清華大學孫茂松教授提出全新微調框架CPT準確率提升17.3%
預訓練模型在計算機視覺和語言上都取得了顯著成果,但這些語言模型有一個大問題就是訓練過程和推理過程不匹配。清華大學孫茂松團隊提出了一個全新的微調框架CPT,用顏色來遮蔽、融合圖像和語言,準確率提升17.3%,標準差降低73.8%!
預先訓練的視覺語言模型(Pre-Trained Vision-Language Models, VL-PTM)能夠同時處理語言和視覺上的信息,也是完成各種多模態任務的基礎模型。
但模型的預訓練和微調之間存在著巨大的差距,在預訓練期間,大多數VL PTM都是基于mask language modeling目標進行優化的,主要任務就是在屏蔽的詞中從跨模態上下文中恢復。
然而,在微調過程中,下游任務通常是通過將未屏蔽token的表示分類到語義標簽來完成的,在語義標簽中通常會引入特定任務的參數。這種差別阻礙了VL PTM對下游任務的適應性,因此需要大量的標記數據來優化VL-PTM對下游任務的視覺基礎能力。
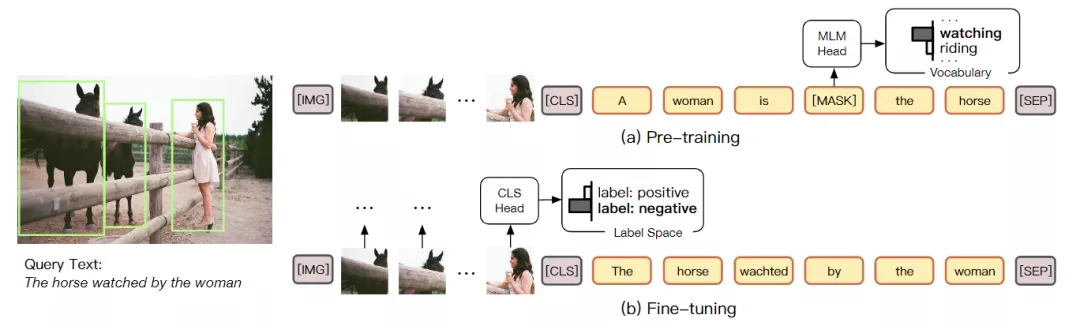
針對這個問題,清華大學的研究人員提出了一個新模型跨模態提示調節(Cross-Modal Prompt Tuning, CPT),也可以稱為Colorful Prompt Tuning。CPT是一種調整VL-PTM參數的新范式,關鍵點在于通過在圖像和文本中添加基于顏色的共同參照標記,視覺基礎可以重新形成填補空白的問題,最大限度地減少預訓練和微調之間的差距。

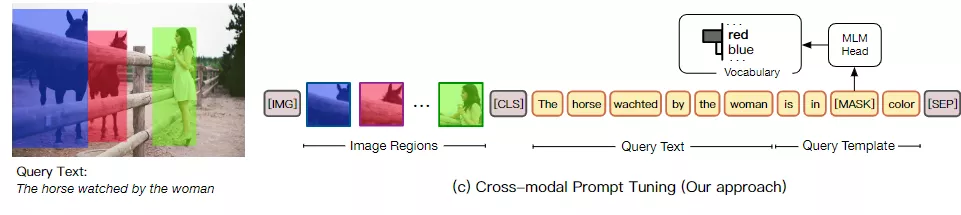
為了在圖像數據中使用自然語言表達式,CPT由兩個組件組成:(1)一個視覺子提示(visual sub-prompt),用顏色塊唯一地標記圖像區域;(2)一個文本子提示(textual sub-prompt),將查詢文本放入基于顏色的查詢模板中。然后,通過從查詢模板中的屏蔽標記恢復相應的彩色文本,可以實現目標圖像區域的顯式定位。
論文的作者是孫茂松教授,目前任清華大學人工智能研究院常務副院長、清華大學計算機學位評定分委員會主席、教育部在線教育研究中心副主任、清華大學大規模在線開放教育研究中心主任。曾任清華大學計算機系主任、黨委書記。研究方向為自然語言理解、中文信息處理、Web智能、社會計算和計算教育學等。
配備CPT后,VL-PTMs可以在沒有任何標記數據的情況下執行zero-shot visual grouding,因為VL PTMs在訓練前已經很好地學習了顏色的跨模態表示及其與其他概念(例如,對象、屬性和關系)的組合。
當有幾個或全部標記的實例可用時,CPT可以根據基于熵的目標函數對VL PTM進行進一步調整。
雖然通過基于顏色的提示將圖像和文本連接起來看著很好用,但研究人員仍然發現了其中兩個關鍵問題:(1)如何確定顏色集C的配置;(2)如何使用有限的預訓練顏色處理圖像區域的數量。
解決方法有跨模式提示搜索(Cross-modal Prompt Search)。以前在文本提示調優方面的工作表明,提示配置(例如,文本模板)對性能有重大影響。這篇文章也是對搜索跨模態提示配置(即顏色集C)進行的首次研究。
直觀地說,C應該由VL PTM最敏感的顏色組成。為了獲得顏色,一種簡單的方法是采用預訓練文本中最常見的顏色文本,其標準RGB作為civ。但該解決方案是次優的,因為這種方法在確定彩色文本時不考慮其視覺外觀,并且真實圖像中顏色的視覺外觀通常與其標準RGB不同。
所以在跨模式提示搜索中,首先確定一個全彩色文本的候選集。對于RGB空間中的每個可能顏色,將純色塊與文本子提示連接到VL PTMs中:[CLS] a photo in [MASK] color. [SEP]。然后為每個候選顏色文本獲得記錄分數。
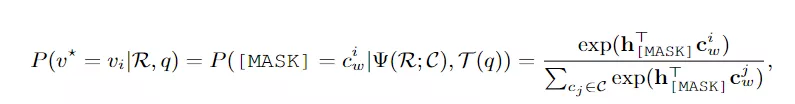
記錄得分越大,表明cv和cw之間的相關性越高,并且刪除了在任何顏色視覺外觀中都沒有排名靠前的顏色文本。最后對于每個剩余的彩色文本,其視覺外觀由最大色彩確定,并且實驗結果顯示得到的顏色配置明顯優于原始的顏色配置。
圖像區域批處理(Image Region Batching)。在視覺基礎中,圖像中區域建議的數量通常超過顏色集合C的大小(∼ 10)。此外,嚴重重疊的色塊會阻礙視覺基礎,因此需要將圖像區域分為多個批次,每個批次包含少量中度重疊的圖像區域,并分別使用視覺子提示標記每個批次。為了處理不包含目標區域的批,在解碼詞匯表中進一步引入了一個新的候選文本none,表示批中沒有目標區域。
實驗結果表明,提示微調后的 VL-PTM的性能大大優于微調后的PTM,
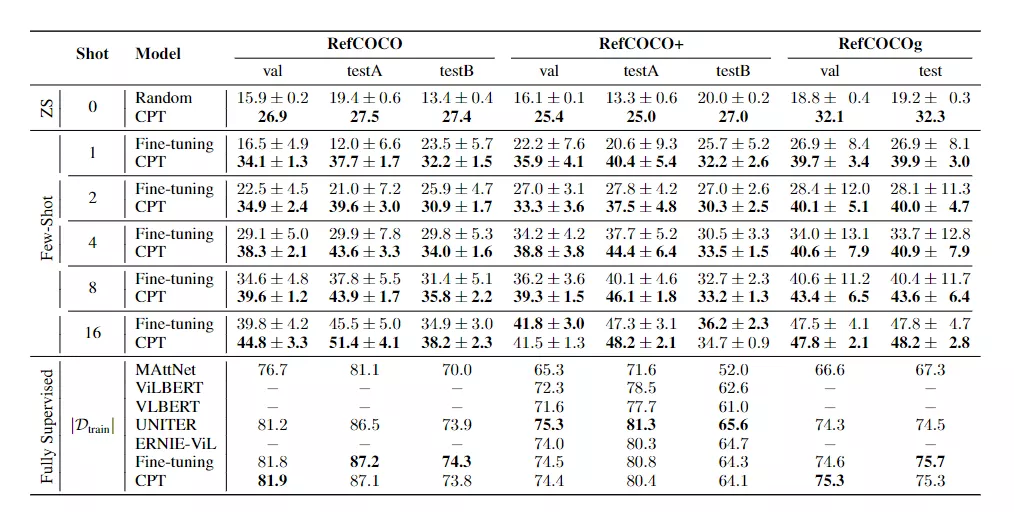
1、CPT在zero-shot 和few-shot 設置下比隨機基線和強微調基線有很大的優勢(例如,在RefCOCO評估中,one-shot 的絕對準確度平均提高17.3%)。不同的數據集和不同的訓練次數之間的改進是一致的。這表明CPT可以有效地提高VL PTM調諧的數據效率,并刺激VL PTM的視覺接地能力。
2、值得注意的是,與微調相比,CPT實現的標準偏差要小得多(例如,在RefCOCO評估中,一次試驗平均降低73.8%的相對標準偏差)。這表明,來自預訓練的連貫的調節方法可以導致更穩定的few-shot 訓練,這也是評估少鏡頭學習模型的關鍵因素。
3、可以注意到,在RefCOCO+評估中,CPT的微調性能稍遜于16 shots。原因是Ref-COCO+有更多基于顏色的表達(例如,穿著紅襯衫和藍帽子的人),這可能會干擾基于顏色的CPT。然而,在完全監督的場景中,通過更多的調優實例可以緩解這個問題,模型可以學習更好地區分查詢文本和提示模板中的顏色。
4、在完全監督的設置下,CPT實現了與強微調VL PTM相當的性能。結果表明,即使在完全監督的情況下,CPT也是VL-PTM的一種競爭性調優方法。總之,與普通的微調方法相比,CPT在zero-shot、few-shot和完全監督的視覺方面實現了優越/可比且更穩定的性能。