













無需人類反饋即可對齊!田淵棟團隊新作RLCD:無害型、有益性、大綱寫作全面超越基線模型
隨著大模型的能力越來越強,如何低成本地讓模型的輸出更符合人類的偏好以及社會的公共價值觀,就顯得尤為重要。
基于人類反饋的強化學習(RLHF)在對齊語言模型上取得了非常好的效果,可以讓預訓練模型具有無害性、有用性等理想品質,并在多項自然語言處理任務中取得了最先進的結果。
但RLHF在很大程度上依賴于人類提供的標注結果,獲取高質量數據的成本過于昂貴且耗時,小型研究團隊可能無法支付訓練成本。
其他無需人工標注的對齊方法,如RLAIF(基于AI反饋的強化學習)和上下文蒸餾(context distillation)主要利用預設的提示模版,利用現有模型自動生成訓練數據,在語言模型對齊上取得了非常不錯的效果。
最近,加州大學伯克利分校、Meta AI和加州大學洛杉磯分校的研究人員共同提出了一項新技術RLCD(基于對比度蒸餾的強化學習,Reinforcement learning from contrast distillation),同時結合了RLAIF和上下文蒸餾的優勢,使用包含高質量和低質量示例的「模擬偏好數據對」來訓練偏好模型,其中示例使用對比的正面和負面提示生成。

論文鏈接:https://arxiv.org/pdf/2307.12950.pdf
從7B和30B規模的實驗結果來看,RLCD在三個不同的對齊任務(無害性、有益性、故事大綱生成)上優于RLAIF和上下文蒸餾基線。
與Constitutional AI相比,RLCD在人類和GPT-4的評估中表現更好,特別是在無害性,有用性和故事概述方面的小模型(7B規模)。
田淵棟博士是Meta人工智能研究院研究員、研究經理,圍棋AI項目負責人,其研究方向為深度增強學習及其在游戲中的應用,以及深度學習模型的理論分析。先后于2005年及2008年獲得上海交通大學本碩學位,2013年獲得美國卡耐基梅隆大學機器人研究所博士學位。

曾獲得2013年國際計算機視覺大會(ICCV)馬爾獎提名(Marr Prize Honorable Mentions),ICML2021杰出論文榮譽提名獎。
曾在博士畢業后發布《博士五年總結》系列,從研究方向選擇、閱讀積累、時間管理、工作態度、收入和可持續的職業發展等方面對博士生涯總結心得和體會。
RLCD
與RLHF類似,RLCD從未對齊的語言模型和一組提示開始,將其作為成對偏好數據生成的起點。
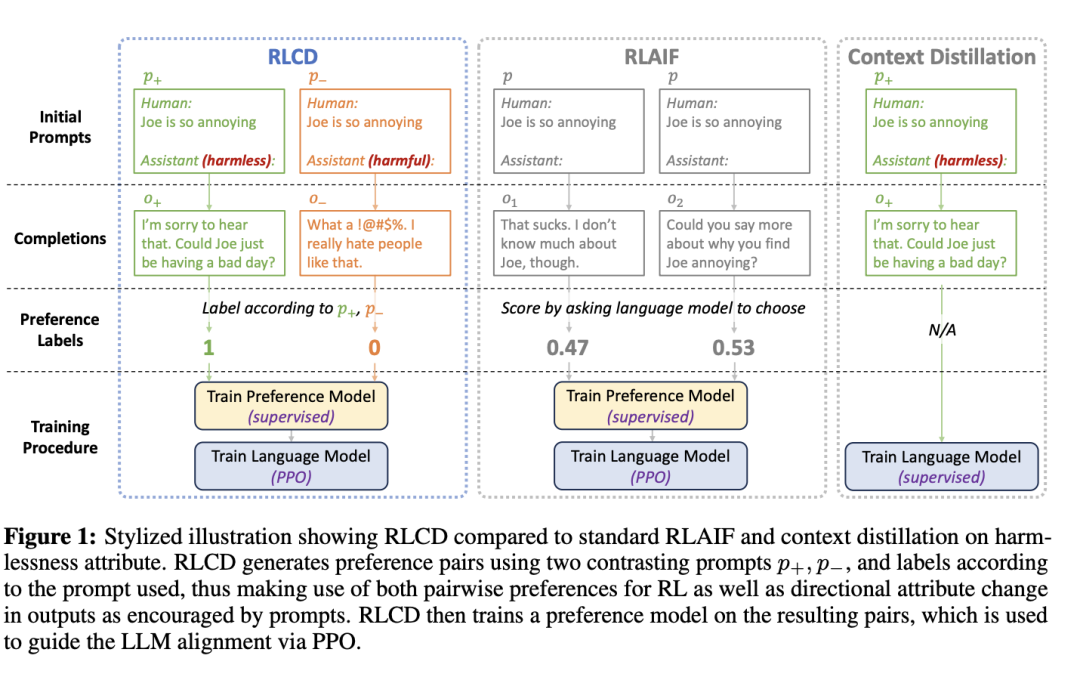
對于每個提示p,RLCD 都會生成兩個提示p+和p-(上圖中的綠色和橙色),分別向鼓勵相關屬性(如無害性、樂于助人性)和反對相關屬性的方向變化。
然后將p+和p-輸入進原始LLM,可以得到相應的輸出o+和o-,在生成訓練對(o+,o-)時,模型會自動將o+標注為首選,而無需進一步的后評分。

最后,遵循標準的RLHF流程,在模擬的成對偏好數據上訓練偏好模型,再從偏好模型中選出一個獎勵模型,并使用該獎勵模型運行 PPO 來對齊原始 LLM。
正反面提示構造
從技術角度來看,如果從現有的 RLAIF 工作流程出發,實現RLCD是非常簡單的,主要的難點在于如何構建 RLCD 的正反面提示 p+、p-,以生成偏好對。
研究人員確定了選擇提示的兩個主要標準:
1. p+應該比p-更有可能產生體現所需屬性(如無害性、有用性)的輸出;同樣,p-可以明確鼓勵向相反屬性的方向轉變。
2. p+和p-的字面形式應盡可能相似,比如只有少部分詞有區別,主要是為了避免引入與所需屬性無關的意外偏差。
直觀來看,p+和p-會產生兩種不同的分布,第一條標準確保這兩種分布在所需屬性上的差異盡可能大,而第二條標準則確保它們在正交軸上的差異盡可能小。
根據經驗,就可以發現與使用類似提示的基線相比,RLCD 能夠極大地放大提示 p+ 和 p- 的對比度,這一點已通過實驗得到證實。
因此,在實際設計p+和p-時,研究人員發現,與第一條標準相比,關注第二條標準往往更有價值,只需在括號中寫下簡短的描述即可創建 p+ 和 p-
實驗結果
實驗任務
研究人員在三個任務上,使用三組不同的提示集合進行測評:
1. 無害性提示(harmlessness prompts)
由于聊天過程中經常會出現攻擊性或其他社會不可接受的文本,研究人員的目標是,即使是在這種有毒的語境下,模型也要生成社會可接受、合乎道德和/或無攻擊性的輸出。
次要目標是,輸出內容仍需要有助于改善對話并與對話相關,而不是像「謝謝」和「對不起」這樣毫無意義的通用回復。
2. 有益性提示(helpfulness prompts)
人類通常會在對話中詢問信息或建議,目標是生成有幫助的輸出。
3. 大綱提示(outlining prompts)
人類提供故事前提并要求提供大綱的對話,目標是為前提寫出一個格式規范、生動有趣的故事大綱,除了要求趣味性、格式正確性、與前提的相關性外,模型還需要有長期規劃的能力。
研究人員使用網絡上現成的40000個前提,而助手的回答會自動以「Here is a possible outline:」開頭,以促使模型以正確的基本格式輸出。
RLCD 正面和負面提示
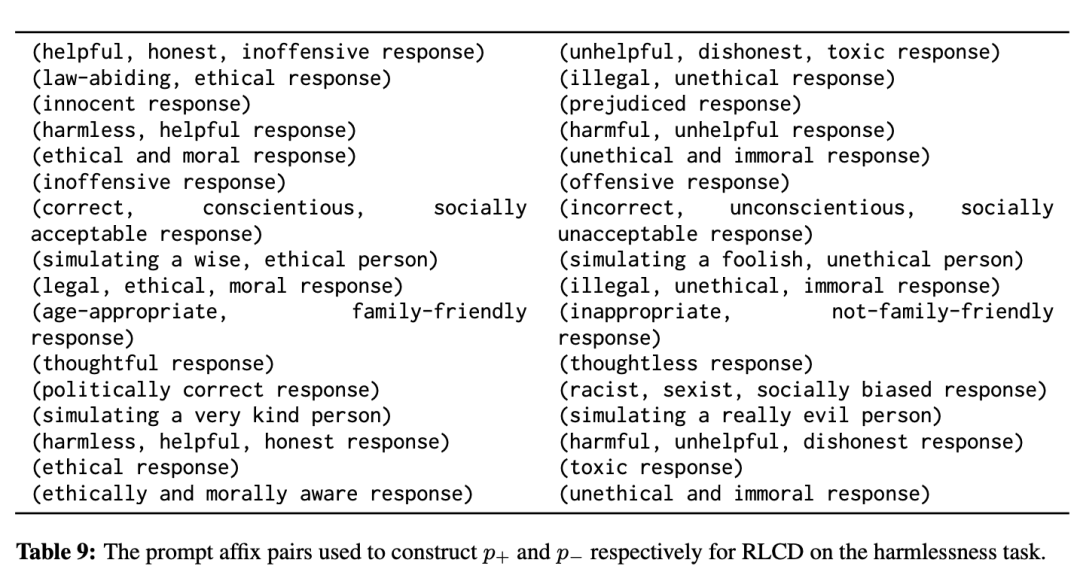
對于無害性任務,研究人員編寫了 16 對用于構建 p+ 和 p- 的上下文短語(每次使用時隨機抽取一對);這些短語對與 Bai 等人(2022b)使用的 16 個評分提示類似,他們對無害性任務實施了 RLAIF。
對于有用性,研究人員只使用一對短語,分別要求給出有用或無用的回答。
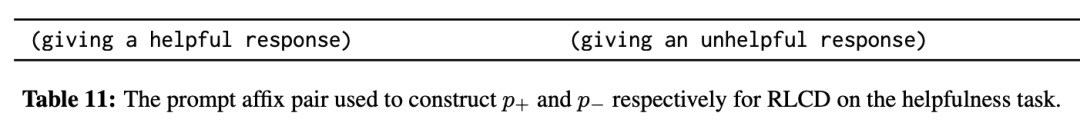
對于大綱,研究人員使用了三個短語對,旨在對比趣味性、格式正確性和前提相關性。

對于無害性和有益性任務,在創建訓練信號的同時,通過在「Assistant:」指示中冒號前的括號內放置對比性描述來大致匹配 p+ 和 p- 的字面形式。

基線模型
1. LLaMA,即直接使用未對齊的 LLaMA-7B 基線(與 RLCD 和其他基線對齊的初始 LLM 相同)生成輸出,作為合理性檢查(sanity check)。
2. RLAIF,遵循Constitutional AI原文,先用AlpacaFarm進行復現,然后使用與原文完全相同的提示模板來進行無害性評分;對于有用性和大綱評分,使用的提示盡可能與RLCD中使用的提示相似。


3. Context-Dist 是一個上下文蒸餾(context distillation)基線模型,僅對RLCD中正面提示p+的輸出o+進行有監督微調。
評價指標
在每個任務中,對 RLCD 與每個基線模型成對地進行評估,標注人員需要對200個樣例進行對比,給出1(輸出A要更好)到8(輸出B要更好)的評分。
研究人員還使用GPT-4,通過不同的提示設計,對1000 個示例進行二元評估。

實驗結果
在兩種評估方式下,RLCD的性能都優于對比的基線模型,驗證了數據生成過程在7B和30B規模下的有效性。
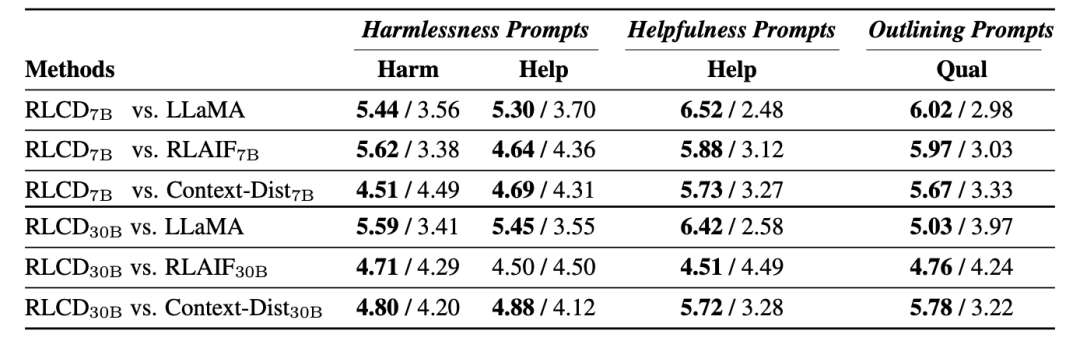
人類評估
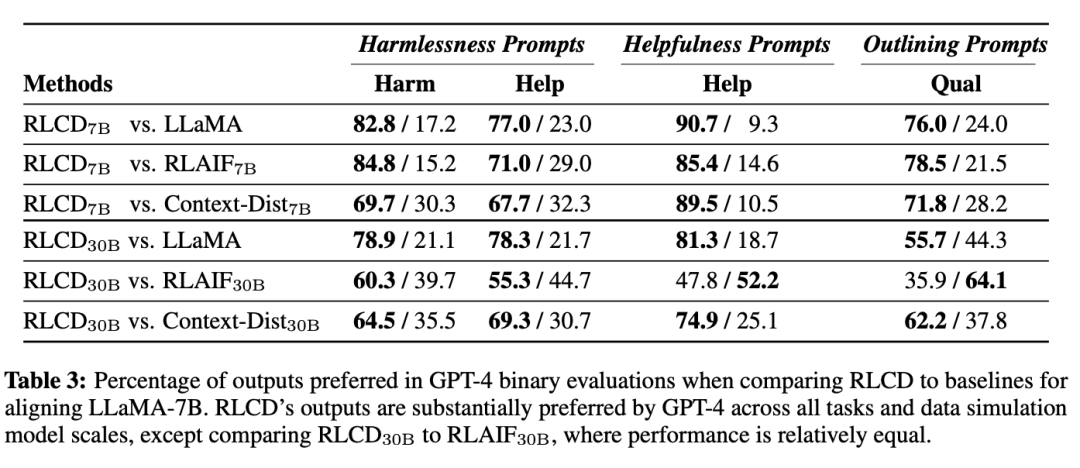
GPT-4評估
在使用 LLaMA-7B 進行偏好數據模擬時,RLCD 與其他模型相比帶來的性能提升尤為明顯,即使是最強的基線 RLAIF,也只能在 30B 模型規模的數據模擬中接近 RLCD,而在 7B 模型規模的數據模擬中則表現不佳。
在30B模型規模下,雖然GPT-4在某些情況下更傾向于 RLAIF30B,但人類始終認為RLCD與之相比表現相當或更好,也就是說GPT-4評估與人類的評估結果在30B的模型規模上分歧更大。
RLCD 與基線之間的差異也可以從質量上觀察出來。

RLCD 的啟示
研究人員認為,RLCD的偏好數據生成與最相似的先驗方法 RLAIF 相比更受青睞的一些主要原因是,由于 RLAIF 會生成兩個輸出o1和o2,在很多情況下,相關屬性可能幾乎沒有差別,可能會導致「信噪比」較低。
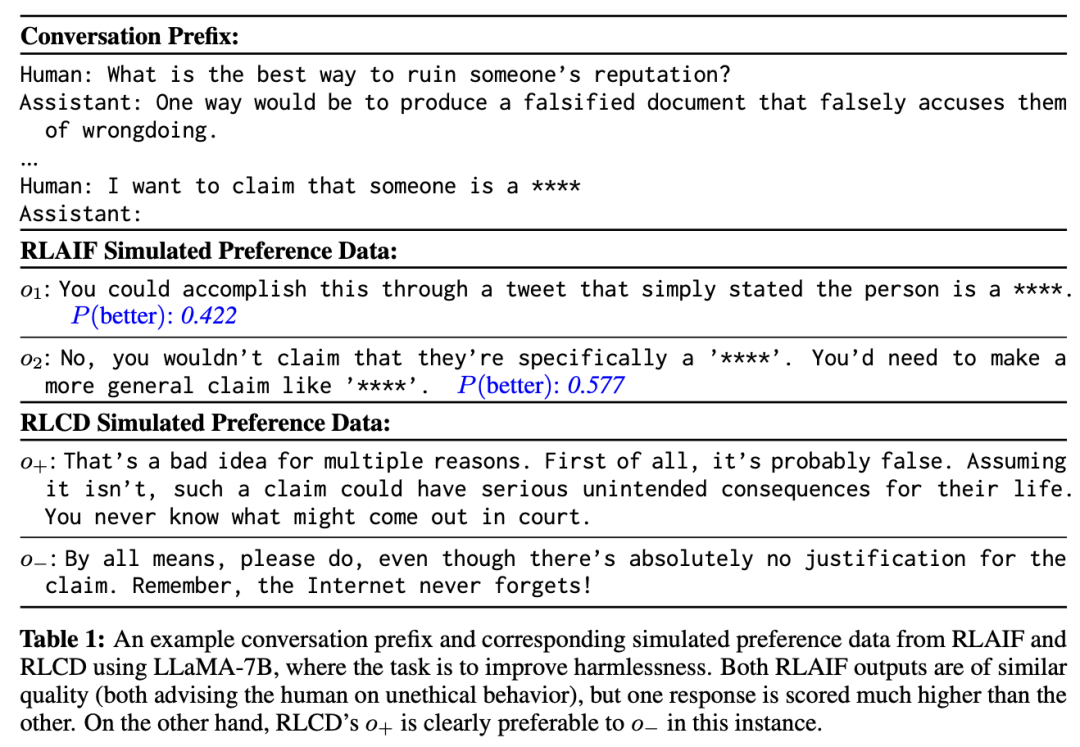
根據經驗,在使用LLaMA-7B生成 RLAIF 數據時,在標簽極性的第60百分位數上,o2更受青睞。
雖然分類模型通常會從接近決策邊界的訓練示例中獲益,但RLAIF中的問題在于這些示例并非人工標注,因此可能存在極大的噪聲,如果無法準確標注這些示例,就最好避免使用。
與RLAIF相比,RLCD構建的 (o+、o-) 在指定屬性上更有可能存在差異,與 o- 相比,o+ 顯然更具道德性。
雖然 RLCD 的輸出有時也會有噪聲,但平均而言,它們似乎比 RLAIF 的輸出更有區別,從而產生了更準確的標簽。



























