微博推薦實時大模型的技術演進

一、技術路線回顧
1、業務場景與特點
本團隊在微博 APP 中負責的推薦業務主要包括:
① 首頁推薦下的所有 tab 欄的內容,信息流產品一般都是第一個 tab 流量占比較高;
② 熱搜向下滑進入的一個信息流,這也是我們的業務場景,也包括這個頁面上的其他信息流 tab,比如視頻頻道等;
③ 在整個 APP 當中搜索或者點擊推薦視頻,進入的沉浸視頻場景。

我們的業務具有如下一些特點:
(1)首先,從推薦實現的視角來看:
① 業務場景多。
② 微博 UI 上用戶對操作和反饋多樣,內容既可以點擊進入正文頁觀看,也可以在流內消費,流內反饋多樣如點進博主個人頁、點進正文頁、點圖片、點視頻、轉評贊等。
③ 可分發的物料類型多,如首頁推薦可分發長圖、圖片(一圖或多圖)、視頻(橫版或豎版視頻)、 文章等。
(2)從產品定位角度來看:
① 服務熱點:微博在熱點爆發前后,流量變化特別大,用戶能在推薦里面順暢消費熱點內容,是公司對推薦產品的要求。
② 構建關系:希望在推薦的微博里沉淀一些社交關系。
2、技術選型
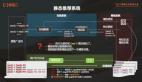
下圖展示了我們這幾年的技術進步脈絡。

當前的推薦框架來講千億特征、萬億參數是標配。與 NLP 和 CV 不同,這兩個方向太大的模型是網絡本身復雜度高,推薦場景有較好的稀疏性,模型尺寸比較大,訓練往往使用數據并行的方式,每個用戶 serving 并不需要全部模型參數。
本團隊從 2018 年至 2022 年的技術演進,主要是大規模和實時性兩個方面。在此基礎上再做復雜結構,來達到事半功倍的效果。
這里簡要介紹一下我們的 Weidl 在線學習平臺。

主要流程為:用戶行為拼接樣本,給模型來進行學習,再推薦給用戶反饋回來,整體采用數據流優先的設計原則來達到更好的靈活性。無論使用什么方式訓練 KERNEL,離線的模型存儲和在線的 PS 之間的實時更新部分還是在的。不管是用手寫的 LR 或 FM,或者 Tensorflow,或者 DeepRec 訓練模型都是可以的,對應的模型存儲都是我們自己搭建的一套數據流,模型格式也是我們自己做的,從而保證多 Backend 下從模型訓練到線上更新能夠在分鐘級以下,下次用戶調用時能用到新的參數。在這種設計原則下,可以很方便的切換 Backend。
Weidl 是微博自研機器學習平臺,其中 Bridge 模式可以調用各個深度學習框架的算子,也可以不用 Bridge 模式,替換成自研算子也很方便。比如我們之前使用 Tensorflow,會對 tf 進行一些內存分配和算子的優化,2022 年下半年切換到 DeepRec,對 DeepRec 多一些了解之后,會發現之前基于 tf 的一些性能上的優化點和 DeepRec 是殊途同歸的。
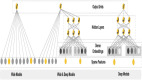
下圖中列出了本團隊這些年做的一些版本,方便大家理解我們業務中各個技術點的貢獻度,首先是用基于 FM 的模型解決大規模實時推薦問題,后面依次做了基于深度的復雜結構。從結果來看,前面使用非深度模型解決在線實時問題帶來的收益也很大。

信息流推薦與商品的推薦不同,信息流推薦基本都是大規模實時深度結構。這塊也有一些難點和分歧點,比如:特征實時并不是模型實時的替代方案,對推薦系統來講,模型學到的才是比較重要的;另外在線學習確實會帶來一些迭代上的問題,但在絕對收益前,都是可以花時間克服的。

二、大模型近期技術迭代
這一章節會從目標、結構和特征幾方面來介紹業務的迭代模型。
1、多目標融合
微博場景用戶操作很多,用戶表達對 Item 的喜歡會有很多種行為,比如點擊互動、時長、下拉等,每個目標都是要去建模預估,最后整體融合排序,這塊對推薦業務來講是很重要的。最開始做的時候,是通過靜態融合加離線搜參來做,后來通過強化學習的方法,變成動態搜參,之后又做了一些融合公式優化,后面還改進成通過模型來輸出一些融合分等。

強化調參的核心做法是,把線上流量分成一些小的流量池,通過一些線上當前的參數,去生成一些新的參數,去看用戶對這些參數的反應,收集反饋進行迭代。其中比較核心的部分是 reward 的計算,其中用了 CEM、ES。后邊用了自研的算法,以適應自身業務需求。因為在線學習變化是非常快的,參數要不能隨之變化的話就會出現比較大的問題,比如大家對于視頻類內容的偏好從周五晚上到周六早上和周日晚上到周一早上,偏好的變化是非常快的,整個融合參數的變化要反映出用戶對一些東西的偏好的變化。

下面是模型優化中的一些小 trick,用戶每天使用是帶周期性的,每天定時 init 校正是比較好的,不然可能會走到比較偏的分支;參數初始化的時候要服從先驗分布,先進行先驗化分析,再去進行差異化融合;加入異常檢測機制,保證融合參數能一致迭代更新。

融合公式一開始選用加法融合,當時業務目標還沒有那么多,后來隨著目標增多,發現加法融合不方便支持加更多的目標,會弱化各子目標的重要性影響,后邊使用了乘法融合公式。效果如 ppt 所示:

在全量版本升級為多任務之后,在此版本上優化成,通過模型進行目標融合。通過模型融合,能更好地捕捉很多非線性的東西,具有更好的表達力,這樣也能做到個性化融合,每個用戶融出來的東西是不一樣的。

2、多任務
多任務是從 2019 年、2020 年開始火起來的一個概念,推薦系統往往需要同時關注多個目標,比如我們的業務場景里有七個目標:點擊、時長、互動、完播、負反饋、進主頁、下拉刷新等。對每個目標各訓練一個模型會消耗較多的資源且繁瑣。并且,有些目標是稀疏的,有些則相對稠密一些,如果分開單獨做模型,那些比較稀疏的目標一般不容易學好,放在一起學習能解決稀疏目標學習的問題。

推薦多任務建模入門一般是從 MMOE 開始,到 SNR,再到 DMT,最后到全量的 MM,其實就是在 SNR 上做了融合網絡等優化。

在做多任務之前,重點要解決的問題包括:多目標之間各個 loss 是否有沖突,彼此是否會有蹺蹺板效應;樣本空間不一致的問題;loss 平衡問題等。在實際經驗中,無論是 PCGrad,UWL 的方法在測試數據都會體現出其作用,但如果放大到生產環境中,去在線學習不斷訓練的話,這些方法的作用就會衰減的比較快,反而根據經驗去設定一些值在整個在線實習環境中也不是不可行,這塊也不太確定是不是跟在線學習相關,還是與樣本量有關。單獨做 MMOE 的效果也是比較好的,左邊是業務上實際的一些收益點。

下面是從 MMOE 開始的一些技術演進。開始做多任務一般是做簡單的硬連接,后面到 MMOE,再到 SNR 或者 PLE,這些都是近年來業界比較成熟的方法。本團隊使用的是SNR,并且進行了兩個優化。下圖下半部分,最左邊是 SNR 標準 paper 的做法,我們把 expert 內部的 transformation 進行了簡化。同時會有獨享的專家和共享的專家,這里會根據一些實際業務中反饋的數據結論的實際值與估計偏差進行一些分析,做一些單獨的專家。

3、多場景技術
我們所負責的推薦場景比較多,很自然想到使用一些多場景的技術。多任務是有些目標比較稀疏,多場景是因為場景有大有小,小場景收斂的沒那么好,因為數據量不足,而大場景的收斂比較好,即使兩個場景都差不多大,中間也會有一些涉及到知識遷移會對業務有收益,這也是最近比較熱的方向,和多任務在技術上有很多相通的點。

基于每個多任務模型,都可以做多場景模型,相比于多任務結構,多加的是下圖中的 Slot-gate 層,相同的 Embedding 通過 Slot-gate 針對不同的場景表達不同的作用。通過 Slot-gate 的輸出可以分為三部分:連專家網絡、連進目標任務,或者連特征。

主模型主要是用 SNR 替換 CGC,跟多任務的迭代是一脈相成的。下面是當前多任務和多場景混合在一起,在熱點和熱門兩個內部業務場景下的應用。其中首頁推薦為熱門流,發現頁推薦為熱點流。
整體結構類似 SNR,上面為點擊、互動和時長三個目標塔。其中這三個目標塔針對熱門和熱點兩個場景,細分為六個目標。除外,增加了 Embeding transform layer,和 Slot-gate 不同的是,Slot-gate 是去找特征的重要性,而 Embeding transform layer 是考慮不同場景下 embedding 空間差異,去進行 embedding 映射。有些特征在兩個場景中維度不同,通過 Embedding transform layer 進行轉換。

4、興趣表征
興趣表征是這些年提的比較多的技術,從阿里的 DIN 到 SIM、DMT,已經成為業界用戶行為序列建模的主流。

一開始使用的 DIN,對不同行為,構建多個行為序列。引入 attention 機制給行為中不同物料予以不同權重,使用 local activation unit 來學習用戶序列與當前候選排序物料的權重分布,實現了熱門精排方案,并取得了一定的業務收益。
DMT 的核心是把 Transformer 用在 multitask 上,本團隊使用了簡化的 DMT 模型,移除了 bias 模塊,替換 MMoE 為 SNR,上線后也取得一定的業務效果。

Multi-DIN 是將多個序列展開,將候選物料的 mid,tag,authorid 等作為 query,分別對每個序列單獨做 attention 得到興趣表征后,拼接其他特征進入多任務排序模型。

同時我們也做了實驗發現,把序列拉的更長,比如將點擊、時長、互動序列等,每個序列從 20 擴到 50,效果更好,與 paper 中結論一致,不過序列更長需要更多的算力成本。

用戶生命周期超長序列建模和前面的長序列建模不同,不是通過請求特征就能拉到數據,而是離線構造用戶的長行為序列特征;或者是通過一些搜索的方式,找到對應的特征再去生成 embedding;或者是將主模型和超長序列模型分開建模,最終形成 embedding 送入主模型中。
在微博業務中,超長序列的價值沒有那么大,因為互聯網上大家的關注點變化較快,比如熱搜的東西,一兩天就逐漸淡忘了,信息流中七天前的東西,分發就比較少了。因此太長的用戶行為序列,對于預估用戶對 item 的偏好價值會有一定程度的減弱。但對于低頻或者說回流用戶來說,這個結論一定程度上是不同的。

5、特征
使用超大規模的模型,在特征層面也會有一些困擾。比如有的特征理論上覺得會對模型有幫助,但加入后的效果并不能達到預期,這也是推薦業務面臨的現實情況。因為模型規模非常大,模型中加了特別多 id 類的信息,已經對一些用戶偏好有了不錯的表達,這時再加一些統計上的特征,可能就沒那么好用,下面講下本團隊實踐中比較好用的特征。
首先匹配特征效果都是比較不錯的,用戶對于單個物料、單個內容類型、單個發博者建立一些比較詳細的統計數據,都能帶來一些收益。

另外,多模態的特征也是比較有價值的,因為整個推薦模型是基于用戶行為的,有一些低頻、冷門的 Item 在整個系統中用戶行為都是不足的,這時引入更多的先驗知識能帶來更多收益。多模態通過引入 NLP 等技術引入一批語義進來,對于低頻和冷啟動都是有幫助的。
本團隊做了兩種類型引入多模態特征的做法:第一種類型是把多模態 embedding 融合進推薦模型中,對底層這些 embedding 的梯度凍結,往上層的 MLP 再進行更新;另一種方法是利用多模態在進推薦模型之前先做聚類,把聚類的 id 扔進推薦的模型進行訓練,這對于推薦模型來講是更容易引進信息的方式,但也會丟失一些多模態具體的語義信息。
上面兩種方式,在我們的業務中都做了較多嘗試,第一種方法會帶來模型復雜度的提升,需要做很多空間變換,找特征重要性等,但能帶來不錯的收益;第二種方法使用聚類 id 去學習,復雜度都在模型之外,線上服務也比較簡單,效果也能達到 90% 左右,而且還可以對聚類 id 做一些統計性的特征,結合起來效果很好。

加入多模態特征后,收益比較大的是高質量的低曝光物料,能解決冷啟動問題。推薦那些曝光比較少的物料,模型無法充分學習的,會很依賴多模態體帶來更多信息,對業務生態也是有正向價值的。

Co-action 的動機是:嘗試 deepfm、wide deep 等多種特征交叉方式無果, 懷疑是交叉特征與 DNN 部分共享 embedding 沖突導致。Co-action 相當于加了存儲,單獨開辟存儲空間去做交叉,這里增加了表達空間,在業務中也拿到了不錯的收益。

三、鏈路表達一致性
這部分是關于粗排和召回的內容。對于推薦業務來講,雖然因為算力支持不了將幾百萬的候選集都用精排來排,而分成召回、粗排、精排幾部分,但邏輯上是在講同個問題。如下圖舉例,粗排是會做截斷的,最終給到精排的內容只有 1000 左右,如果粗排和精排的表達差異較大,在截斷的過程中很可能會把將來精排分比較高的內容截斷掉。精排和粗排的特征、模型結構都不一樣,粗排一般和召回的框架比較類似,是向量檢索的近似結構,特征會交叉比較晚,出現和精排模型表達差異是很自然的情況。如果能提升一致性,也會促進業務指標上漲,因為兩邊能抓住同樣的變化趨勢。

下圖展示了粗排一致性迭代過程中的技術脈絡,上面是雙塔的技術線,下面是 DNN 的技術線。由于雙塔的特征交互較晚,所以加了很多雙塔特征交叉的方式。但向量檢索的方式天花板有點太低了,所以從 2022 年開始,會有 DNN 分支來做粗排,這對于工程架構的壓力比較大,比如要做特征篩選,網絡剪枝,性能優化等,而且一次性打分的條數也會較之前有減少,但打的分更好了,因此條數變少也是可以接受的。

DSSM-autowide 是基于雙塔做了類似 Deep-FM 的交叉,帶來了業務指標上的增幅,但下一個項目,換新的交叉方式,提升就沒有那么顯著了。

因此,我們覺得基于雙塔能做出的收益是比較有限的。我們還嘗試了基于雙塔做的多任務粗排模型,但還是繞不過雙塔問題。

基于上述問題,本團隊對粗排模型進行優化,使用 DNN 和級聯模型做 Stacking 架構。
級聯模型可以用雙塔先做一層篩選,篩選之后再過濾截斷給粗排的 DNN 模型,相當于在粗排這里內部做了粗排和精排。換成 DNN 模型后,能支持更復雜的結構,更快擬合用戶興趣變化等。

級聯在框架中起了比較重要的作用,如果沒有級聯模型的話,不太能從比較大的候選集中選出小候選集去給粗排的 DNN 來使用。級聯中比較重要的是怎么構造樣本,可以看下圖。從百萬級的物料庫,召回幾千粗排,給精排 1000 內的物料,最后曝光的是 20 條左右,用戶有行為的是個位數條數,整體是從更大的庫走到用戶有行為的漏斗過程。在做級聯的時候,核心點是每個部分都要進行一些采樣,組成一些比較難的 pair 和比較簡單的 pair,來給級聯模型學習。

下圖是級聯優化和全局負采樣帶來的收益,這里不做詳細介紹。

接下來介紹近期比較火熱的因果推斷。
我們使用因果推斷的動機是,給用戶推的東西,如果推所有人都喜歡的東西,用戶點擊效果也不錯,但用戶自己也有一些比較小眾的興趣,給用戶推這些小眾的物料,用戶也比較喜歡。這兩種東西對于用戶來講是一樣的,但對平臺來講,能推出來更小眾的東西是更個性化的,而模型更容易推出來的是第一種,因果推斷就是來解決這種問題的。
具體的做法是去組 pairwise 樣本對,對用戶點擊且流行度低的物料,和流行度高但用戶未點擊的物料,用貝葉斯的方法做 loss 訓練模型。
在我們的實踐中,因果推斷在粗排和召回階段來做比在精排做更容易獲得收益。原因是精排模型比較復雜,精排已經有不錯的個性化能力,但粗排和召回即使用了 DNN,也是裁剪的 DNN,整個模型的個性化能力還是有差距的,在個性化能力比較差的地方使用因果推斷效果肯定比在個性化能力強的地方使用效果更明顯。

四、其他技術點
1、序列重排
重排是采用 beam-search 方法,設計結合 NEXT 下拉模型的 reward 函數,生成多種候選序列,選取最大收益的序列,擴量后效果不穩定,細節進一步優化中。

2、圖技術
圖技術主要包括兩部分:圖數據庫和圖 embedding。對于推薦來講,如果用圖數據庫,會更方便一些,成本更低。圖 embedding 指的是游走類的節點隨機游走,將圖數據(通常為高維稠密的矩陣)映射為低維稠密向量的過程。圖嵌入需要捕捉到圖的拓撲結構,頂點與頂點的關系,以及其他的信息(如子圖,連邊等),在此不展開介紹。

推薦中可以用基于隨機游走、圖結構、圖對比學習等算法,做用戶與博文、用戶與作者的互動/關注等召回。主流的方式還是把圖文、用戶等做成 embedding,給模型加特征,也有一些比較前沿的嘗試方式,如直接做端到端網絡,用 GNN 來做推薦。

下圖是目前端到端的模型,目前我們還在嘗試中,不是線上的主流量版本。

下圖是基于圖網絡生成 embedding,右邊的圖是根據賬號的領域算出的相似度。對于微博來講, 根據關注關系算出 embedding 是有收益的。

五、問答環節
Q1:對推薦信息流很多 Item 只瀏覽不點擊,是怎么區分是否感興趣的呢?通過列表頁上 Item 的停留時間嗎?
A1:對的,信息流業務來講話,時長是比較重要的優化指標。做時長的優化指標,不太方便直接優化用戶今天整體在 APP 上停留多久,優化比較多的還是在 item 停留多久。不把時長當作優化目標來做,就比較容易推很多淺消費的內容。
Q2:訓練發生 fail over 模型實時更新會有一致性問題嗎?模型的一致性問題如何處理?
A2: 當前對于推薦的學習訓練來講,如果是 cpu 的話異步式的比較多,大家不太做成那種全局有個輪次,等輪次結束之后統一收集完,更新到 ps 上,再發起下輪次,因為性能問題,大家基本不會這樣做。無論是不是實時、在線學習,都達不到強一致性。
如果你訓練發生 fail over 的話,如果流式訓練的話,是記錄在數據流上,比如 kafka 或者是 flink 上,去記載你當前方案訓練到哪的位置的,你的 ps 上也有你上次訓練完的記錄,也就跟全局的差異是差不多的。
Q3:請問召回使用精排的序會不會降低召回模型迭代上限?
A3:迭代上限姑且理解為召回的天花板,那我理解召回的天花板肯定不是要超越精排,舉例來說,如果算力現在是無窮的話,那用精排打 500 萬物料的分是不是對業務最好的處理方式。那召回在投入不那么大的情況下,盡量把精排覺得最好的部分給他找出來,比如說讓他從召回里面那 6000 里面選出的 top15 和在 500 萬的 top15 是比較接近的,召回模塊做的就比較好了。如果大家這么理解的話,那召回使用精排的序不會降低迭代上線,反而是向著上限前進。不過這也是我們一家之言,大家根據自己的業務導向,可能結論不一定是放之四海而皆準的。