作者 | 陳峻
審校 | 重樓
引言

如今,基于互聯網服務的欺詐案例時常登頂媒體頭條,而使用在線服務和數字交易的金融行業尤其成為了重災區。網絡洗錢、保險欺詐、網銀盜用、虛假銀行交易等復雜金融欺詐行為層出不窮,我們亟待通過行之有效的欺詐識別與檢測的手段,來保護個人和組織免受巨大的經濟損失。
作為一種自適應性強、可擴展性高的技術,機器學習算法具有從數據中學習、發現復雜模式的能力,因此被廣泛地應用于各種科學領域。而檢測金融欺詐正是其能夠大顯身手的新賽道。
模型介紹
目前,被用于金融欺詐檢測的典型算法包括:邏輯回歸(LR)、支持向量機(SVM)、K-近鄰(KNN)、奈夫貝葉斯(NB)、決策樹(DT)、隨機森林(RF)和增強奈夫貝葉斯 (TAN)等。其中,
- SVM使用最佳超平面對數據點進行分類
- KNN根據K-Nearest Neighbors對交易進行分類
- NB使用概率學習來估計類別的概率
- DT通過生成決策樹以進行基于特征的分類
- RF結合決策樹以減少過擬合
- TAN通過樹狀依賴結構來增強NB以捕捉特征相關性
這些模型為識別和檢測金融欺詐提供了多種方法,有助于建立出強大的實時欺詐檢測系統。當然,它們各有利弊,在為具體應用選擇算法時,我們需要考慮數據集的大小、特征空間、處理需求、以及可解釋性等因素。
為此,一種改進的集合機器學習(Ensemble Machine Learning)技術應運而生。它能夠將多個單獨的算法模型組合在一起,通過重點優化模型的各項參數、提高性能指標,以及整合深度學習(如Bagging、Boosting和Stacking),進而創建出可以修復識別到的錯誤、并減少假陰性的強大欺詐檢測系統。
集合學習檢測模型
既然是組合,那么我們便可以綜合選配各種機器學習分類器。而每一種分類器都會以其獨特的優勢發揮應有的作用。

如上圖所示,一個典型的金融欺詐類識別與檢測模型會包括如下組件:
- SVM,擅長為類別分離確定適當的超平面
- LR,對事件概率進行建模
- RF,能夠建立穩健的決策樹
- KNN,根據近鄰中的多數類進行分類
- Bagging,會使用KNN作為基本分類器,以進一步豐富集合
- Boosting,使用RF作為基礎分類器
- 最下方的投票分類器(Voting Classifier)可以綜合上述分類器的各種預測結果
由于采用了集合機器學習的協同方式,因此該模型在檢測金融領域少數類別的數據,以及解決類別不平衡方面,具有出色的表現。其根本意愿在于,集合模型有助于聚集不同的弱學習算法,以增強其整體識別與檢測能力,進而提高相關決策的可解釋性和透明度。此外,與深度學習架構相比,集合式計算的密集度較低,因此也更適合金融領域本來就計算資源有限的場景。
檢測模型的評估
我們該如何來評估機器學習系統對于具體金融欺詐的檢測效果呢?通常,業界會采用如下基本流程:
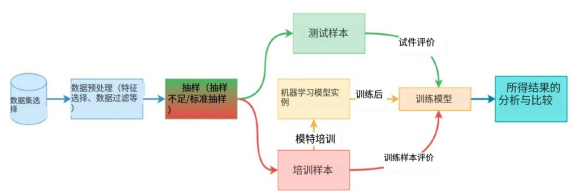
- 首先,選擇一個包含了合法交易和欺詐交易記錄的數據集。
- 由于數據集中存在著各種無序、原始、殘缺、以及重復的實例,系統的檢測很容易出現誤差,因此我們需要進行數據預處理,使其適合模型的訓練和測試。
- 接著,鑒于欺詐交易只占整體交易數據的一小部分,我們需要對不平衡的數據集進行采樣。
- 然后,系統將整理好的采樣數據分為訓練樣本和測試樣本,使用其中的訓練樣本對已選的機器學習模型進行訓練,并使用這兩種樣本來觀察訓練模型的行為。
- 在獲得準確率、精確度、召回率、F1分數等選定評估參數的結果后,對系統的整體能力進行分析和比較。
模型評估標準
在評估模型的清晰度和理解度時,業界通常會使用混淆矩陣(Confusion Matrix)。如下圖所示,該矩陣由真陽性(TP)、真陰性(TN)、假陽性(FP)和假陰性(FN)四個直觀的象限組成:

基于上述矩陣,目前被業界廣泛認可的是模型評估標準通常包括:準確率、精確度、召回率和F1分數四個方面的指標。其中:
- 準確率,是所有正確預測(TP + TN)與樣本中預測或條目總數(TP + TN + FN + FP)之比。
- 精確度,是TP與模型所做的所有正面預測(TP + FP)之比。換句話說,它是模型做出的正面預測的準確度。
- 召回率,是用來衡量機器學習模型識別正向類所有實例的能力指標。它是正確預測到的陽性觀察結果(TP)與實際陽性觀察結果總數(TP+FN)的比率。
- F1分數,是將精確度和召回率的結果合并為一個平衡的平均值指標。
評估模型的準確率
目前,有專家將集合學習模型與里面包含的LR、RF、KNN、Bagging、Boosting模型進行了逐一比較。就同樣的數據集測試樣本而言,其結果的精確度、召回率和F1分數如下表所示:
LR | RF | KNN | Bagging | Boosting | 集合學習模型 | |
精確度 | 0.945938 | 0.999891 | 0.999174 | 0.999 | 0.999092 | 0.999601 |
召回 | 0.944256 | 0.99989 | 0.999173 | 0.999 | 0.999092 | 0.9996 |
F1分數 | 0.944204 | 0.99989 | 0.999173 | 0.999 | 0.999092 | 0.9996 |
可見,集合學習模型能夠很好地捕捉到相關數據,對其進行精確預測,從而實現了對特定數據的高靈敏度,并保持了穩定的較低誤判率。
下表則更全面地向您展示了將各種典型機器學習算法,被運用到實時金融欺詐場景的準確率綜合比較:
金融欺詐場景 | 機器學習算法 | 準確率 |
信用卡欺詐檢測 | 卷積神經網絡 | 99% |
信用卡欺詐檢測 | 長短期記憶 | 99.5% |
欺詐性信用卡識別 | 直覺貝葉斯 | 96.1% |
欺詐性信用卡識別 | KNN | 95.89% |
欺詐性信用卡識別 | 隨機森林 | 97.58% |
欺詐性信用卡識別 | 序列卷積神經網絡 | 92.3% |
銀行B2C 在線交易 | 卷積神經網絡 | 91% |
信用卡交易數據集 | 分布式深度神經網絡 | 99.9422% |
評估模型效率
除了準確率維度,我們也應該評估模型的計算效率。這往往涉及到在檢測過程中,模型所需的訓練和測試時間,以及這些過程對內存和存儲等系統資源的利用率。
算法訓練 | 在訓練樣本上測試 | 在測試樣本上測試 | ||||
時間(毫秒) | 內存使用量(MiB) | 時間(毫秒) | 內存使用量(MiB) | 時間(毫秒) | 內存使用量(MiB) | |
LR | 3.5 | 1190.03-1190.64 | 2.9 | 1190.65-1190.65 | 2.5 | 1190.77-1190.77 |
RF | 1135 | 1295.93-1296.31 | 19.9 | 1296.31-1296.31 | 8.28 | 1296.31-1296.33 |
KNN | 0.597 | 1190.77-1288.20 | 1431 | 1288.20-1294.43 | 355 | 1295.43-1295.89 |
Bagging | 9.23 | 1147.86-1841.64 | 10179 | 1841.89-819.89 | 2331 | 820.93-1342.43 |
Boosting | 883 | 1341.71-1454.40 | 14.8 | 1454.46-1458.23 | 6.05 | 1456.50-1456.86 |
集合學習模型 | 2049 | 1455.36-2282.86 | 11681 | 2282.89-2158.89 | 2928 | 2155.05-2028.86 |
注意:上表中的內存使用值是以兆字節(MiB)為單位,換算系數關系為1 MiB等于1.04858 MB。
總體而言,不同算法的訓練和測試時間各不相同。其中,LR、SVM和KNN算法的訓練時間較長,但測試時間較短;而其他模型則呈現出相反的趨勢。
小結
綜合上述,通過利用各種計算學習算法,我們不但可以提高金融欺詐檢測的準確性和效率,而且能夠盡早地發現潛在的欺詐活動,進而及時采取預防和抵御的措施,以減少其影響。
同時,隨著信用卡欺詐技術的不斷發展,能夠有效綜合各種算法優勢的集合機器學習檢測模型,已為我們進一步開發更具擴展性和適應性的欺詐檢測系統,奠定了基礎。從而在保證金融系統安全的同時,持續維護了消費者對于多元化互聯網金融交易的信心。
作者介紹
陳峻(Julian Chen),51CTO社區編輯,具有十多年的IT項目實施經驗,善于對內外部資源與風險實施管控,專注傳播網絡與信息安全知識與經驗。