













微軟打造 13 億參數小型 LLM AI 模型,號稱實際效果勝于千億參數 GPT-3.5
作者:漾仔
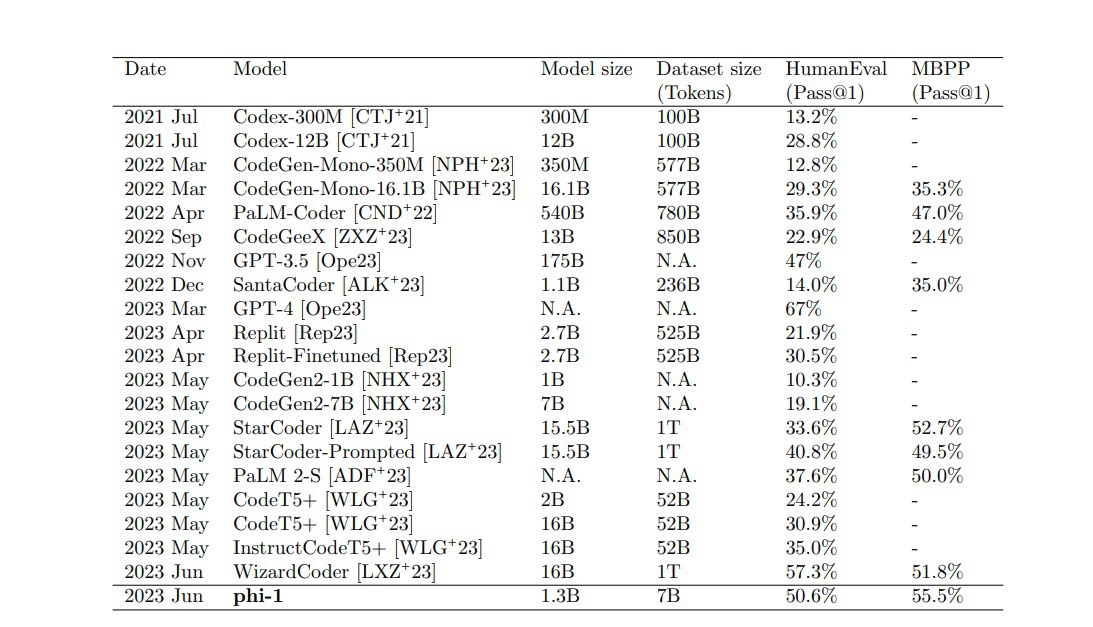
微軟團隊表示,比起增加模型的參數量,通過提高模型的訓練數據集質量,也許更能強化模型的準確率和效率,于是,他們利用高質量數據訓練出了 phi-1 模型。在測試中,phi-1 的分數達到 50.6%,比起 1750 億參數的 GPT-3.5(47%)還要好。

6 月 27 日消息,AI 模型盲堆體積實際上效果并不見得更好,更多要看訓練數據的質量,微軟日前最近發布了一款 13 億參數的語言模型 phi-1,采用“教科書等級”的高品質資料集訓練而成,據稱“實際效果勝于千億參數的 GPT 3.5”。

▲ 圖源 Arxiv
IT之家注意到,該模型以 Transformer 架構為基礎,微軟團隊使用了包括來自網絡的“教科書等級”數據和以 GPT-3.5 經過處理的“邏輯嚴密的內容”,以及 8 個英偉達 A100 GPU,在短短 4 天內完成訓練。

▲ 圖源 Arxiv
微軟團隊表示,比起增加模型的參數量,通過提高模型的訓練數據集質量,也許更能強化模型的準確率和效率,于是,他們利用高質量數據訓練出了 phi-1 模型。在測試中,phi-1 的分數達到 50.6%,比起 1750 億參數的 GPT-3.5(47%)還要好。
▲ 圖源 Arxiv
微軟表示,phi-1 接下來會在 HuggingFace 中開源,而這不是微軟第一次開發小型 LLM,此前,他們打造一款 130 億參數的 Orca,使用了 GPT-4 合成的數據訓練而成,表現也同樣比 ChatGPT 更好。
目前關于 phi-1 的論文已經在 arXiv 中發布,可以在這里找到論文的相關內容。
責任編輯:姜華
來源:
IT之家





























