ByteHouse 實時導入技術演進

ByteHouse 是火山引擎上的一款云原生數據倉庫,為用戶帶來極速分析體驗,能夠支撐實時數據分析和海量離線數據分析;便捷的彈性擴縮容能力,極致的分析性能和豐富的企業級特性,助力客戶數字化轉型。
本文將從需求動機、技術實現及實際應用等角度,介紹基于不同架構的 ByteHouse 實時導入技術演進。

內部業務的實時導入需求
ByteHouse 實時導入技術的演進動機,起初于字節跳動內部業務的需求。
在字節內部,ByteHouse 主要還是以 Kafka 為實時導入的主要數據源(本文都以 Kafka 導入為例展開描述,下文不再贅述)。對于大部分內部用戶而言,其數據體量偏大;所以用戶更看重數據導入的性能、服務的穩定性以及導入能力的可擴展性。而對于數據延時性,大多數用戶只要是秒級可見就能滿足其需求。基于這樣的場景,ByteHouse 進行了定制性的優化。
分布式架構下的高可用

社區原生分布式架構
ByteHouse 首先沿用了 Clickhouse 社區的分布式架構,但分布式架構有一些天然性架構層面的缺陷,這些痛點主要表現在三個方面:
- 節點故障:當集群機器數量到達一定規模以后,基本每周都需要人工處理節點故障。對于單副本集群在某些極端 case 下,節點故障甚至會導致數據丟失。
- 讀寫沖突:由于分布式架構的讀寫耦合,當集群負載達到一定程度以后,用戶查詢和實時導入就會出現資源沖突——尤其是 CPU 和 IO,導入就會受到影響,出現消費 lag。
- 擴容成本:由于分布式架構數據基本都是本地存儲,在擴容以后,數據無法做 Reshuffle,新擴容的機器幾乎沒有數據,而舊的機器上磁盤可能已經快寫滿,造成集群負載不均的狀態,導致擴容并不能起到有效的效果。
這些是分布式架構天然的痛點,但是由于其天然的并發特性,以及本地磁盤數據讀寫的極致性能優化,可以說有利有弊。
社區實時導入設計
- High-Level 消費模式:依托 Kafka 自身的 rebalance 機制做消費負載均衡。
- 兩級并發
基于分布式架構的實時導入核心設計其實就是兩級并發:
一個 CH 集群通常有多個 Shard,每個 Shard 都會并發做消費導入,這就是第一級 Shard 間的多進程并發;
每個 Shard 內部還可以使用多個線程并發消費,從而達到很高的性能吞吐。
- 攢批寫入
就單個線程來說,基本消費模式是攢批寫入——消費一定的數據量,或者一定時間之后,再一次性寫入。攢批寫入可以更好地實現性能優化,查詢性能提升,并降低后臺 Merge 線程的壓力。
無法滿足的需求
上述社區的設計與實現,還是無法滿足用戶的一些高級需求:
- 首先部分高級用戶對數據的分布有著比較嚴格的要求,比如他們對于一些特定的數據有特定的 Key,希望相同 key 的數據落盤到同一個 Shard(比如唯一鍵需求)。這種情況下,社區 High Level 的消費模式是無法滿足的。
- 其次是 High level 的消費形式 rebalance 不可控,可能最終會導致 Clickhouse 集群中導入的數據在各個 Shard 之間分配不均。
- 當然,消費任務的分配不可知,在一些消費異常情景下,想要排查問題也變得非常困難;對于一個企業級應用,這是難以接受的。
自研分布式架構消費引擎 HaKafka
為了解決上述需求,ByteHouse 團隊基于分布式架構自研了一種消費引擎——HaKafka。
高可用(Ha)
HaKafka 繼承了社區原有 Kafka 表引擎的消費優點,再重點做了高可用的 Ha 優化。
就分布式架構來談,其實每個 Shard 內可能都會有多個副本,在每個副本上都可以做 HaKafka 表的創建。但是 ByteHouse 只會通過 ZK 選一個 Leader,讓 Leader 來真正地執行消費流程,其他節點位于 Stand by 狀態。當 Leader 節點不可用了,ZK 可以在秒級將 Leader 切到 Stand by 節點繼續消費,從而實現一種高可用。
Low—Level 消費模式
HaKafka 的消費模式從 High Level 調整到了 Low Level 模式。Low Level 模式可以保證 Topic Partition 有序和均勻地分配到集群內各個 shard;與此同時,Shard 內部可以再一次用多線程,讓每個線程來消費不同 Partition。從而完全繼承了社區 Kafka 表引擎兩級并發的優點。
在 Low-Level 消費模式下,上游用戶只要在寫入 Topic 的時候,保證沒有數據傾斜,那么通過 HaKafka 導入到 Clickhouse 里的數據肯定也是均勻分布在各個 shard 的。
同時,對于有特殊數據分布需求——將相同 Key 的數據寫到相同 Shard——的高級用戶,只要在上游保證相同 Key 的數據寫入相同 Partition,那么導入 ByteHouse 也就能完全滿足用戶需求,很好地支持唯一鍵等場景。

場景一:
基于上圖可見,假設有一個雙副本的 Shard,每個副本都會有一張相同的 HaKafka 表處于 Ready 的狀態。但是只有通過 ZK 選主成功的 leader 節點上,HaKafka 才會執行對應的消費流程。當這個 leader 節點宕機以后, 副本 Replica 2 會自動再被選為一個新的 Leader,繼續消費,從而保證高可用。

場景二:
在節點故障場景下,一般需要執行替換節點流程。對于分布式節點替換有一個很繁重的操作——拷貝數據。
如果是一個多副本的集群,一個副本故障,另一個副本是完好的。我們很自然希望在節點替換階段,Kafka 消費放在完好的副本 Replica 2 上,因為其上舊數據是完備的。這樣 Replica 2 就始終是一個完備的數據集,可以正常對外提供服務。這一點 HaKafka 是可以保證的。HaKafka 選主的時候,如果確定有某一個節點在替換節點流程當中,會避免將其選為 Leader。
導入性能優化:Memory Table

HaKafka 還做到了 Memory Table 的優化。
考慮這樣一個場景:業務有一個大寬表,可能有上百列的字段 或者上千的 Map-Key。由于 ClickHouse 每一個列都會對應落盤為一個具體的文件,列越多,每次導入寫的文件也就越多。那么,相同消費時間內,就會頻繁地寫很多的碎文件,對于機器的 IO 是很沉重的負擔,同時給 MERGE 帶來很大壓力;嚴重時甚至導致集群不可用。為了解決這種場景,我們設計了 Memory Table 實現導入性能優化。
Memory Table 的做法就是每一次導入數據不直接刷盤,而是存在內存中;當數據達到一定量以后,再集中刷盤,減少 IO 操作。Memory Table 可以提供對外查詢服務的,查詢會路由到消費節點所在的副本去讀 Memory Table 里邊的數據,這樣保證了不影響數據導入的延時性。從內部使用經驗來看,Memory Table 不僅很好地解決了部分大寬表業務導入需求,而且導入性能最高可以提升 3 倍左右。
云原生新架構
鑒于上文描述的分布式架構的天然缺陷,ByteHouse 團隊一直致力于對架構進行升級。我們選擇了業務主流的云原生架構,新的架構在 2021 年初開始服務字節內部業務,并于 2023 年初進行了代碼開源 [ByConity] https://github.com/ByConity/ByConity。

云原生架構本身有著很天然的自動容錯能力以及輕量級的擴縮容能力。同時,因為它的數據是云存儲的,既實現了存儲計算分離,數據的安全性和穩定性也得到了提高。當然,云原生架構也不是沒有缺點,將原來的本地讀寫改為遠端讀寫,必然會帶來一定的讀寫性能損耗。但是,以一定的性能損耗來換取架構的合理性,降低運維成本,其實是利大于弊的。

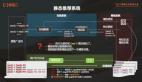
上圖是 ByteHouse 云原生架構的架構圖,本文針對實時導入這塊介紹幾個重要的相關組件。
- Cloud Service
首先,總架構分為三層,第一層是 Cloud Service,主要包含 Server 和 Catlog 兩個組件。這一層是服務入口,用戶的所有請求包括查詢導入都從 Server 進入。Server 只對請求做預處理,不具體執行;在 Catlog 查詢元信息后,把預處理的請求和元信息下發到 Virtual Warehouse 執行。
- Virtual Warehouse
Virtual Warehouse 是執行層。不同的業務,可以有獨立的 Virtual Warehouse,從而做到資源隔離。現在 Virtual Warehouse 主要分為兩類,一類是 Default,一類是 Write,Default 主要做查詢,Write 做導入,實現讀寫分離。
- VFS
最底層是 VFS(數據存儲),支持 HDFS、S3、aws 等云存儲組件。
基于云原生架構的實時導入設計
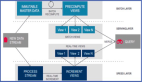
在云原生架構下,Server 端不做具體的導入執行,只做任務管理。因此在 Server 端,每個消費表會有一個 Manager,用來管理所有的消費執行任務,并將其調度到 Virtual Warehouse 上執行。
因為繼承了 HaKafka 的 Low Level 消費模式,Manager 會根據配置的消費任務數量,將 Topic Partition 均勻分配給各個任務;消費任務的數量是可配置的,上限是 Topic Partition 數目。

基于上圖,大家可以看到左邊是 Manager ,從 catalog 拿到對應的Offset,然后根據指定的消費任務數目,來分配對應的消費 Partition、并調度到 Virtual Warehouse 的不同節點來執行。
新的消費執行流程

因為云原生新架構下是有事務 Transaction 保證的,所有操作都希望在一個事務內完成,也更加的合理化。
依托云原生新架構下的 Transaction 實現,每個消費任務的消費流程主要包括以下步驟:
- 消費開始前,Worker 端的任務會先通過 RPC 請求,向 Server 端請求創建一個事務
- 執行 rdkafka::poll(),消費一定時間(默認8s)或者足夠大的 block
- 將 block 轉化為 Part 并 Dump 到 VFS(此時數據不可見)
- 通過 RPC 請求向 Server 發起事務 Commit 請求
- (事務中 Commit 的數據包括:dump 完成的 part 元數據以及對應 Kafka offset)
- 事務提交成功(數據可見)
容錯保證
從上述消費流程里可以看到,云原生新架構下的消費,容錯保證主要是基于 Manager 和 Task 的雙向心跳以及快速失敗策略:
- Manager 本身會有一個定期的探活,通過 RPC 檢查調度的 Task 是否在正常執行;
- 同時每個 Task 會在消費中借助事務 RPC 請求來校驗自己的有效性,一旦校驗失敗,它可以自動 kill;
- 而 Manager 一旦探活失敗,則會立即拉起一個新的消費任務,實現秒級的容錯保證。
消費能力
關于消費能力的話,上文提到它是一個可擴展性的,消費任務數量可以由用戶來配置,最高可以達到 Topic 的 Partition 數目。如果 Virtual Warehouse 中節點負載高的話,也可以很輕量地擴節點。
當然,Manager 調度任務實現了基本的負載均衡保證——用 Resource Manager 來做任務的管理和調度。
語義增強:Exactly—Once
最后,云原生新架構下的消費語義也有一個增強——從分布書架構的 At-Least-Once 升級到 Exactly—Once。
因為分布式架構是沒有事務的,只能做到一個 At-Least-Once,就是任何情況下,保證不丟數據,但是一些極端情況可能會有重復消費發生。到了云原生架構,得益于 Transaction 的實現,每一次消費都可以通過事務讓 Part 和 Offset 實現原子性提交,從而達到 Exactly—Once 的語義增強。
Memory buffer

對應 HaKafka 的 memory table,云原生架構同樣實現了導入內存緩存 Memory Buffer。
與 Memory Table 不同的是,Memory Buffer 不再綁定到 Kafka 的消費任務上,而是實現為存儲表的一層緩存。這樣 Memory Buffer 就更具有通用性,不僅是 Kafka 導入可以使用,像 Flink 小批量導入的時候也可以使用。
同時,我們引入了一個新的組件 WAL 。數據導入的時候先寫 WAL,只要寫成功了,就可以認為數據導入成功了——當服務啟動后,可以先從 WAL 恢復未刷盤的數據;之后再寫 Memory buffer,寫成功數據就可見了——因為 Memory Buffer 是可以由用戶來查詢的。Memory Buffer 的數據同樣定期刷盤,刷盤后即可從 WAL 中清除。
業務應用及未來思考
最后簡單介紹實時導入在字節內部的使用現狀,以及下一代實時導入技術的可能優化方向。
ByteHouse 的實時導入技術是以 Kafka 為主,每天的數據吞吐是在 PB 級,導入的單個線程或者說單個消費者吞吐的經驗值在 10-20MiB/s。(這里之所以強調是經驗值,因為這個值不是一個固定值,也不是一個峰值;消費吞吐很大程度上取決于用戶表的復雜程度,隨著表列數增加,導入性能可能會顯著降低,無法使用一個準確的計算公式。因此,這里的經驗值更多的是字節內部大部分表的導入性能經驗值。)
除了 Kafka,字節內部其實還支持一些其他數據源的實時導入,包括 RocketMQ、Pulsar、MySQL(MaterializedMySQL)、 Flink 直寫等。
關于下一代實時導入技術的簡單思考:
- 更通用的實時導入技術,能夠讓用戶支持更多的導入數據源。
- 數據可見延時和性能的一個折衷。