如何使用數據版本控制管理數據湖中的模式驗證
譯文譯者 | 李睿
審校 | 重樓
數據團隊依賴許多其他“第三方”發送數據的情況并不少見,他們經常在沒有進行任何溝通或讓數據團隊知道太晚的情況下更改數據的模式。
每當發生這種情況時,數據管道就會遭到破壞,數據團隊需要修復數據湖。這是一個充滿繁重任務的人工過程。在通常情況下,數據團隊可能會推卸責任,試圖證明模式已經改變。
但是隨著發展和進步,數據團隊意識到,以自動持續集成(CI)/持續交付(CD)的方式簡單地阻止模式一起更改是更明智的。
模式更改和模式驗證給數據團隊帶來了很多痛苦,但是市場上有一些解決方案可以幫助解決這個問題——幸運的是,其中一些是開源的。
以下是一個循序漸進的教程,介紹如何使用開源數據版本控制工具lakeFS解決模式驗證問題。
什么是模式驗證?
模式驗證允許用戶為數據湖創建驗證規則,例如允許的數據類型和值范圍。它保證保存在數據湖中的數據遵循已建立的模式,該模式描述了數據的結構、格式和限制。
由于用戶的數據湖可以填充來自具有不同模式定義的各種來源的數據,因此在數據湖中的所有數據上強制使用統一的模式是一個挑戰。
這是一個需要解決的問題——如果不快速采取行動,就會在數據處理過程中看到不一致和錯誤。
為什么需要處理模式驗證?
花費一些時間正確地管理模式是值得的,有以下四個原因:
- 一致性——數據湖通常包含來自多個來源的大量數據。如果沒有模式驗證,最終可能會以不一致或不正確的形式存儲在數據湖中,從而導致處理過程中的問題。
- 質量——模式驗證通過施加數據限制和標準,有助于保持數據湖中數據的良好質量。它可以幫助用戶識別和標記數據質量問題,例如丟失或不準確的信息,在它們導致下游出現問題之前。
- 效率——模式驗證通過確保數據湖中所有數據的統一模式來加快數據處理和分析。這反過來又減少了清理、轉換和分析數據所需的時間和精力,并提高了數據管道的總體效率。
- 合規性——許多企業必須滿足嚴格的監管和合規性要求。模式驗證有助于確保存儲在數據湖中的數據符合這些標準,從而提供對數據沿襲和質量的清晰審計跟蹤。
處理數據湖中的模式并非一帆風順
在數據倉庫中,用戶處理的是嚴格的數據模型和嚴格的模式。數據湖與之相反。大多數情況下,它們最終包含廣泛的數據源。
為什么這很重要?因為在數據湖中,模式的定義可以在數據源之間發生變化,并且當添加新數據時,模式可能會隨著時間的推移而變化。這使得在數據湖中的所有數據上實施統一的模式成為一個巨大的挑戰。如果不能解決這個問題,將不得不解決數據處理問題。
但這還不是全部。由于構建在數據湖之上的數據管道的復雜性不斷增加,無法擁有一個一致的模式。數據管道可以包括多個流程和轉換,每個流程和轉換都需要一個唯一的模式定義。
模式可能隨著數據的處理和修改而變化,因此很難確保跨整個管道進行模式驗證。
這就是版本控制系統可以派上用場的地方。
在數據湖中實現模式驗證的數據版本控制
lakeFS是一個開源工具,它可以將數據湖轉換為類似Git的存儲庫,讓用戶像軟件工程師管理代碼一樣管理它。這就是數據版本控制的意義所在。
與其他源代碼控制系統一樣,lakeFS有一個稱為hook的特性,它是定制的腳本或程序,lakeFS平臺可以運行這些腳本或程序來響應指定的事件或操作。
這些事件可以包括提交更改、合并分支、創建新分支、添加或刪除標記等等。例如,當合并發生時,在合并完成之前,在源分支上運行一個預合并掛鉤。
它如何應用于模式驗證呢? 用戶可以創建一個預合并掛鉤來驗證Parquet文件的模式與當前模式是否相同。
需要準備什么
- lakeFS服務器(可以免費安裝或在云中啟動)。
- 可選:可以使用sample-repo來啟動一個筆記本(notebook),筆記本可以配置為連接到lakeFS服務器。
在這個場景中,將在一個攝取分支中創建一個delta表,并將其合并到生產中。接下來將更改表的模式,并嘗試再次合并它,模擬將數據提升到生產的過程。
1.設置
首先,將設置一些全局變量并安裝將在本例中使用的包,這些包將在Python筆記本中運行。
在設置好lakeFS憑證后,可以開始創建一些包含存儲庫和分支名稱的全局變量:
Python
repo = "schema-validation-example-repo"
mainBranch = "main"
ingestionBranch = "ingestion_branch"每個lakeFS存儲庫都需要有自己的存儲命名空間,所以也需要創建一個:
Python
storageNamespace = 's3://' # e.g. "s3://username-lakefs-cloud/"在本例中,使用AWS S3存儲。為了使一切順利進行,用戶的存儲需要配置為與lakeFS一起運行,lakeFS與AWS、Azure、Google Cloud或內部部署對象存儲(如MinIO)一起工作。
如果在云中運行lakeFS,則可以通過復制示例存儲庫的存儲名稱空間并將字符串附加到其上,將其鏈接到存儲。所以,如果lakeFS Cloud提供了這個sample-repo:

可以通過以下方式進行配置:
Python
storageNamespace = 's3://lakefs-sample-us-east-1-production/AROA5OU4KHZHHFCX4PTOM:2ae87b7718e5bb16573c021e542dd0ec429b7ccc1a4f9d0e3f17d6ee99253655/my_random_string'在筆記本中,將使用Python代碼,因此也必須導入lakeFS Python客戶端包:
Python
import lakefs_client
from lakefs_client import models
from lakefs_client.client import LakeFSClient
import os
from pyspark.sql.types import ByteType, IntegerType, LongType, StringType, StructType, StructField接下來,配置客戶端:
Python
%xmode Minimal
if not 'client' in locals():
# lakeFS credentials and endpoint
configuration = lakefs_client.Configuration()
configuration.username = lakefsAccessKey
configuration.password = lakefsSecretKey
configuration.host = lakefsEndPoint
client = LakeFSClient(configuration)
print("Created lakeFS client.")以下將在本例中創建delta表,因此需要包括以下包:
Python
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages io.delta:delta-core_2.12:2.0.0 --conf "spark.sql.extensinotallow=io.delta.sql.DeltaSparkSessionExtension" --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" pyspark-shell'lakeFS公開了一個S3網關,它允許應用程序以與S3通信的方式與lakeFS進行接口。要配置網關,并執行以下步驟:
Python
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
sc = SparkContext.getOrCreate()
spark = SparkSession(sc)
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", lakefsAccessKey)
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", lakefsSecretKey)
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", lakefsEndPoint)
sc._jsc.hadoopConfiguration().set("fs.s3a.path.style.access", "true")現在已經準備好在筆記本中大規模使用lakeFS版本控制。
2.創建存儲庫和掛鉤
以下將使用Python客戶端創建存儲庫:
Python
client.repositories.create_repository(
repository_creatinotallow=models.RepositoryCreation(
name=repo,
storage_namespace=storageNamespace,
default_branch=mainBranch))在這種情況下,將使用預合并掛鉤來確保架構沒有更改。操作文件應提交到lakeFS存儲庫,前綴為_lakeFS_actions/。未能分析操作文件將導致運行失敗。
將提交以下鉤子配置操作文件,pre-merge-schema-validation.yaml:
Python
#Parquet schema Validator
#Args:
# - locations (list of strings): locations to look for parquet files under
# - sample (boolean): whether reading one new/changed file per directory is enough, or go through all of them
#Example hook declaration: (_lakefs_actions/pre-merge-schema-validation.yaml):
name: pre merge checks on main branch
on:
、
pre-merge:
branches:
- main
hooks:
- id: check_schema_changes
type: lua
properties:
script_path: scripts/parquet_schema_change.lua # location of this script in the repository
args:
sample: false
locations:
- tables/customers/這個文件(pre-merge-schema-validation.yaml)存儲在example repo中的子文件夾LuaHooks中。必須將文件提交到文件夾_lakeFS_actions下的lakeFS存儲庫:
Python
hooks_config_yaml = "pre-merge-schema-validation.yaml"
hooks_prefix = "_lakefs_actions"
with open(f'./LuaHooks/{hooks_config_yaml}', 'rb') as f:
client.objects.upload_object(repository=repo,
branch=mainBranch,
path=f'{hooks_prefix}/{hooks_config_yaml}',
cnotallow=f
)只是設置了一個動作腳本,在合并到main之前運行scripts/parquet_schema_che.lua。
然后將創建腳本本身(parquet_schema_che.lua)并將其上載到腳本目錄中。正如人們所看到的,使用嵌入式LuaVM來運行鉤子,而不依賴于其他組件。
此文件也位于ample-repo中的LuaHooks子文件夾中:
Python
--[[
Parquet schema validator
Args:
- locations (list of strings): locations to look for parquet files under
- sample (boolean): whether reading one new/changed file per directory is enough, or go through all of them
]]
lakefs = require("lakefs")
strings = require("strings")
parquet = require("encoding/parquet")
regexp = require("regexp")
path = require("path")
visited_directories = {}
for _, location in ipairs(args.locations) do
after = ""
has_more = true
need_more = true
print("checking location: " .. location)
while has_more do
print("running diff, location = " .. location .. " after = " .. after)
local code, resp = lakefs.diff_refs(action.repository_id, action.branch_id, action.source_ref, after, location)
if code ~= 200 then
error("could not diff: " .. resp.message)
end
for _, result in pairs(resp.results) do
p = path.parse(result.path)
print("checking: '" .. result.path .. "'")
if not args.sample or (p.parent and not visited_directories[p.parent]) then
if result.path_type == "object" and result.type ~= "removed" then
if strings.has_suffix(p.base_name, ".parquet") then
-- check it!
code, content = lakefs.get_object(action.repository_id, action.source_ref, result.path)
if code ~= 200 then
error("could not fetch data file: HTTP " .. tostring(code) .. "body:\n" .. content)
end
schema = parquet.get_schema(content)
for _, column in ipairs(schema) do
for _, pattern in ipairs(args.column_block_list) do
if regexp.match(pattern, column.name) then
error("Column is not allowed: '" .. column.name .. "': type: " .. column.type .. " in path: " .. result.path)
end
end
end
print("\t all columns are valid")
visited_directories[p.parent] = true
end
end
else
print("\t skipping path, directory already sampled")
end
end
-- pagination
has_more = resp.pagination.has_more
after = resp.pagination.next_offset
end
end把文件(這次是parquet_schema_che.lua)從LuaHooks目錄上傳到lakeFS存儲庫中操作配置文件中指定的位置(即腳本文件夾內):
Python
hooks_config_yaml = "pre-merge-schema-validation.yaml"
hooks_prefix = "_lakefs_actions"
with open(f'./LuaHooks/{hooks_config_yaml}', 'rb') as f:
client.objects.upload_object(repository=repo,
branch=mainBranch,
path=f'{hooks_prefix}/{hooks_config_yaml}',
content=f
)必須在提交操作文件后提交更改才能生效:
Python
client.commits.commit(
repository=repo,
branch=mainBranch,
commit_creatinotallow=models.CommitCreation(
message='Added hook config file and schema validation scripts'))如果切換到lakeFS UI,應該會在主目錄下看到以下目錄結構和文件:
 LakeFS UI的目錄結構
LakeFS UI的目錄結構
 lakeFS UI中顯示的合并前架構驗證
lakeFS UI中顯示的合并前架構驗證
 lakeFS UI中的架構驗證腳本
lakeFS UI中的架構驗證腳本
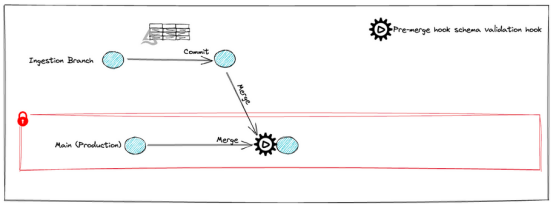
3.使用原始模式運行第一個ETL
在lakeFS中,可以在與生產(主要)分支不同的分支上進行攝取和轉化。
以下將建立一個攝取分支:
Python
client.branches.create_branch(
repository=repo,
branch_creatinotallow=models.BranchCreation(
name=ingestionBranch, source=mainBranch))接下來,將使用Kaggle數據集Orion Star——運動和戶外RDBMS數據集。使用Customer.csv,可以從data/samples/OrionStar/將其上傳到示例存儲庫。
首先,需要定義表模式:
Python
customersSchema = StructType([
StructField("User_ID", IntegerType(), False),
StructField("Country", StringType(), False),
StructField("Gender", StringType(), False),
StructField("Personal_ID", IntegerType(), True),
StructField("Customer_Name", StringType(), False),
StructField("Customer_FirstName", StringType(), False),
StructField("Customer_LastName", StringType(), False),
StructField("Birth_Date", StringType(), False),
StructField("Customer_Address", StringType(), False),
StructField("Street_ID", LongType(), False),
StructField("Street_Number", IntegerType(), False),
StructField("Customer_Type_ID", IntegerType(), False)
])然后,從CSV文件中,將創建一個delta表,并將其提交到存儲庫:
Python
customersTablePath = f"s3a://{repo}/{ingestionBranch}/tables/customers"
df = spark.read.csv('./data/samples/OrionStar/CUSTOMER.csv',header=True,schema=customersSchema)
df.write.format("delta").mode("overwrite").save(customersTablePath)在這里需要做出改變:
Python
client.commits.commit(
repository=repo,
branch=ingestionBranch,
commit_creatinotallow=models.CommitCreation(
message='Added customers Delta table',
metadata={'using': 'python_api'}))然后,使用合并將數據發送到生產:
Python
client.refs.merge_into_branch(
repository=repo,
source_ref=ingestionBranch,
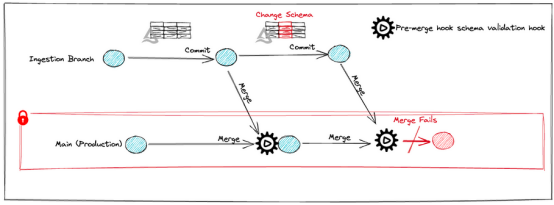
destination_branch=mainBranch)已經完成的架構驗證序列:
4. 修改模式并嘗試將表移動到生產環境
為了簡化操作,將重命名其中一列。以下將Country_name替換為Country_name:
Python
customersSchema = StructType([
StructField("User_ID", IntegerType(), False),
StructField("Country_Name", StringType(), False), # Column name changes from Country to Country_name
StructField("Gender", StringType(), False),
StructField("Personal_ID", IntegerType(), True),
StructField("Customer_Name", StringType(), False),
StructField("Customer_FirstName", StringType(), False),
StructField("Customer_LastName", StringType(), False),
StructField("Birth_Date", StringType(), False),
StructField("Customer_Address", StringType(), False),
StructField("Street_ID", LongType(), False),
StructField("Street_Number", IntegerType(), False),
StructField("Customer_Type_ID", IntegerType(), False)
])在攝取分支中,重新創建delta表:
Python
customersTablePath = f"s3a://{repo}/{ingestionBranch}/tables/customers"
df = spark.read.csv('./data/samples/OrionStar/CUSTOMER.csv',header=True,schema=customersSchema)
df.write.format("delta").mode("overwrite").option("overwriteSchema", "true").save(customersTablePath)
])需要進行修改:
Python
client.commits.commit(
repository=repo,
branch=ingestionBranch,
commit_creatinotallow=models.CommitCreation(
message='Added customers table with schema changes',
metadata={'using': 'python_api'}))然后,可以嘗試將數據投入生產:
Python
client.commits.commit(
repository=repo,
branch=ingestionBranch,
commit_creatinotallow=models.CommitCreation(
message='Added customer tables with schema changes!',
metadata={'using': 'python_api'}))由于模式修改,得到了一個先決條件Failed錯誤。合并前的掛鉤阻礙了晉升。因此,這些數據不會在生產中使用:

從lakeFS UI中,可以導航到存儲庫并選擇“Actions”選項。接下來,單擊失敗操作的Run ID,選擇“主分支上的合并前檢查”,展開check_schema_changes,并查看錯誤消息。
結語
由于存儲數據的異構性和原始性,數據湖上的模式驗證至關重要,但也很困難。管理模式演變、數據轉換和跨多種格式的兼容性檢查意味著每個數據從業者都需要一些非常強大的方法和工具。
數據湖的去中心化性質,許多用戶和系統可以在其中編輯數據,使模式驗證更加復雜。模式的驗證對于數據治理、集成和可靠的分析至關重要。
像上面展示的預合并掛鉤這樣的解決方案有助于在將模式文件合并到生產分支之前驗證它們。它在保證數據完整性和防止不兼容的模式更改合并到主分支時非常方便。它還增加了一層額外的質量控制,使數據更加一致。
原文標題:Managing Schema Validation in a Data Lake Using Daa Version Control,作者:Iddo Avneri