人人都懂ChatGPT第一章:ChatGPT 與自然語言處理

ChatGPT(Chat Generative Pre-training Transformer) 是一個 AI 模型,屬于自然語言處理( Natural Language Processing , NLP ) 領域,NLP 是人工智能的一個分支。所謂自然語言,就是人們日常生活中
接觸和使用的英語、漢語、德語等等。自然語言處理是指,讓計算機來理解并正確地操作自然語言,完成人類指定的任務。NLP 中常見的任務包括文本中的關鍵詞抽取、文本分類、機器翻譯等等。
NLP 當中還有一個非常難的任務:對話系統,也可被籠統稱為聊天機器人,正是 ChatGPT 所完成的工作。
ChatGPT 與圖靈測試
自從 1950 年代出現計算機以來,人們就已經開始著手研究讓計算機輔助人類理解、處理自然語言,這也是 NLP 這一領域的發展目標,最著名的當屬圖靈測試。
1950年,計算機之父——艾倫·圖靈(Alan Turing)介紹了一項測試,以檢查機器是否能像人類一樣思考,這項測試稱為圖靈測試。它具體的測試方法和目前 ChatGPT 的方式一模一樣,即構建一個計算機對話系統,一個人和被測試的模型互相進行對話,如果這個人無法辨別對方究竟是機器模型還是另一個人,就說明該模型通過了圖靈測試,計算機是智能的。
長久以來,圖靈測試都被學界認為是難以攀登的巔峰。正因如此,NLP 也被稱為人工智能皇冠上的明珠。而 ChatGPT 所能夠做的工作,已經遠遠超出了聊天機器人這個范疇,它能夠根據用戶的指令寫文章,回答技術問題,做數學題,做外文翻譯,玩文字游戲等等。所以,某種程度上,ChatGPT 已經摘下了這顆皇冠上的明珠。
ChatGPT 的建模形式
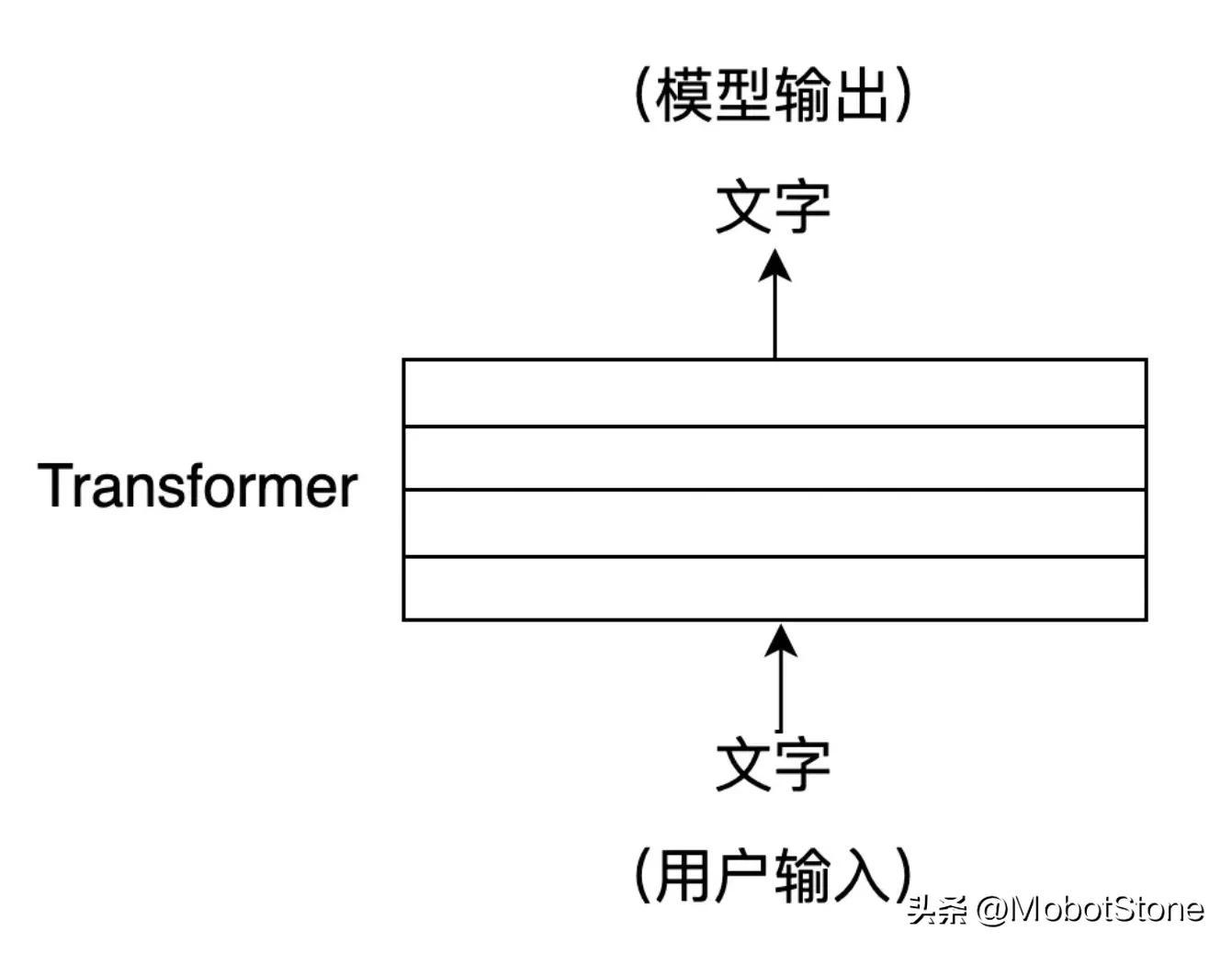
ChatGPT 的工作形式非常簡單,用戶向 ChatGPT 提問任何一個問題,模型都會做出解答。

其中,用戶的輸入和模型的輸出都是文字形式。一次用戶輸入和一次模型對應的輸出,叫做一輪對話。我們可以把 ChatGPT 的模型抽象成如下流程:

此外,ChatGPT 也可以回答用戶的連續提問,也就是多輪對話,多輪對話之間是有信息關聯的。其具體的形式也非常簡單,第二次用戶輸入時,系統默認把第一次的輸入、輸出信息都拼接在一起,供 ChatGPT 參考上次對話的信息。
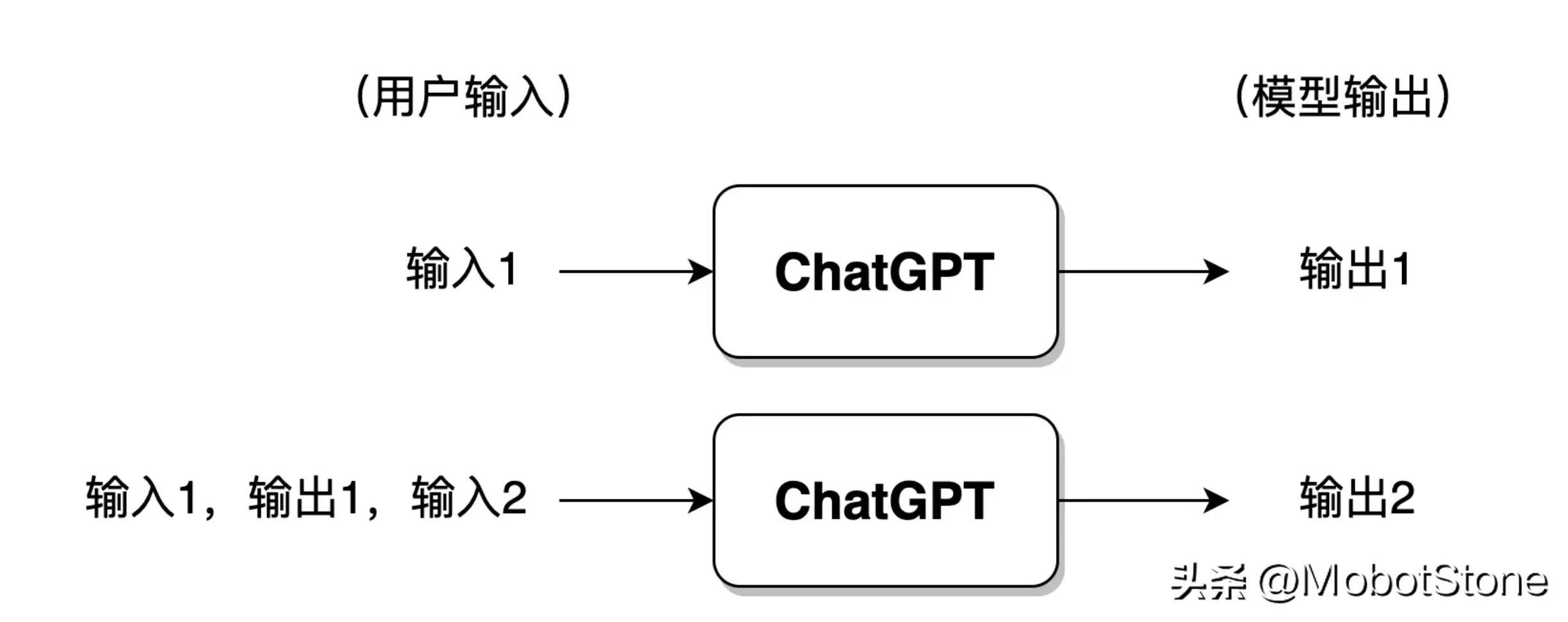
如果用戶與 ChatGPT 對話的輪次過多,一般來講模型僅會保留最近幾輪對話的信息,此前的對話信息將被遺忘。
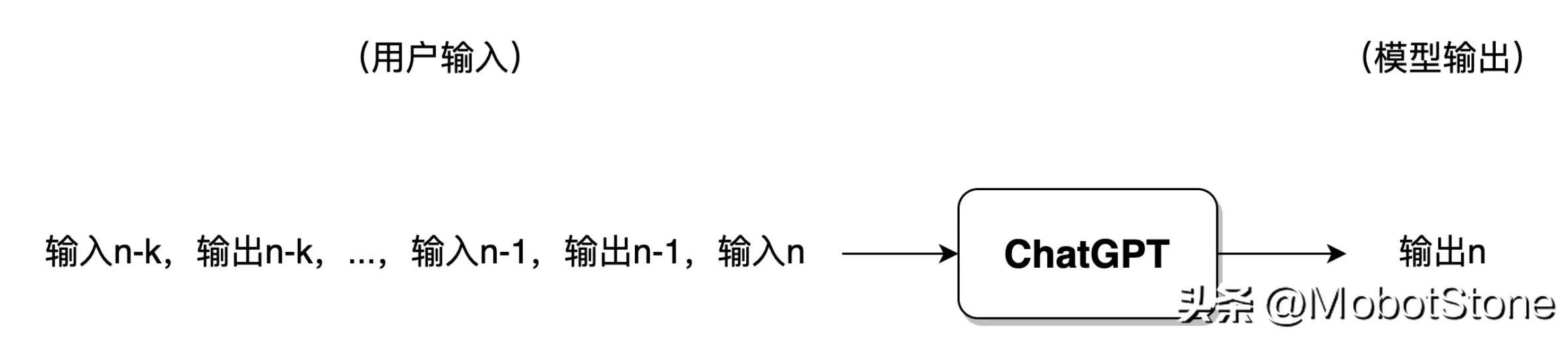
ChatGPT 在接收到用戶的提問輸入后,輸出的文字并不是一口氣直接生成的,而是一個字、一個字生成的,這種逐字生成,即生成式(Generative) 。如下圖所示。
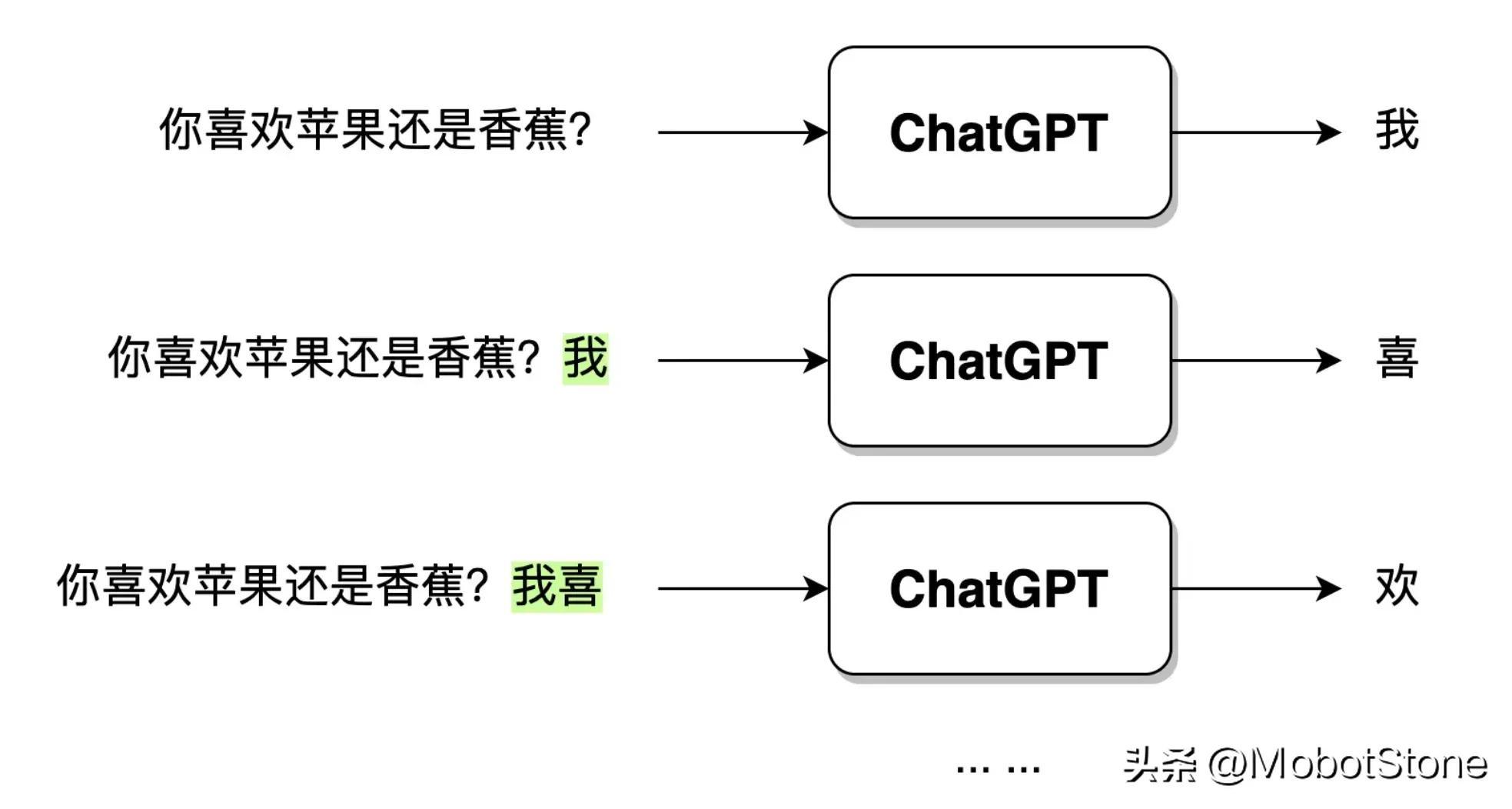
當用戶輸入問句:“你喜歡蘋果還是香蕉?”,ChatGPT 接收到數據之后,首先會生成一個“我”字,然后,模型會綜合用戶的問句和生成的“我”字,繼續生成下一個字“喜”。以此類推,直到生成一個完整的句子“我喜歡蘋果。”。
ChatGPT 與 NLP 的發展歷程
前面介紹了 ChatGPT 的建模形式,可以試想一下,如果讓你來實現一個 ChatGPT 模型,有哪些思路和方法呢?事實上,大致有兩種策略,基于規則的 NLP 和基于統計的 NLP。自從 ChatGPT 開始,NLP 領域又進入了強化學習時代,即基于強化學習的 NLP。
基于規則的 NLP
基于規則的 NLP,是指使用人工編寫的規則來處理自然語言。這些規則通常基于語法、語義和語用等方面的知識,可以用來解析和生成自然語言。例如,我們可以基于以下規則設計一個對話系統:
規則 1:當模型接收到用戶的問句后,把問句中的“嗎”字去掉,“?”換成“。”
規則 2:把“你”換成“我”,“我”字換成“你”
由此,我們可以根據這些規則,制作一個對話模型,開啟對話模式了。
用戶:Hello。 模型:Hello。 用戶:你是 ChatGPT嗎? 模型:我是 ChatGPT。 用戶:你喜歡掘金社區嗎? 模型:我喜歡掘金社區。 用戶:你用過 jionlp 軟件工具包嗎? 模型:我用過 jionlp 軟件工具包。
以上是一個基于規則的非常粗淺的對話系統示例。其中存在的問題,相信讀者能夠很容易找出來。如果用戶問題太復雜了怎么辦?問題中沒有加問號怎么辦?我們需要不斷編寫出各種規則來覆蓋上面的特殊情況。這說明基于規則存在幾個明顯的缺點:
- 在自然語言中,任何規則都無法完全覆蓋需求,因此在處理復雜的自然語言任務時效果不佳;
- 規則無窮無盡,靠人力來完成將是一項天量的工作;
- 本質上并沒有把自然語言處理的任務交給計算機來完成,依然是人在主導。
這就是 NLP 發展早期的方式方法:基于規則完成模型系統構建。在早期,一般也被稱為符號主義。
基于統計的 NLP
基于統計的 NLP 則是利用機器學習算法從大量的語料庫中學習自然語言的規律特征,在早期也被稱為連接主義。這種方法不需要人工編寫規則,規則主要通過學習語言的統計特征,暗含在模型中。換句話說,基于規則的方法中,規則是顯性的,人工編寫的;基于統計的方法中,規則是隱形的,暗含在模型參數中,由模型根據數據訓練得到。
這些模型,在近年來發展迅速,ChatGPT 就是其中一種。除此之外,還有各式各樣不同形態構造的模型,其根基原理是相同的。它們的處理方式主要如下:
訓練模型 => 利用已訓練好的模型進行工作
在 ChatGPT 中,主要采用預訓練( Pre-training ) 技術來完成基于統計的 NLP 模型學習。最早,NLP 領域的預訓練是由 ELMO 模型(Embedding from Language Models)首次引進的,后續 ChatGPT 等各種深度神經網絡模型廣泛采用了這種方式。
它的重點在于,根據大規模原始語料學習一個語言模型,而這個模型并不直接學習如何解決具體的某種任務,而是學習從語法、詞法、語用,到常識、知識等信息,把它們融匯在語言模型中。直觀地講,它更像是一個知識記憶器,而非運用知識解決實際問題。
預訓練的好處很多,它已經成為了幾乎所有 NLP 模型訓練的必備步驟。我們將在后續章節展開講。
基于統計的方法遠遠比基于規則的方法受歡迎,然而它最大的缺點是黑盒不確定性,即規則是隱形的,暗含在參數中。例如,ChatGPT 也會給出一些模棱兩可、不知所云的結果,我們無從依照結果來判斷模型為什么給出這樣的答案。

基于強化學習的 NLP
ChatGPT 模型是基于統計的,然而它又利用了新的方法,帶人工反饋的強化學習(Reinforcement Learning with Human Feedback,RLHF) ,以此取得了卓越的效果,把 NLP 的發展帶入了一個新階段。
幾年前,Alpha GO 擊敗了柯潔。這幾乎可以說明,強化學習如果在適合的條件下,完全可以打敗人類,逼近完美的極限。當前,我們依然處在弱人工智能時代,但局限于圍棋這個領域,Alpha GO 就是一個強人工智能,它的核心就在于強化學習 。
所謂強化學習,就是一種機器學習的方法,旨在讓智能體(agent,在 NLP 中主要指深度神經網絡模型,就是 ChatGPT 模型)通過與環境的交互來學習如何做出最優決策。
這種方式就像是訓練一只狗(智能體)聽哨聲(環境)進食(學習目標)。
一只小狗,當聽到主人吹哨后,就會被獎勵食物;而當主人不吹哨時,小狗只能挨餓。通過反復的進食、挨餓,小狗就能建立起相應的條件反射,實際上就是完成了一次強化學習。
而在 NLP 領域,這里的環境要復雜得多。針對 NLP 模型的環境并非真正的人類語言環境,而是人為構造出來的一種語言環境模型。因此,這里強調是帶人工反饋的強化學習。

基于統計的方式能夠讓模型以最大自由度去擬合訓練數據集;而強化學習就是賦予模型更大的自由度,讓模型能夠自主學習,突破既定的數據集限制。ChatGPT 模型是融合統計學習方法和強化學習方法的,它的模型訓練流程如下圖所示:

這部分訓練流程將在第 8-11 節展開講。
NLP 技術的發展脈絡
實際上,基于規則、基于統計、基于強化學習 這 三種方式,并不僅僅是一種處理自然語言的手段,而是一種思想。一個解決某一問題的算法模型,往往是融合了這三種解決思想的產物。
如果把計算機比作一個小孩,自然語言處理就像是由人類來教育小孩成長。
基于規則的方式,就好比家長 100% 控制小孩,要求他按照自己的指令和規則行事,如每天規定學習幾小時,教會小孩每一道題。整個過程,強調的是手把手教,主動權和重心都在家長身上。對于 NLP 而言,整個過程的主動權和重心,都在編寫語言規則的程序員、研究員身上。
基于統計的方式,就好比家長只告訴小孩學習方法,而不教授具體每一道題,強調的是半引導。對于 NLP 而言,學習重心放在神經網絡模型上,但主動權仍由算法工程師控制。
基于強化學習的方式,則好比家長只對小孩制定了教育目標,比如,要求小孩能夠考試達到 90 分,但并不去管小孩他是如何學習的,全靠自學完成,小孩擁有極高的自由度和主動權。家長只對最終結果做出相應的_獎勵或懲罰_,不參與整個教育過程。對于 NLP 來說,整個過程的重心和主動權都在于模型本身。
NLP 的發展一直以來都在逐漸向基于統計的方式靠攏,最終由基于強化學習的方式取得完全的勝利,勝利的標志,即 ChatGPT 的問世;而基于規則方式逐漸式微,淪為了一種輔助式的處理手段。ChatGPT 模型的發展,從一開始,就在堅定不移地沿著讓模型自學的方向發展進步著。
ChatGPT 的神經網絡結構 Transformer
前面的介紹中,為了方便讀者理解,沒有提 ChatGPT 模型內部的具體構造。
ChatGPT 是一個大型的神經網絡,其內部結構是由若干層 Transformer 構成的,Transformer 是一種神經網絡的結構。自從 2018 年開始,它就已經成為了 NLP 領域的一種通用的標準模型結構,Transformer 幾乎遍布各種 NLP 模型之中。
如果說,ChatGPT 是一幢房子的話,那么,Transformer 就是構建 ChatGPT 的磚頭。
Transformer 的核心是自注意力機制(Self-Attention),它可以幫助模型在處理輸入的文字序列時,自動地關注到與當前位置字符相關的其他位置字符。自注意力機制可以將輸入序列中的每個位置都表示為一個向量,這些向量可以同時參與計算,從而實現高效的并行計算。舉一個例子:
在機器翻譯中,在將英文句子 "I am a good student" 翻譯成中文時,傳統的機器翻譯模型可能會將其翻譯成 "我是一個好學生",但是這個翻譯結果可能不夠準確。英文中的冠詞“a”,在翻譯為中文時,需要結合上下文才能確定。
而使用 Transformer 模型進行翻譯時,可以得到更加準確的翻譯結果,例如 "我是一名好學生"。
這是因為 Transformer 能夠更好地捕捉英文句子中,跨越很長距離的詞匯之間的關系,解決文本上下文的長依賴。自注意力機制將在第 5-6 節展開介紹,Transformer 結構詳解將在第 6-7 節展開介紹。
總結
- NLP 領域的發展逐漸由人為編寫規則、邏輯控制計算機程序,到完全交由網絡模型去適應語言環境。
- ChatGPT 是目前最接近通過圖靈測試的 NLP 模型,未來GPT4、GPT5將會更加接近。
- ChatGPT 的工作流程是一個生成式的對話系統。
- ChatGPT 的訓練過程包括語言模型的預訓練,RLHF 帶人工反饋的強化學習。
- ChatGPT 的模型結構采用以自注意力機制為核心的 Transformer。