Web 端實時防擋臉彈幕(基于機器學習)
防擋臉彈幕,即大量彈幕飄過,但不會遮擋視頻畫面中的人物,看起來像是從人物背后飄過去的。
機器學習已經火了好幾年了,但很多人都不知道瀏覽器中也能運行這些能力;
本文介紹在視頻彈幕方面的實踐優化過程,文末列舉了一些本方案可適用的場景,期望能開啟一些腦洞。
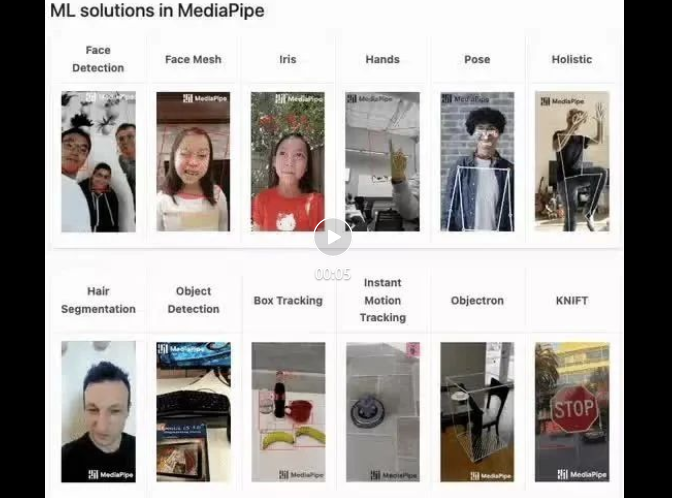
mediapipe Demo(https://google.github.io/mediapipe/)展示
主流防擋臉彈幕實現原理
點播
up 上傳視頻
服務器后臺計算提取視頻畫面中的人像區域,轉換成 svg 存儲
客戶端播放視頻的同時,從服務器下載 svg 與彈幕合成,人像區域不顯示彈幕
直播
- 主播推流時,實時(主播設備)從畫面提取人像區域,轉換成 svg
- 將 svg 數據合并到視頻流中(SEI),推流至服務器
- 客戶端播放視頻同時,從視頻流中(SEI)解析出 svg
- 將 svg 與彈幕合成,人像區域不顯示彈幕
本文實現方案
客戶端播放視頻同時,實時從畫面提取人像區域信息,將人像區域信息導出成圖片與彈幕合成,人像區域不顯示彈幕。
實現原理
- 采用機器學習開源庫從視頻畫面實時提取人像輪廓,如Body Segmentation(https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/README.md)
- 將人像輪廓轉導出為圖片,設置彈幕層的 mask-image(https://developer.mozilla.org/zh-CN/docs/Web/CSS/mask-image)
對比傳統(直播SEI實時)方案
優點:
- 易于實現;只需要Video標簽一個參數,無需多端協同配合
- 無網絡帶寬消耗
缺點:
- 理論性能極限劣于傳統方案;相當于性能資源換網絡資源
面臨的問題
眾所周知“JS 性能太辣雞”,不適合執行 CPU 密集型任務。由官方demo變成工程實踐,最大的挑戰就是——性能。
本次實踐最終將 CPU 占用優化到 5% 左右(2020 M1 Macbook),達到生產可用狀態。
實踐調優過程
選擇機器學習模型
BodyPix (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/src/body_pix/README.md)
精確度太差,面部偏窄,有很明顯的彈幕與人物面部邊緣重疊現象

BlazePose(https://github.com/tensorflow/tfjs-models/blob/master/pose-detection/src/blazepose_mediapipe/README.md)
精確度優秀,且提供了肢體點位信息,但性能較差

返回數據結構示例
[
{
score: 0.8,
keypoints: [
{x: 230, y: 220, score: 0.9, score: 0.99, name: "nose"},
{x: 212, y: 190, score: 0.8, score: 0.91, name: "left_eye"},
...
],
keypoints3D: [
{x: 0.65, y: 0.11, z: 0.05, score: 0.99, name: "nose"},
...
],
segmentation: {
maskValueToLabel: (maskValue: number) => { return 'person' },
mask: {
toCanvasImageSource(): ...
toImageData(): ...
toTensor(): ...
getUnderlyingType(): ...
}
}
}
]MediaPipe SelfieSegmentation (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/src/selfie_segmentation_mediapipe/README.md)
精確度優秀(跟 BlazePose 模型效果一致),CPU 占用相對 BlazePose 模型降低 15% 左右,性能取勝,但返回數據中不提供肢體點位信息
返回數據結構示例
{
maskValueToLabel: (maskValue: number) => { return 'person' },
mask: {
toCanvasImageSource(): ...
toImageData(): ...
toTensor(): ...
getUnderlyingType(): ...
}
}初版實現
參考 MediaPipe SelfieSegmentation 模型 官方實現(https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/README.md#bodysegmentationdrawmask),未做優化的情況下 CPU 占用 70% 左右
const canvas = document.createElement('canvas')
canvas.width = videoEl.videoWidth
canvas.height = videoEl.videoHeight
async function detect (): Promise<void> {
const segmentation = await segmenter.segmentPeople(videoEl)
const foregroundColor = { r: 0, g: 0, b: 0, a: 0 }
const backgroundColor = { r: 0, g: 0, b: 0, a: 255 }
const mask = await toBinaryMask(segmentation, foregroundColor, backgroundColor)
await drawMask(canvas, canvas, mask, 1, 9)
// 導出Mask圖片,需要的是輪廓,圖片質量設為最低
handler(canvas.toDataURL('image/png', 0))
window.setTimeout(detect, 33)
}
detect().catch(console.error)降低提取頻率,平衡 性能-體驗
一般視頻 30FPS,嘗試彈幕遮罩(后稱 Mask)刷新頻率降為 15FPS,體驗上還能接受
window.setTimeout(detect, 66) // 33 => 66此時,CPU 占用 50% 左右
解決性能瓶頸

分析火焰圖可發現,性能瓶頸在 toBinaryMask 和 toDataURL
重寫toBinaryMask
分析源碼,結合打印segmentation的信息,發現segmentation.mask.toCanvasImageSource可獲取原始ImageBitmap對象,即是模型提取出來的信息。嘗試自行實現將ImageBitmap轉換成 Mask 的能力,替換開源庫提供的默認實現。
實現原理
async function detect (): Promise<void> {
const segmentation = await segmenter.segmentPeople(videoEl)
context.clearRect(0, 0, canvas.width, canvas.height)
// 1. 將`ImageBitmap`繪制到 Canvas 上
context.drawImage(
// 經驗證 即使出現多人,也只有一個 segmentation
await segmentation[0].mask.toCanvasImageSource(),
0, 0,
canvas.width, canvas.height
)
// 2. 設置混合模式
context.globalCompositeOperation = 'source-out'
// 3. 反向填充黑色
context.fillRect(0, 0, canvas.width, canvas.height)
// 導出Mask圖片,需要的是輪廓,圖片質量設為最低
handler(canvas.toDataURL('image/png', 0))
window.setTimeout(detect, 66)
}第 2、3 步相當于給人像區域外的內容填充黑色(反向填充ImageBitmap),是為了配合css(mask-image), 不然只有當彈幕飄到人像區域才可見(與目標效果正好相反)。
globalCompositeOperation MDN(https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/globalCompositeOperation)
此時,CPU 占用 33% 左右
多線程優化
只剩下toDataURL這個耗時操作了,本以為toDataURL是瀏覽器內部實現,無法再進行優化了。
雖沒有替換實現,但可使用 OffscreenCanvas (https://developer.mozilla.org/zh-CN/docs/Web/API/OffscreenCanvas)+ Worker,將耗時任務轉移到 Worker 中去, 避免占用主線程,就不會影響用戶體驗了。
并且ImageBitmap實現了Transferable接口,可被轉移所有權,跨 Worker 傳遞也沒有性能損耗(https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%A4%E4%B8%AA%E6%96%B9%E6%B3%95%E5%AF%B9%E6%AF%94)。
// 前文 detect 的反向填充 ImageBitmap 也可以轉移到 Worker 中
// 用 OffscreenCanvas 實現, 此處略過
const reader = new FileReaderSync()
// OffscreenCanvas 不支持 toDataURL,使用 convertToBlob 代替
offsecreenCvsEl.convertToBlob({
type: 'image/png',
quality: 0
}).then((blob) => {
const dataURL = reader.readAsDataURL(blob)
self.postMessage({
msgType: 'mask',
val: dataURL
})
}).catch(console.error)
可以看到兩個耗時的操作消失了
此時,CPU 占用 15% 左右
降低分辨率
繼續分析,上圖重新計算樣式(紫色部分)耗時約 3ms
Demo 足夠簡單很容易推測到是這行代碼導致的,發現 imgStr 大概 100kb 左右(視頻分辨率 1280x720)。
danmakuContainer.style.webkitMaskImage = `url(${imgStr})通過canvas縮小圖片尺寸(360P甚至更低),再進行推理。
優化后,導出的 imgStr 大概 12kb,重新計算樣式耗時約 0.5ms。
此時,CPU 占用 5% 左右

啟動條件優化
雖然提取 Mask 整個過程的 CPU 占用已優化到可喜程度。
當在畫面沒人的時候,或沒有彈幕時候,可以停止計算,實現 0 CPU 占用。
無彈幕判斷比較簡單(比如 10s 內收超過兩條彈幕則啟動計算),也不在該 SDK 實現范圍,略過
判定畫面是否有人
第一步中為了高性能,選擇的模型只有ImageBitmap,并沒有提供肢體點位信息,所以只能使用getImageData返回的像素點值來判斷畫面是否有人。
畫面無人時,CPU 占用接近 0%
發布構建優化
依賴包的提交較大,構建出的 bundle 體積:684.75 KiB / gzip: 125.83 KiB
所以,可以進行異步加載SDK,提升頁面加載性能。
- 分別打包一個 loader,一個主體
- 由業務方 import loader,首次啟用時異步加載主體
這個兩步前端工程已經非常成熟了,略過細節。
運行效果

總結
過程
- 選擇高性能模型后,初始狀態 CPU 70%
- 降低 Mask 刷新頻率(15FPS),CPU 50%
- 重寫開源庫實現(toBinaryMask),CPU 33%
- 多線程優化,CPU 15%
- 降低分辨率,CPU 5%
- 判斷畫面是否有人,無人時 CPU 接近 0%
CPU 數值指主線程占用
注意事項
- 兼容性:Chrome 79及以上,不支持 Firefox、Safari。因為使用了OffscreenCanvas
- 不應創建多個或多次創建segmenter實例(bodySegmentation.createSegmenter),如需復用請保存實例引用,因為:
- 創建實例時低性能設備會有明顯的卡頓現象
- 會內存泄露;如果無法避免,這是mediapipe 內存泄露 解決方法(https://github.com/google/mediapipe/issues/2819#issuecomment-1160335349)
經驗
- 優化完成之后,提取并應用 Mask 關鍵計算量在 GPU (30%左右),而不是 CPU
- 性能優化需要業務場景分析,防擋彈幕場景可以使用低分辨率、低刷新率的 mask-image,能大幅減少計算量
- 該方案其他應用場景:
- 替換/模糊人物背景
- 人像馬賽克
- 人像摳圖
- 卡通頭套,虛擬飾品,如貓耳朵、兔耳朵、帶花、戴眼鏡什么的(換一個模型,略改)
- 關注Web 神經網絡 API (https://mp.weixin.qq.com/s/v7-xwYJqOfFDIAvwIVZVdg)進展,以后實現相關功能也許會更簡單
本期作者

劉俊
嗶哩嗶哩資深開發工程師