「知識型圖像問答」微調也沒用?谷歌發布搜索系統AVIS:少樣本超越有監督PALI,準確率提升三倍
在大型語言模型(LLM)的加持下,與視覺結合的多模態任務,如圖像描述、視覺問答(VQA)和開放詞匯目標識別(open-vocabulary object detection)等都取得了重大進展。
不過目前視覺語言模型(VLM)基本都只是利用圖像內的視覺信息來完成任務,在inforseek和OK-VQA等需要外部知識輔助問答的數據集上往往表現不佳。

最近谷歌發表了一個全新的自主視覺信息搜索方法AVIS,利用大型語言模型(LLM)來動態地制定外部工具的使用策略,包括調用API、分析輸出結果、決策等操作為圖像問答提供關鍵知識。

論文鏈接:https://arxiv.org/pdf/2306.08129.pdf
AVIS主要集成了三種類型的工具:
1. 從圖像中提取視覺信息的工具
2. 檢索開放世界知識和事實的網絡搜索工具
3. 檢索視覺上相似的圖像搜索工具
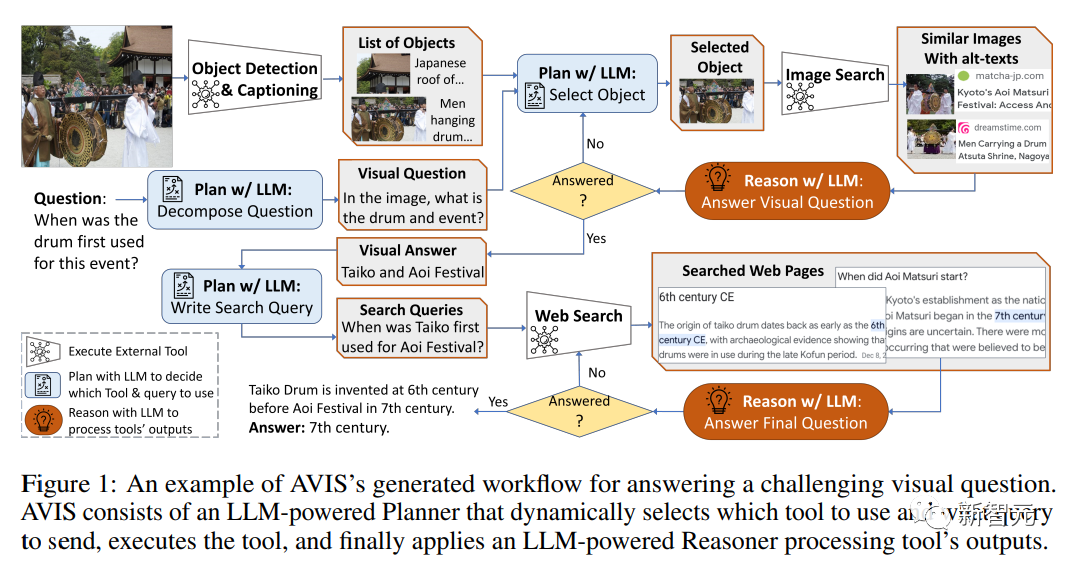
然后使用基于大型語言模型的規劃器在每個步驟中選擇一個工具和查詢結果,動態地生成問題答案。
模擬人類決策
Infoseek和OK-VQA數據集中的許多視覺問題甚至對人類來說都相當難,通常需要各種外部工具的輔助,所以研究人員選擇先進行一項用戶調研,觀察人類在解決復雜視覺問題時的解決方案。
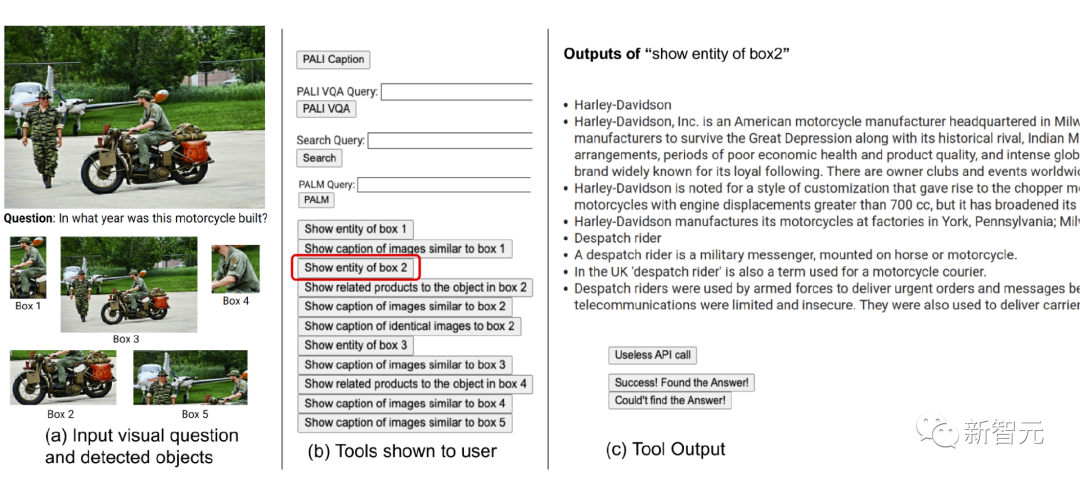
首先為用戶配備一組可用的工具集,包括PALI,PALM和網絡搜索,然后展示輸入圖像、問題、檢測到的物體裁剪圖、圖像搜索結果的鏈接知識圖譜實體、相似的圖像標題、相關的產品標題以及圖像描述。
然后研究人員對用戶的操作和輸出進行記錄,并通過兩種方式來引導系統做出回答:
1. 通過分析用戶做出的決策序列來構建轉換圖,其中包含不同的狀態,每個狀態下的可用操作集都不同。
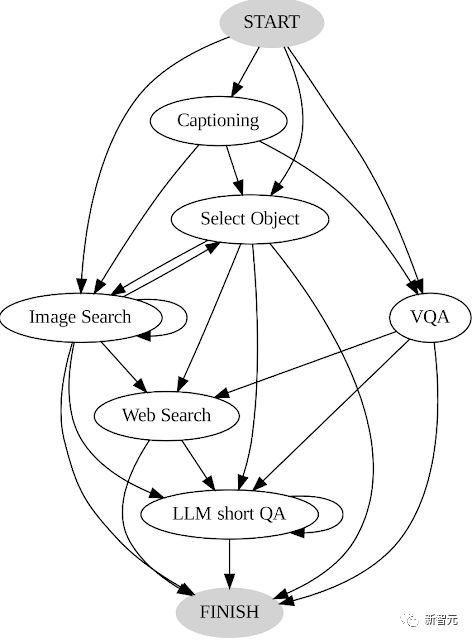
AVIS轉換圖
例如在開始狀態下,系統只能執行三個操作:PALI描述、PALI VQA或目標檢測。
2. 使用人類決策的樣例來引導規劃器(planner)和推理器(reasoner)與相關的上下文實例,來提高系統的性能和有效性。
總體框架
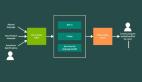
AVIS方法采用了一個動態的決策策略,旨在響應視覺信息尋求查詢。
該系統有三個主要組成部分:
1. 規劃器(planner),用來確定后續操作,包括適當的API調用以及需要處理的查詢。
2. 運行記憶(working memory)工作內存,保留了從API執行中獲得的結果信息。
3. 推理器(reasoner),用來處理API調用的輸出,可以確定所獲得的信息是否足以產生最終響應,或者是否需要額外的數據檢索。
每次需要決定使用哪個工具以及向系統發送哪些查詢時,規劃器都要執行一系列操作;基于當前狀態,規劃器還會提供潛在的后續動作。
為了解決由于潛在的動作空間可能過多,導致搜索空間過大的問題,規劃器需要參考轉換圖來消除不相關的動作,排除之前已經采取并存儲在工作記憶中的動作。

然后由規劃器從用戶研究數據中組裝出一套上下文示例,結合之前工具交互的記錄,由規劃器制定提示后輸入到語言模型中,LLM再返回一個結構化的答案,確定要激活的下一個工具以及派發的查詢。
整個設計流程可以多次調用規劃器,從而促進動態決策,逐步生成答案。

研究人員使用推理器來分析工具執行的輸出,提取有用的信息,并決定工具輸出哪個類別:提供信息的、不提供信息的或最終答案。
如果推理器返回結果是「提供答案」,則直接輸出作為最終結果,結束任務;如果結果是無信息,則退回規劃器,并基于當前狀態選擇另一個動作;如果推理器認為工具輸出是有用的,則修改狀態并將控制權轉移回規劃器,以在新狀態下做出新的決定。
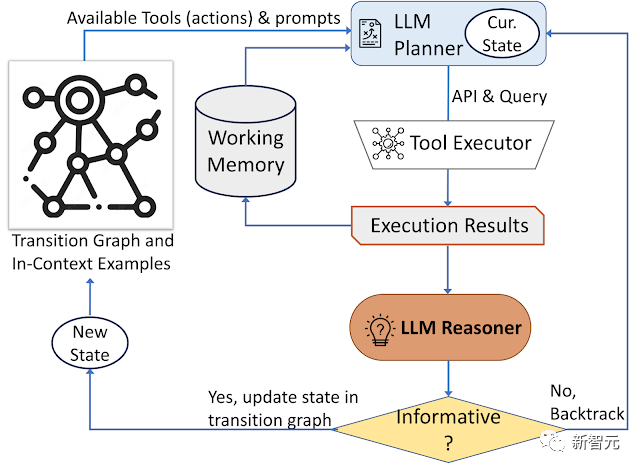
AVIS采用動態決策策略來響應視覺信息搜索查詢
實驗結果
工具集合
圖像描述模型,使用PALI 17B模型為輸入圖像和檢測到的物體裁剪圖像生成描述。
視覺問題回答模型,使用 PALI 17B VQA 模型,將圖像和問題作為輸入,并將基于文本的答案作為輸出。
物體檢測,使用在Open Images數據集的超集上訓練的物體檢測器,具體類別Google Lens API提供;使用高置信度閾值,只保留 輸入圖像中排名靠前的檢測框。
圖像搜索,利用Google Image Search來獲取與檢測到的方框的圖像裁剪相關的信息。
在進行決策時,規劃器將每條信息的利用都視為一項單獨的操作,因為每條信息可能包含數百個token,需要進行復雜的處理和推理。
OCR,在某些情況下,圖像可能包含文字內容,如街道名稱或品牌名稱,使用Google Lens API 中的光學字符識別(OCR)功能獲取文本。
網絡搜索,使用谷歌搜索API,輸入為文本查詢,輸出包括相關文檔鏈接和片段、提供直接答案的知識圖譜面板、最多五個與輸入查詢相關的問題。
實驗結果
研究人員在Infoseek和OK-VQA數據集上對AVIS框架進行了評估,從結果中可以看到,即使是健壯性非常好的視覺語言模型,如OFA和PALI模型,在Infoseek數據集上進行微調后也無法獲得高準確性。
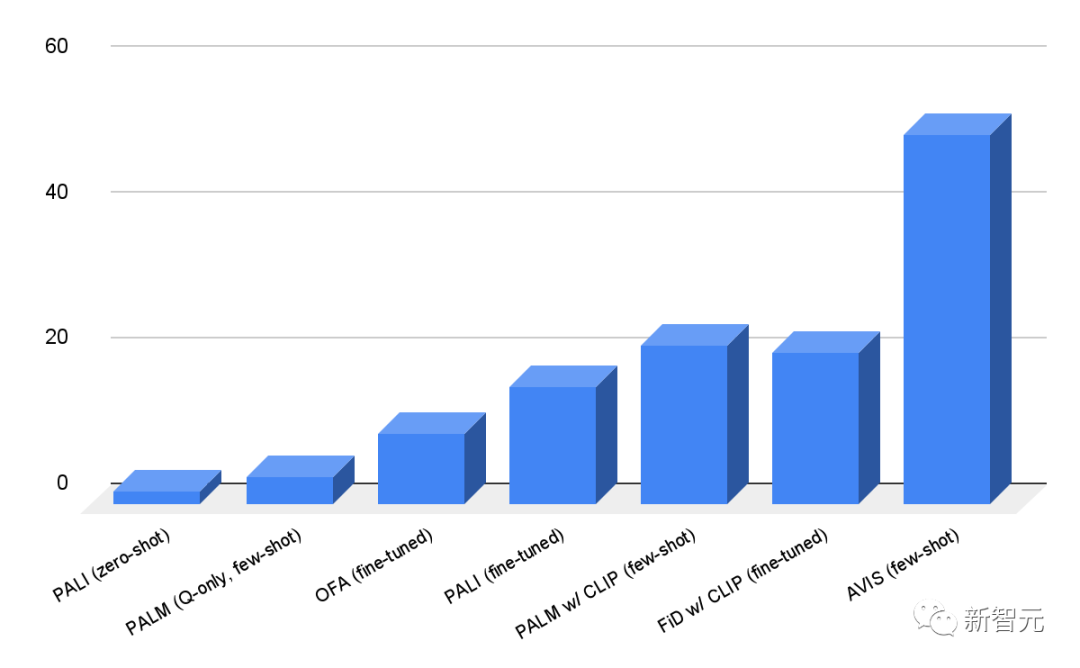
而AVIS方法在沒有微調的情況下,就實現了50.7%的準確率。
在OK-VQA數據集上,AVIS系統在few-shot設置下實現了60.2%的準確率,僅次于微調后的PALI模型。

性能上的差異可能是由于OK-VQA中的大多數問答示例依賴于常識知識而非細粒度知識,所以PALI能夠利用到在模型參數中編碼的通用知識,不需要外部知識的輔助。
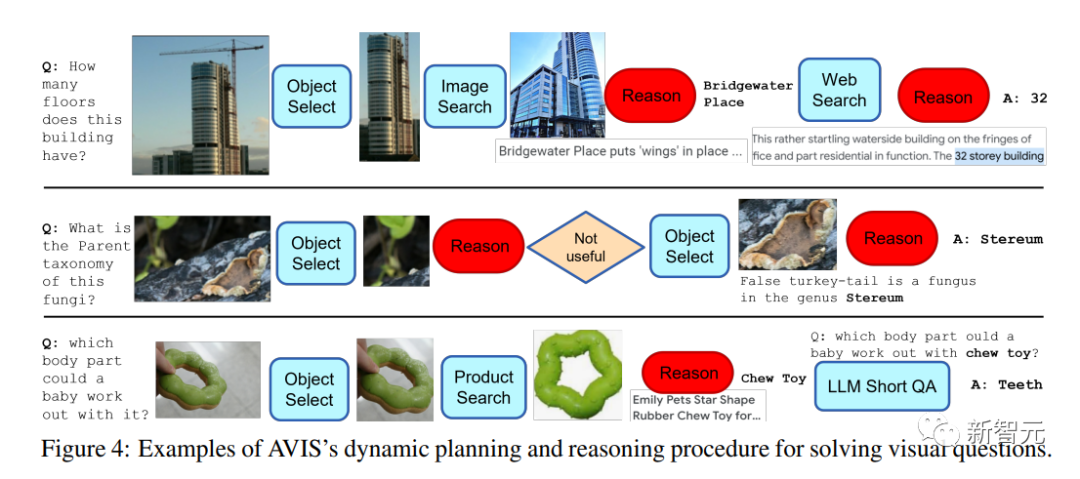
AVIS的一個關鍵特性是能夠動態地做出決策,而非執行固定的序列,從上面的樣例中可以看出AVIS在不同階段使用不同工具的靈活性。
值得注意的是,文中推理器設計使AVIS能夠識別不相關的信息,回溯到以前的狀態,并重復搜索。
例如,在關于真菌分類學的第二個例子中,AVIS最初通過選擇葉子對象做出了錯誤的決定;推理器發現與問題無關后,促使AVIS重新規劃,然后成功地選擇了與假火雞尾真菌有關的對象,從而得出了正確的答案,Stereum
結論
研究人員提出了一種新的方法AVIS,將LLM作為裝配中心,使用各種外部工具來回答知識密集型的視覺問題。
在該方法中,研究人員選擇錨定在從用戶研究中收集的人類決策數據,采用結構化的框架,使用一個基于LLM的規劃器,動態地決定工具選擇和查詢形成。
LLM驅動的推理器可以從所選工具的輸出中處理和提取關鍵信息,迭代地使用規劃器和推理器來選擇不同的工具,直到收集出回答視覺問題所需的所有必要信息。