對抗「概念飄逸」難題!谷歌發布全新時間感知框架:圖像識別準確率提升15%
在機器學習領域,概念漂移(concept drift)問題長期困擾著研究者,即數據分布隨時間發生變化,使得模型難以持續有效。
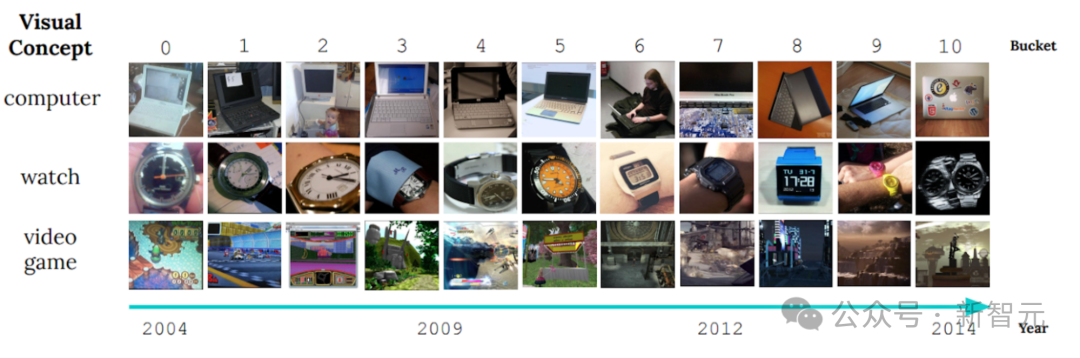
一個顯著的例子是CLEAR非穩態學習基準的圖像展示,它揭示了物體視覺特征在十年間發生的顯著變化。
這種現象被稱為「緩慢的概念漂移」,它對物體分類模型提出了嚴峻的挑戰。當物體的外觀或屬性隨著時間的推移而改變時,如何確保模型能夠適應這種變化并持續準確地進行分類,成為了研究者關注的焦點。
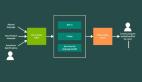
近日,針對這一挑戰,Google AI的研究人員提出了一種優化驅動的方法MUSCATEL(Multi-Scale Temporal Learning) ,顯著提升了模型在大型、動態數據集中的表現。該工作發表于AAAI2024。

論文地址:https://arxiv.org/abs/2212.05908
目前,針對概率漂移的主流方法是在線學習和持續學習(online and continue learning)。
這些方法的核心思想是,通過不斷更新模型以適應最新數據,保持模型的時效性。然而,這種做法存在兩個核心難題。
首先,它們往往只關注最新數據,導致過去數據中蘊含的有價值信息被忽略。其次,這些方法假設所有數據實例的貢獻隨時間均勻衰減,這與現實世界的實際情況不符。
MUSCATEL方法能有效解決這些問題,它訓練實例的重要性分配分數,優化模型在未來實例中的表現。
為此,研究人員引入了一個輔助模型,結合實例及其年齡生成分數。輔助模型與主模型協同學習,解決了兩個核心難題。
該方法在實際應用中表現優異,在一項涵蓋3900萬張照片、持續9年的大型真實數據集實驗中,相較于其他穩態學習的基線方法,準確率提升了15%。
同時在兩個非穩態學習數據集及持續學習環境中,也展現出優于SOTA方法的效果。
概念漂移對有監督學習的挑戰
為了研究概念漂移對有監督學習的挑戰,研究人員在照片分類任務中比較了離線訓練(offline training)和持續訓練(continue training)兩種方法,使用約3,900萬張10年間的社交媒體照片。
如下圖所示,離線訓練模型雖然初始性能高,但隨時間推移準確性下降,因災難遺忘(catastrophic forgetting)導致對早期數據理解減少。
相反,持續訓練模型雖初始性能較低,但對舊數據依賴較低,測試期間退化更快。
這表明數據隨時間演變,兩模型的適用性降低。概念漂移對有監督學習構成挑戰,需持續更新模型以適應數據變化。

MUSCATEL
MUSCATEL是一種創新的方法,旨在解決緩慢概念漂移這一難題。它通過巧妙結合離線學習與持續學習的優勢,旨在減少模型在未來的性能衰減。
在龐大的訓練數據面前,MUSCATEL展現了其獨特的魅力。它不僅僅依賴傳統的離線學習,更在此基礎上審慎地調控和優化過去數據的影響,為模型未來的表現打下堅實基礎。
為了進一步提升主模型在新數據上的性能,MUSCATEL引入了一個輔助模型。
根據下圖中的優化目標,訓練輔助模型根據每個數據點的內容和年齡為其分配權重。這一設計使得模型能夠更好地適應未來數據的變化,保持持續的學習能力。

為了使輔助模型與主模型協同進化,MUSCATEL還采用了元學習(meta-learning)的策略。
這一策略的關鍵在于將樣本實例與年齡的貢獻進行有效分離,并通過結合多種固定衰變時間尺度來設定權重,如下圖所示。

此外,MUSCATEL還學習將每個實例“分配”到最適合的時間尺度上,以實現更精確的學習。
實例權重評分
如下圖所示,在CLEAR物體識別挑戰中,學習的輔助模型成功調整了物體的權重:新外觀的物體權重增加,舊外觀的物體權重減少。

通過基于梯度的特征重要性評估,可以發現輔助模型聚焦于圖像中的主體,而非背景或與實例年齡無關的特征,從而證明了其有效性。

大規模照片分類任務取得顯著突破
在YFCC100M數據集上研究了大規模照片分類任務(PCAT),利用前五年的數據作為訓練集,后五年的數據作為測試集。
相較于無加權基線以及其他魯棒學習技術,MUSCATEL方法展現出了明顯的優勢。
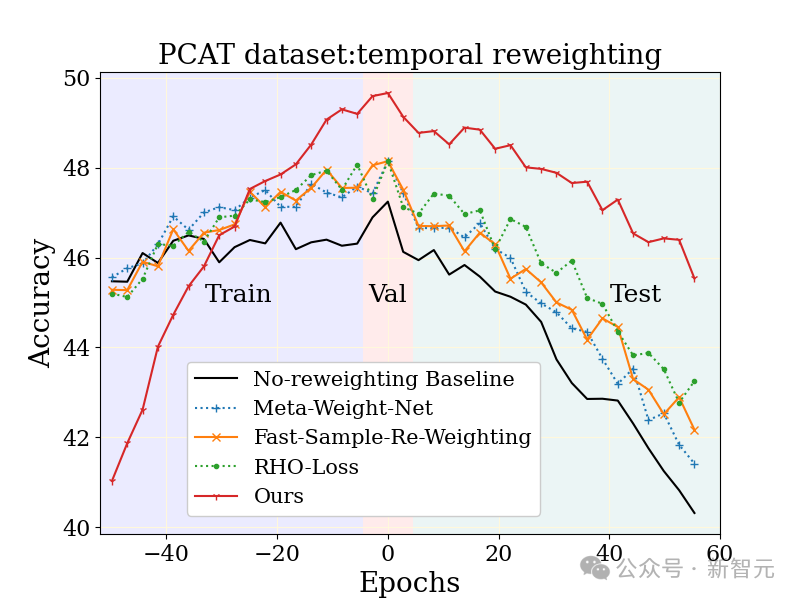
值得注意的是,MUSCATEL方法有意識地調整了對遙遠過去數據的準確性,以換取測試期間性能的顯著提升。這一策略不僅優化了模型對于未來數據的適應能力,同時還在測試期間表現出較低的退化程度。
跨數據集驗證廣泛使用性
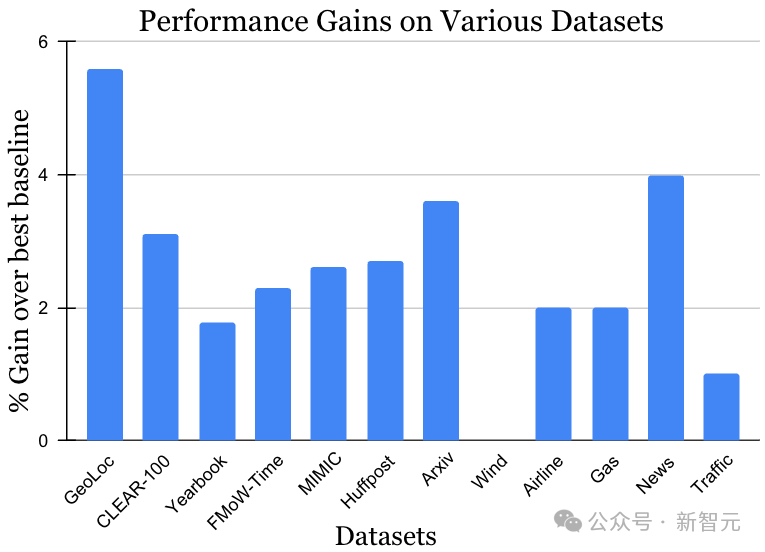
非穩態學習挑戰的數據集涵蓋了多種數據來源和模式,包括照片、衛星圖像、社交媒體文本、醫療記錄、傳感器讀數和表格數據,數據規模也從10k到3900萬實例不等。值得注意的是,每個數據集之前的最優方法可能各有千秋。然而,如下圖所示,在數據與方法均存在多樣性的背景下,MUSCATEL方法均展現出了顯著的增益效果。這一結果充分證明了MUSCATEL的廣泛適用性。
拓展持續學習算法,應對大規模數據處理挑戰
當面對堆積如山的大規模數據時,傳統的離線學習方法可能會感到力不從心。
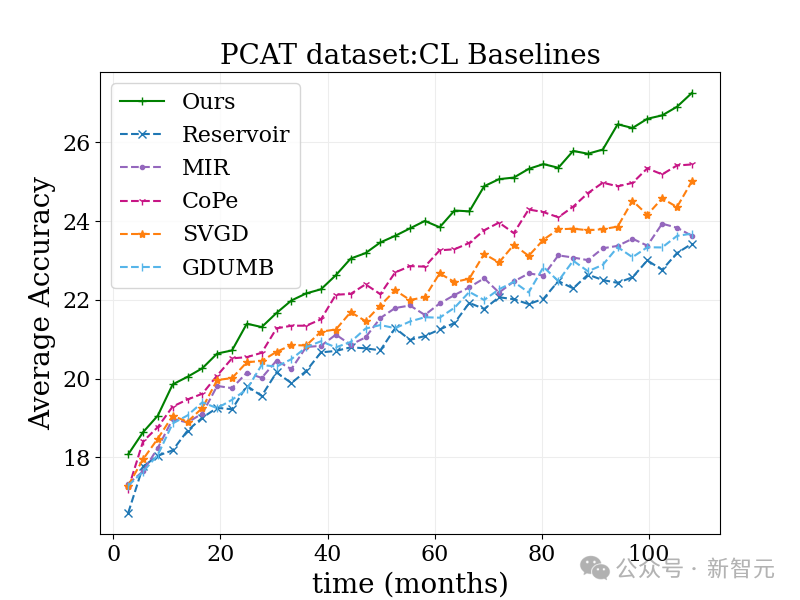
考慮到這個問題,研究團隊巧妙地調整了一種受持續學習啟發的方法,讓它輕松適應大規模數據的處理。
這個方法很簡單,就是在每一批數據上加上一個時間權重,然后順序地更新模型。
雖然這樣做還是有一些小限制,比如模型更新只能基于最新的數據,但效果卻出奇地好!
在下圖的照片分類的基準測試中,這個方法表現得比傳統的持續學習算法和其他各種算法都要出色。
而且,由于它的思路與許多現有的方法都很搭,預計與其他方法結合后,效果會更加驚艷!
總的來說,研究團隊成功將離線與持續學習相結合,破解了長期困擾業界的數據漂移問題。
這一創新策略不僅顯著緩解了模型的「災難遺忘」現象,還為大規模數據持續學習的未來發展開辟了新的道路,為整個機器學習領域注入了新的活力。