發布一天,Code Llama代碼能力突飛猛進,微調版HumanEval得分超GPT-4
昨天,Meta 開源專攻代碼生成的基礎模型 Code Llama,可免費用于研究以及商用目的。
Code Llama 系列模型有三個參數版本,參數量分別為 7B、13B 和 34B。并且支持多種編程語言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C# 和 Bash。
Meta 提供的 Code Llama 版本包括:
- Code Llama,基礎代碼模型;
- Code Llama-Python,Python 微調版;
- Code Llama-Instruct,自然語言指令微調版。
就其效果來說,Code Llama 的不同版本在 HumanEval 和 MBPP 數據集上的一次生成通過率(pass@1)都超越 GPT-3.5。
此外,Code Llama 的「Unnatural」34B 版本在 HumanEval 數據集上的 pass@1 接近了 GPT-4(62.2% vs 67.0%)。不過 Meta 沒有發布這個版本,但通過一小部分高質量編碼數據的訓練實現了明顯的效果改進。
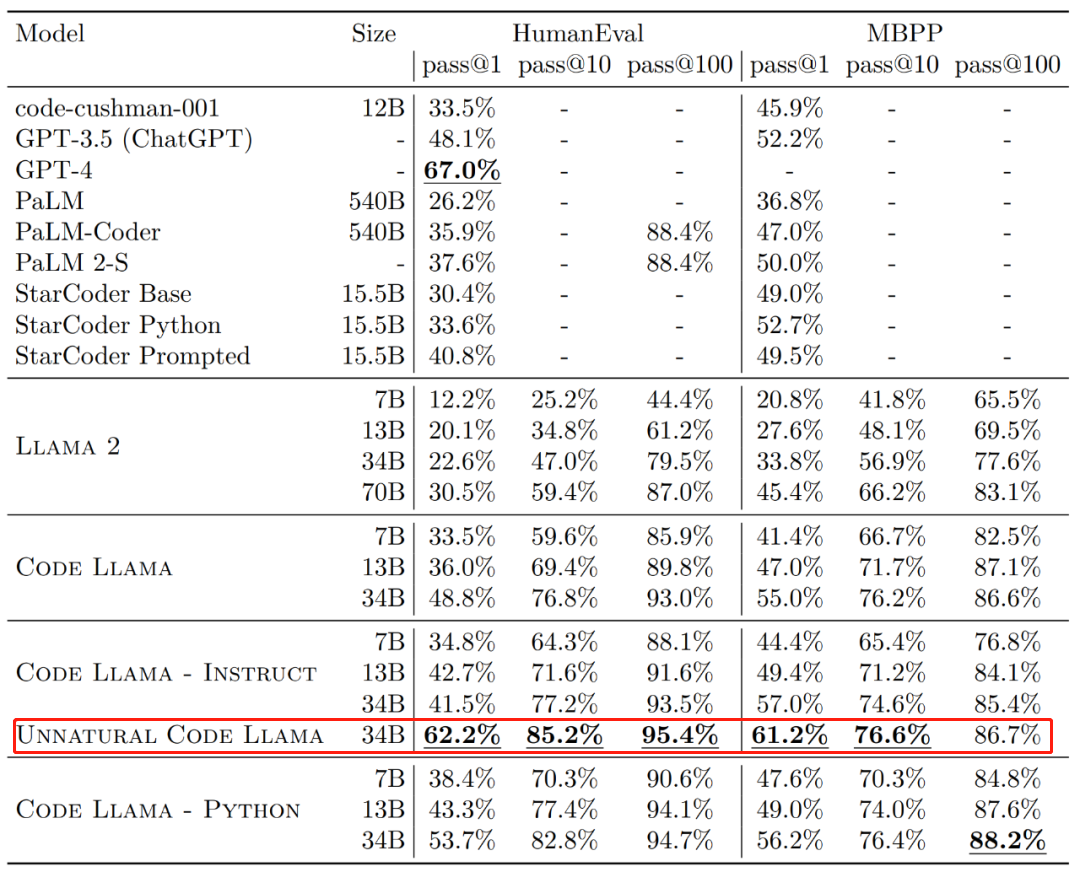
圖源:https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
一天剛過,就有研究者向 GPT-4 發起了挑戰。他們來自 Phind(一個組織,旨在構造一款為開發人員而生的AI 搜索引擎),該研究用微調的 Code Llama-34B 在 HumanEval 評估中擊敗了 GPT-4。
Phind 聯合創始人 Michael Royzen 表示:「這只是一個早期實驗,旨在重現(并超越)Meta 論文中的「Unnatural Code Llama」結果。將來,我們將擁有不同 CodeLlama 模型的專家組合,我認為這些模型在現實世界的工作流程中將具有競爭力。」

兩個模型均已開源:

研究者在 Huggingface 上發布了這兩個模型,大家可以前去查看。
- Phind-CodeLlama-34B-v1:https://huggingface.co/Phind/Phind-CodeLlama-34B-v1
- Phind-CodeLlama-34B-Python-v1:https://huggingface.co/Phind/Phind-CodeLlama-34B-Python-v1
接下來我們看看這項研究是如何實現的。
微調 Code Llama-34B 擊敗 GPT-4
我們先看結果。這項研究用 Phind 內部數據集對 Code Llama-34B 和 Code Llama-34B-Python 進行了微調,分別得到兩個模型 Phind-CodeLlama-34B-v1 以及 Phind-CodeLlama-34B-Python-v1。
新得到的兩個模型在 HumanEval 上分別實現了 67.6% 和 69.5% pass@1。
作為比較,CodeLlama-34B pass@1 為 48.8%;CodeLlama-34B-Python pass@1 為 53.7%。
而 GPT-4 在 HumanEval 上 pass@1 為 67%(OpenAI 在今年 3 月份發布的「GPT-4 Technical Report」中公布的數據)。
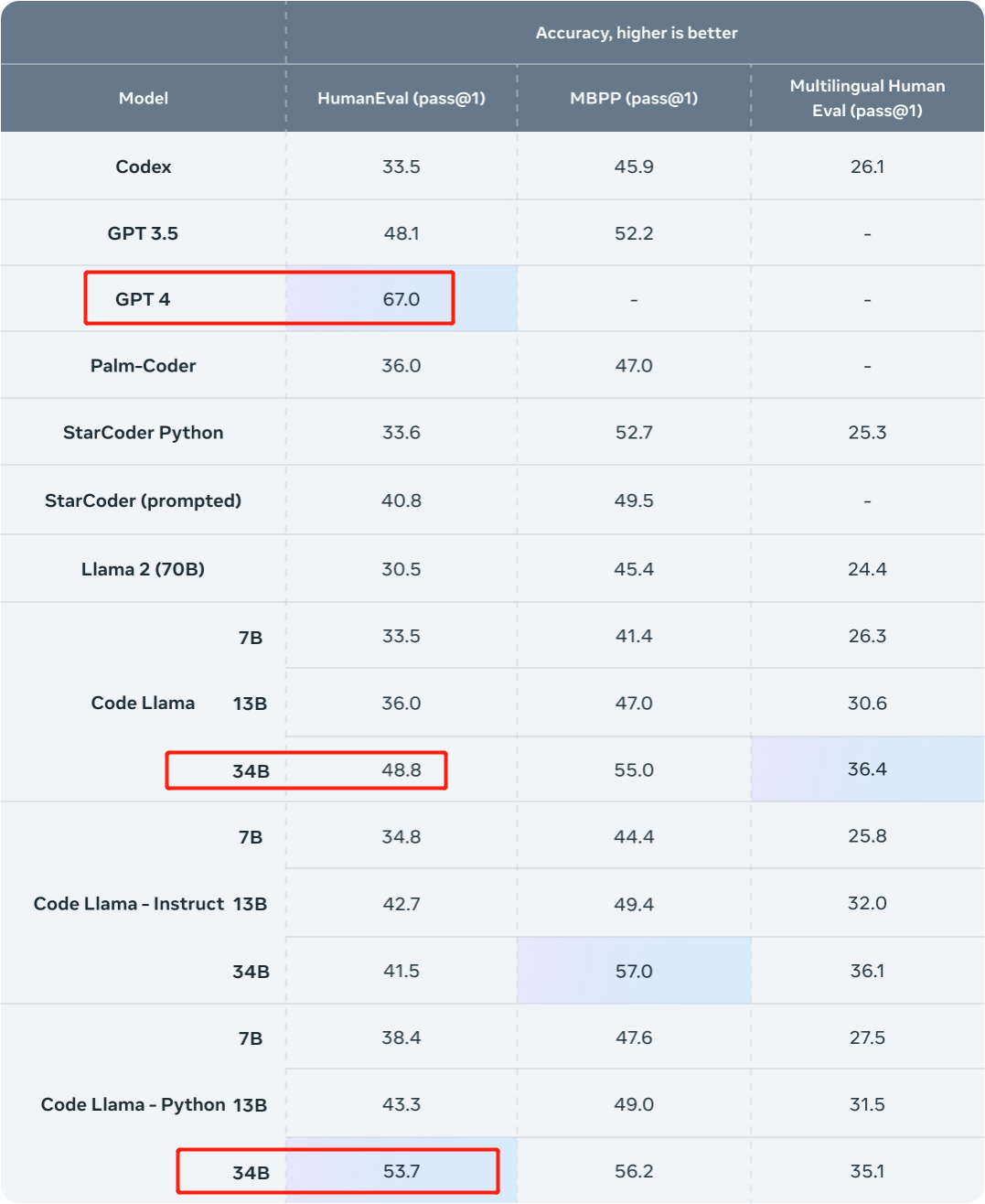
圖源:https://ai.meta.com/blog/code-llama-large-language-model-coding/
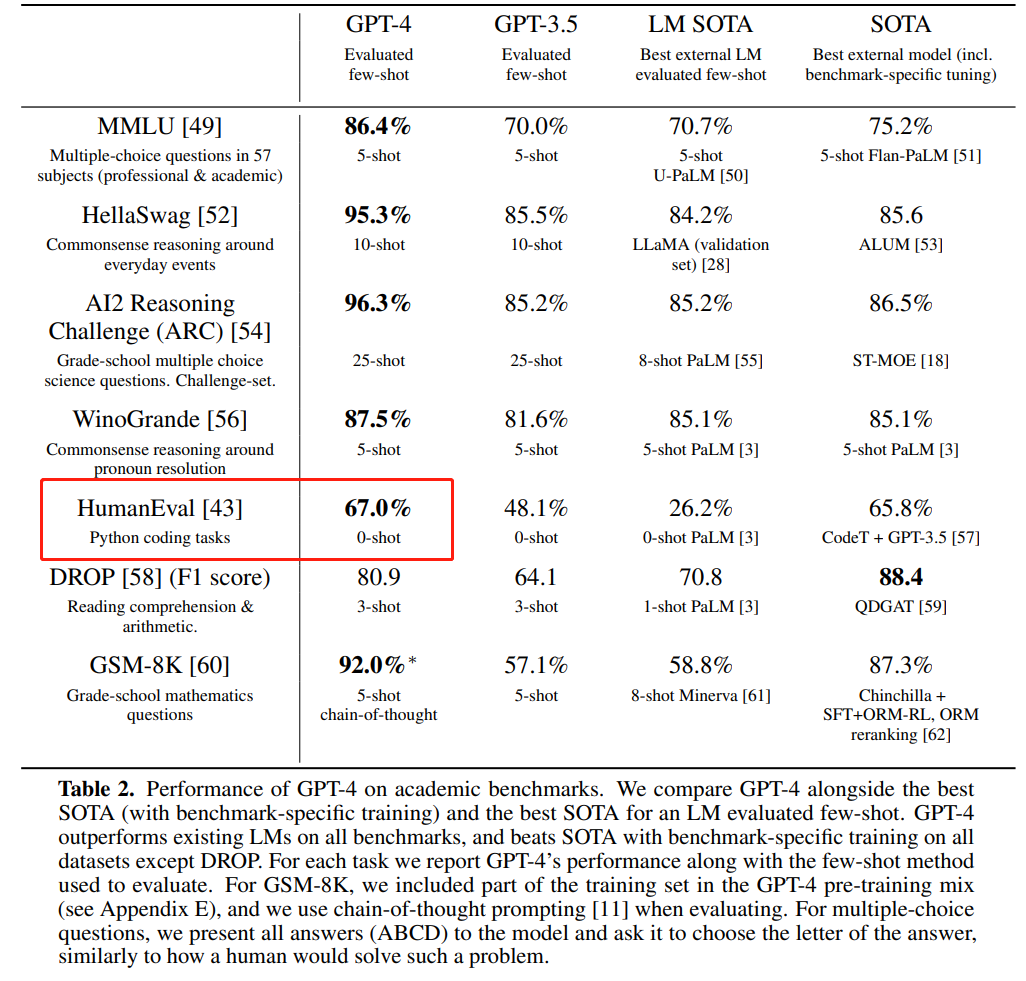
圖源:https://cdn.openai.com/papers/gpt-4.pdf
談到微調,自然少不了數據集,該研究在包含約 8 萬個高質量編程問題和解決方案的專有數據集上對 Code Llama-34B 和 Code Llama-34B-Python 進行了微調。
該數據集沒有采用代碼補全示例,而是采用指令 - 答案對,這與 HumanEval 數據結構不同。之后該研究對 Phind 模型進行了兩個 epoch 的訓練,總共有約 16 萬個示例。研究者表示,訓練中沒有使用 LoRA 技術,而是采用了本地微調。
此外,該研究還采用了 DeepSpeed ZeRO 3 和 Flash Attention 2 技術,他們在 32 個 A100-80GB GPU 上、耗時三個小時,訓練完這些模型,序列長度為 4096 個 token。
此外,該研究還將 OpenAI 的去污染(decontamination)方法應用于數據集,使模型結果更加有效。
眾所周知,即便是非常強大的 GPT-4,也會面臨數據污染的困境,通俗一點的講就是訓練好的模型可能已經接受評估數據的訓練。
這個問題對 LLM 非常棘手,舉例來說,在評估一個模型性能的過程中,為了進行科學可信的評估,研究者必須檢查用于評估的問題是否在模型的訓練數據中。如果是的話,模型就可以記住這些問題,在評估模型時,顯然會在這些特定問題上表現更好。
這就像一個人在考試之前就已經知道了考試問題。
為了解決這個問題,OpenAI 在公開的 GPT-4 技術文檔《 GPT-4 Technical Report 》中披露了有關 GPT-4 是如何評估數據污染的。他們公開了量化和評估這種數據污染的策略。
具體而言,OpenAI 使用子串匹配來測量評估數據集和預訓練數據之間的交叉污染。評估和訓練數據都是通過刪除所有空格和符號,只保留字符(包括數字)來處理的。
對于每個評估示例,OpenAI 隨機選擇三個 50 個字符的子字符串(如果少于 50 個字符,則使用整個示例)。如果三個采樣的評估子字符串中的任何一個是處理后的訓練樣例的子字符串,則確定匹配。
這將產生一個受污染示例的列表,OpenAI 丟棄這些并重新運行以獲得未受污染的分數。但這種過濾方法有一些局限性,子串匹配可能導致假陰性(如果評估和訓練數據之間有微小差異)以及假陽性。因而,OpenAI 只使用評估示例中的部分信息,只利用問題、上下文或等效數據,而忽略答案、回應或等效數據。在某些情況下,多項選擇選項也被排除在外。這些排除可能導致假陽性增加。
關于這部分內容,感興趣的讀者可以參考論文了解更多。
論文地址:https://cdn.openai.com/papers/gpt-4.pdf
不過,Phind 在對標 GPT-4 時使用的 HumanEval 分數存在一些爭議。有人說,GPT-4 的最新測評分數已經達到了 85%。但 Phind 回復說,得出這個分數的相關研究并沒有進行污染方面的研究,無法確定 GPT-4 在接受新一輪測試時是否看到過 HumanEval 的測試數據。再考慮到最近一些有關「GPT-4 變笨」的研究,所以用原始技術報告中的數據更為穩妥。

不過,考慮到大模型評測的復雜性,這些測評結果能否反映模型的真實能力依然是一個有爭議的問題。大家可以下載模型后自行體驗。
參考鏈接:
- https://benjaminmarie.com/the-decontaminated-evaluation-of-gpt-4/
- https://www.phind.com/blog/code-llama-beats-gpt4