們有效地管理和操作數據。
本文將探討數據工程師應該熟悉的一些最重要的數據結構和算法,包括它們的用途和優勢。
數據結構
關系數據庫
關系數據庫是數據工程師最常用的數據結構之一。關系數據庫由一組表組成,表之間定義了關系。這些表用于存儲結構化數據,例如客戶信息、銷售數據和產品庫存。
關系數據庫通常用于電子商務平臺或銀行應用程序等交易系統。它們具有高度可擴展性,提供數據一致性和可靠性,并支持復雜的查詢。
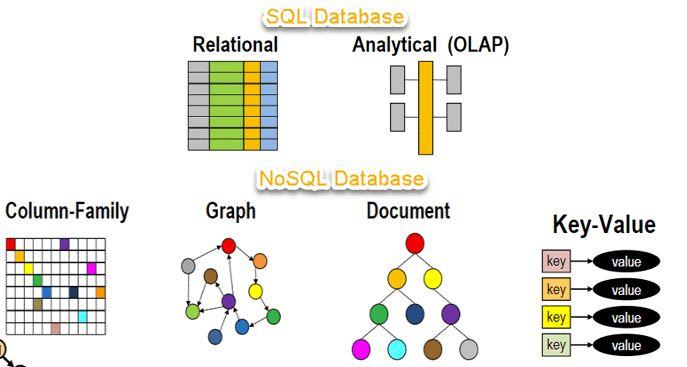
NoSQL 數據庫
NoSQL 數據庫是一種非關系型數據庫,用于存儲和管理非結構化或半結構化數據。與關系數據庫不同,NoSQL 數據庫不使用表或關系。相反,它們使用文檔、圖形或鍵值對存儲數據。
NoSQL 數據庫具有高度可擴展性和靈活性,使其非常適合處理大量非結構化數據,例如社交媒體提要、傳感器數據或日志文件。它們還具有很強的故障恢復能力,提供高性能,并且易于維護。
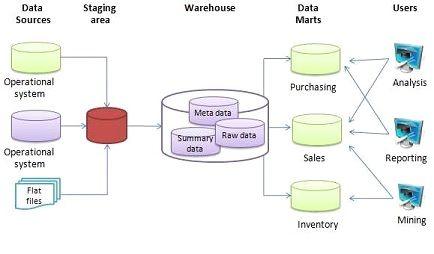
數據倉庫
數據倉庫是專為存儲和處理來自多個來源的大量數據而設計的專用數據庫。數據倉庫通常用于數據分析和報告,可以幫助簡化和優化數據處理工作流程。
數據倉庫具有高度可擴展性,支持復雜查詢,并且性能良好。它們還非常可靠,支持數據整合和規范化。
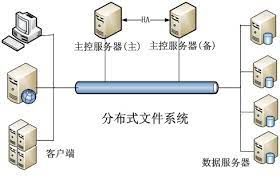
分布式文件系統
Hadoop 分布式文件系統(HDFS)等分布式文件系統用于跨多臺計算機存儲和管理大量數據。此外,這些高度可擴展的文件系統提供容錯并支持批處理。
分布式文件系統用于存儲和處理大量非結構化數據,例如日志文件或傳感器數據。它們還具有高度的故障恢復能力并支持并行處理,使其成為大數據處理的理想選擇。
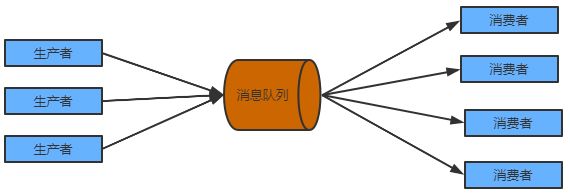
消息隊列
消息隊列用于管理數據處理管道的不同組件之間的數據流。它們有助于解耦系統的不同部分,提高可擴展性和容錯性,并支持異步通信。
消息隊列用于實現分布式系統,例如微服務或事件驅動架構。它們具有高度可擴展性,支持高吞吐量,并提供對系統故障的恢復能力。
算法
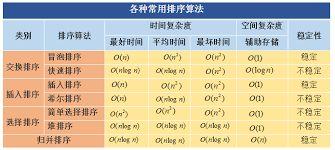
排序算法
排序算法用于按特定順序排列數據。排序是數據工程中必不可少的操作,因為它可以顯著提高各種操作(例如搜索、合并和連接)的性能。排序算法可以分為兩類:基于比較的排序算法和非基于比較的排序算法。
基于比較的排序算法,例如冒泡排序、插入排序、快速排序和合并排序,比較數據中的元素以確定順序。這些算法的時間復雜度在平均情況下為 O(n log n),在最壞情況下為 O(n^2)。
非基于比較的排序算法(例如計數排序、基數排序和桶排序)不比較元素來確定順序。因此,這些算法在平均情況和最壞情況下的時間復雜度均為 O(n)。
排序算法用于各種數據工程任務,例如數據預處理、數據清理和數據分析。
搜索算法
搜索算法用于查找數據集中的特定元素。搜索算法在數據工程中是必不可少的,因為它們可以從大型數據集中高效地檢索數據。搜索算法可以分為兩類:線性搜索和二分搜索。
線性搜索是一種簡單的算法,它檢查數據集中的每個元素,直到找到目標元素。線性搜索在最壞情況下的時間復雜度為 O(n)。
二進制搜索是一種更有效的算法,適用于排序的數據集。二分搜索在每一步將數據集分成兩半,并將中間元素與目標元素進行比較。在最壞的情況下,二分查找的時間復雜度為 O(log n)。
搜索算法用于各種數據工程任務,例如數據檢索、數據查詢和數據分析。
哈希算法
散列算法用于將任意大小的數據映射到固定大小的值。哈希算法在數據工程中是必不可少的,因為它們可以實現高效的數據存儲和檢索。散列算法可以分為兩類:加密散列和非加密散列。
SHA-256 和 MD5 等加密哈希算法用于安全數據存儲和傳輸。這些算法產生一個固定大小的散列值,該散列值對于輸入數據是唯一的。因此,無法通過反轉哈希值來獲得原始輸入數據。
MurmurHash 和 CityHash 等非加密哈希算法用于高效的數據存儲和檢索。這些算法根據輸入數據生成固定大小的哈希值。哈希值可用于快速搜索大型數據集中的輸入數據。
哈希算法用于各種數據工程任務,例如數據存儲、數據檢索和數據分析。
圖算法
圖算法用于分析可以表示為圖的數據。圖用于表示數據元素(例如社交網絡、網頁和分子)之間的關系。圖算法可以分為兩類:遍歷算法和尋路算法。
廣度優先搜索 (BFS) 和深度優先搜索 (DFS) 等遍歷算法用于訪問圖中的所有節點。遍歷算法可用于查找連通分量、檢測循環和執行拓撲排序。
Dijkstra 算法和 A* 算法等尋路算法用于尋找圖中兩個節點之間的最短路徑。例如,尋路算法可用于尋找道路網絡中的最短路徑,為送貨卡車尋找最佳路線,為機器人尋找最高效的路徑。
數據結構和算法是數據工程師必不可少的工具,使他們能夠構建可擴展、高效和優化的解決方案來管理和處理大型數據集。