如何通過提示工程訓(xùn)練您的聊天機器人?
譯文譯者 | 布加迪
審校 | 重樓
近幾個月來基于人工智能(AI)的聊天機器人風(fēng)靡全球,一個原因是它們可以為各種用途生成或完善文本,無論策劃廣告活動還是撰寫簡歷。

這些聊天機器人基于大型語言模型(LLM)算法,算法可以模仿人類智能,創(chuàng)建文本內(nèi)容以及音頻、視頻、圖像和計算機代碼。LLM是一種AI,接受大量文章、書籍或網(wǎng)上資源及其他輸入的訓(xùn)練,對自然語言輸入給出類似人類的答復(fù)。
越來越多的科技公司已推出了基于LLM的生成式AI工具,用于企業(yè)自動化處理應(yīng)用任務(wù)。比如,微軟上周向數(shù)量有限的用戶推出了一款基于OpenAI的ChatGPT的聊天機器人,它嵌入在Microsoft 365中,可以自動化執(zhí)行CRM和ERP應(yīng)用軟件的功能。
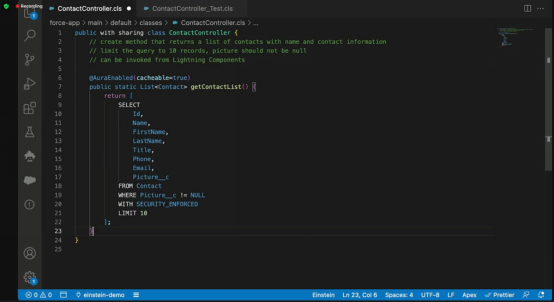
圖1. 生成式AI通過用戶提示創(chuàng)建軟件代碼的示例。在這個例子中,Salesforce的Einstein聊天機器人通過使用OpenAI的GPT-3.5大型語言模型被啟用
比如說,新的Microsoft 365 Copilot可以在Word中用來創(chuàng)建文檔的初稿,可能會節(jié)省數(shù)小時的撰寫、溯源和編輯時間。Salesforce還宣布計劃發(fā)布一個基于GPT的聊天機器人,用于與其CRM平臺結(jié)合使用。
OpenAI的GPT-4等大多數(shù)LLM都被預(yù)先訓(xùn)練成預(yù)測下一個單詞或內(nèi)容的引擎,這是大多數(shù)企業(yè)使用它們的方式,即所謂的“開箱即用”。雖然基于LLM的聊天機器人也會出現(xiàn)一些錯誤,但經(jīng)過預(yù)先訓(xùn)練的LLM比較擅長饋送總體上準(zhǔn)確和引人注目的內(nèi)容,這些內(nèi)容至少可以作為起點。
然而,許多行業(yè)需要更多定制的LLM算法,能理解他們的行話,并生成針對用戶的內(nèi)容。比如說,面向醫(yī)療保健行業(yè)的LLM可能需要處理和解釋電子健康記錄(EHR),建議治療方案,或根據(jù)醫(yī)生筆記或語音記錄創(chuàng)建患者醫(yī)療保健摘要。面向金融服務(wù)行業(yè)的LLM可以總結(jié)收益電話會議、創(chuàng)建會議文字記錄,并執(zhí)行欺詐分析以保護消費者。
綜觀眾多行業(yè),確保答復(fù)有很高的準(zhǔn)確性至關(guān)重要。
大多數(shù)LLM都可以通過應(yīng)用編程接口(API)來訪問,該接口允許用戶創(chuàng)建參數(shù)或者調(diào)整LLM的答復(fù)方式。發(fā)送給聊天機器人的問題或請求就叫提示(prompt),原因在于用戶提示答復(fù)。提示可以是自然語言問題、代碼片段或命令,但若要LMM準(zhǔn)確地完成工作,提示必須切題。
而這種必要性已催生了一種新的技能:提示工程。
提示工程詳解
提示工程是指制作和優(yōu)化文本提示,以便大型語言模型達到預(yù)期結(jié)果的方法。SambaNova Systems是一家生產(chǎn)AI半導(dǎo)體的硅谷初創(chuàng)公司,該公司產(chǎn)品高級副總裁Marshall Choy表示:“提示工程幫助LLM實現(xiàn)產(chǎn)品原型和探索的快速迭代,因為它可以定制LLM,以便快速輕松地與任務(wù)定義保持一致。”
Hugging Face是一個創(chuàng)建和托管LLM的社區(qū)驅(qū)動平臺,該平臺的機器學(xué)習(xí)工程師Eno Reyes表示,可能對用戶來說同樣重要的是,提示工程有望成為IT和商業(yè)專業(yè)人士的一項重要技能。
Reyes在回復(fù)美國《計算機世界》雜志的郵件中說:“我認(rèn)識的很多從事軟件、IT和咨詢業(yè)的人一直將提示工程用于個人工作。隨著LLM日益融入到眾多行業(yè),它們大有提高生產(chǎn)力的潛力。”
Reyes表示,如果有效地運用提示工程,企業(yè)用戶可以優(yōu)化LLM,更高效準(zhǔn)確地執(zhí)行從客戶支持、內(nèi)容生成到數(shù)據(jù)分析的特定任務(wù)。
目前最有名的LLM:OpenAI的GPT-3是廣受歡迎的ChatGPT聊天機器人的基礎(chǔ)。GPT-3 LLM工作在一個1750億參數(shù)的模型上,可以用簡短的書面提示生成文本和計算機代碼。OpenAI的最新版本GPT-4估計有多達2800億個參數(shù),因而極有可能給出正確的答復(fù)。
除了OpenAI的GPT LLM外,流行的生成式AI平臺還包括一些開放模型,比如Hugging Face的BLOOM和XLM-RoBERTa、英偉達的NeMO LLM、XLNet、和GLM-130B。
由于提示工程是一門新興的學(xué)科,企業(yè)依靠小冊子和提示指南來確保其AI應(yīng)用程序有最佳答復(fù)。甚至出現(xiàn)了新興的提示市場平臺,比如ChatGPT的100個最佳提示(https://beebom.com/best-chatgpt-prompts/)。
Gartner Research的杰出副總裁分析師Arun Chandrasekaran說:“有人甚至在出售提示建議。”他補充道,最近對生成式AI的大量關(guān)注突顯了市場需要更好的提示工程。
他說:“這是一個比較新的領(lǐng)域。生成式AI應(yīng)用常常依賴自我監(jiān)督的大型AI模型,因此從它們那里獲得最佳答復(fù)需要更多的專業(yè)知識、試驗和額外的努力。我確信,隨著技術(shù)日趨成熟,我們可能會從AI模型創(chuàng)建者那里得到更好的指導(dǎo)和最佳實踐,以便有效地發(fā)揮AI模型和應(yīng)用軟件的最大功效。”
好的輸出來自好的輸入
LLM的機器學(xué)習(xí)組件自動從數(shù)據(jù)輸入中學(xué)習(xí)。除了最初用于創(chuàng)建GPT-4等LLM的數(shù)據(jù)外,OpenAI還創(chuàng)建了名為強化學(xué)習(xí)人類反饋(RLHF)的機制,人訓(xùn)練模型如何給出類似人類的答復(fù)。
比如說,用戶向LLM提出問題,然后寫出理想的答案。隨后用戶再次向模型提出同樣的問題,模型會提供其他許多不同的回答。如果這是基于事實的問題,我們希望答案保持不變;如果這是開放式問題,目的是給出多個類似人類的創(chuàng)造性答復(fù)。
比如說,如果用戶讓ChatGPT生成一首關(guān)于一個人待在夏威夷海灘上的詩,就會期望它每次生成一首不同的詩。Chandrasekaran說:“因此,訓(xùn)練人員所做的就是將答復(fù)從最好到最差進行評分。這是饋給模型的輸入,以確保它給出更像人類或最佳的答復(fù),同時試圖盡量減少最糟糕的答復(fù)。但您提問題的方式對于從模型得到的輸出有很大影響。”
組織可以通過攝取公司內(nèi)部的自定義數(shù)據(jù)集來訓(xùn)練GPT模型。比如說,它們拿來企業(yè)數(shù)據(jù)后可以進行標(biāo)記和注釋,以提高數(shù)據(jù)質(zhì)量,然后饋入到GPT-4模型中。這需要對模型進行微調(diào),以便它能夠回答該組織所特有的問題。
也可以針對特定行業(yè)進行微調(diào)。已經(jīng)出現(xiàn)了一批新興初創(chuàng)企業(yè),它們使用GPT-4,攝取金融服務(wù)等垂直行業(yè)所特有的大量信息。
Chandrasekaran說:“它們可能會攝取Lexus-Nexus和彭博社的信息,可能攝取證券交易委員會(SEC)的信息,比如8K和10K報告。但關(guān)鍵是,模型在學(xué)習(xí)該領(lǐng)域所特有的大量語言或信息。因此,微調(diào)可能在行業(yè)層面或組織層面進行。”
比如說,Harvey是一家與OpenAI合作的初創(chuàng)公司,為法律專業(yè)人士創(chuàng)建所謂的“律師領(lǐng)航員”或ChatGPT版本。律師可以使用定制的ChatGPT聊天機器人來查找任何法律判例,以便某些法官為下一個案子做準(zhǔn)備。
Chandrasekaran說:“我認(rèn)為出售提示的價值與其說在語言上,不如說在圖像上。生成式AI領(lǐng)域有各種各樣的模型,包括文本轉(zhuǎn)換成圖像的模型。”
比如說,用戶可以要求生成式AI模型生成吉他手在月球上彈奏的圖像。Chandrasekaran 說:“我認(rèn)為文本轉(zhuǎn)換成圖像的模型這個領(lǐng)域在提示市場更受重視。”
Hugging Face作為一站式LLM中心
雖然Hugging Face創(chuàng)建了一些自己的LLM,包括BLOOM,但該組織的主要角色是充當(dāng)第三方機器學(xué)習(xí)模型的中心,就像代碼界的GitHub那樣。Hugging Face目前擁有超過10萬個機器學(xué)習(xí)模型,包括來自初創(chuàng)公司和科技巨頭的眾多LLM。
由于新模型是開源的,它們通常在該中心上向公眾開放,為新興的開源LLM創(chuàng)建了一站式目的地。
要使用Hugging Face為特定的公司或行業(yè)對LLM進行微調(diào),用戶可以利用該組織的“Transformers”API和“Datasets”庫。比如說,在金融服務(wù)業(yè),用戶可以導(dǎo)入預(yù)先訓(xùn)練好的LLM(比如Flan-UL2),加載金融新聞文章數(shù)據(jù)集,然后使用“Transformer”訓(xùn)練器對模型進行微調(diào),以生成這些文章的摘要。與AWS、DeepSpeed和Accelerate的集成進一步簡化和優(yōu)化了訓(xùn)練。
據(jù)Reyes聲稱,整個過程可以用不到100行代碼來完成。
另一種開始入手提示工程的方法需要用到Hugging Face的Inference API。據(jù)Reyes聲稱,這是一個簡單的HTTP請求端點,支持80000多個Transformer模型。Reyes說:“這個API允許用戶發(fā)送文本提示,并接收來自我們平臺上的開源模型(包括LLM)的答復(fù)。如果您還想更簡單一點,可以通過使用Hugging Face中心的LLM模型上的推理窗口組件實際發(fā)送文本,無需代碼。”
少樣本和零樣本學(xué)習(xí)
LLM提示工程通常有兩種形式:少樣本學(xué)習(xí)和零樣本學(xué)習(xí)或訓(xùn)練。
零樣本學(xué)習(xí)需要輸入簡單的指令作為提示,以便從LLM生成預(yù)期的響應(yīng)。其目的是教LLM執(zhí)行新的任務(wù),而不使用這些特定任務(wù)的已標(biāo)記數(shù)據(jù)。零樣本學(xué)習(xí)好比是強化學(xué)習(xí)。
反過來,少樣本學(xué)習(xí)使用少量的樣本信息或數(shù)據(jù)來訓(xùn)練LLM以獲得所需的響應(yīng)。少樣本學(xué)習(xí)主要由三個部分組成:
- 任務(wù)描述:簡短地描述模型應(yīng)該做什么事,比如“把英語翻譯成法語”。
- 例子:幾個例子向模型表明了期望它做什么事,比如說“sea otter => loutre de mer”。
- 提示:新例子的開頭,模型應(yīng)該通過生成缺失的文本來完成該例子,比如:“cheese =>”。
據(jù)Gartner的Chandrasekaran聲稱,實際上,目前很少有組織擁有定制的訓(xùn)練模型來滿足其需求,因為大多數(shù)模型仍處于開發(fā)的早期階段。雖然少樣本和零樣本學(xué)習(xí)有所幫助,但學(xué)習(xí)提示工程這種技能很重要,對IT用戶和業(yè)務(wù)用戶來說都很重要。
Chandrasekaran說:“提示工程是如今應(yīng)該擁有的一項重要技能,因為基礎(chǔ)模型擅長少樣本和零樣本學(xué)習(xí),但它們的性能或表現(xiàn)在很多方面受到我們?nèi)绾斡袟l不紊地設(shè)計提示的影響。這些技能對IT用戶和業(yè)務(wù)用戶都很重要,具體視用例和領(lǐng)域而定。”
大多數(shù)API允許用戶運用自己的提示工程技術(shù)。據(jù)Reyes聲稱,每當(dāng)用戶向LLM發(fā)送文本,都有機會完善提示以實現(xiàn)特定的結(jié)果。
Reyes說:“然而,這種靈活性也為惡意用例打開了大門,比如提示注入。像微軟必應(yīng)的Sydney這樣的事件表明,人們可以利用提示工程實現(xiàn)意想不到的用途。作為一個新興的研究領(lǐng)域,解決惡意用例和紅隊滲透測試中的提示注入對未來至關(guān)重要,可確保在各種應(yīng)用場合下負(fù)責(zé)任、安全地使用LLM。”
原文標(biāo)題:How to train your chatbot through prompt engineering,作者:Lucas Mearian