多篇論文入選Interspeech 2023 火山語(yǔ)音有效解決多類(lèi)實(shí)踐問(wèn)題
日前,火山語(yǔ)音團(tuán)隊(duì)多篇論文入選Interspeech 2023,內(nèi)容涵蓋短視頻語(yǔ)音識(shí)別、跨語(yǔ)言音色與風(fēng)格以及口語(yǔ)流利度評(píng)估等多個(gè)應(yīng)用方向的創(chuàng)新突破。Interspeech作為國(guó)際語(yǔ)音通信協(xié)會(huì)ISCA組織的語(yǔ)音研究領(lǐng)域的頂級(jí)會(huì)議之一,也被稱為全球最大的綜合性語(yǔ)音信號(hào)處理盛會(huì),受到全球語(yǔ)言領(lǐng)域人士的廣泛關(guān)注。

Interspeech2023活動(dòng)現(xiàn)場(chǎng)
基于隨機(jī)語(yǔ)句串聯(lián)的數(shù)據(jù)增強(qiáng)改進(jìn)短視頻語(yǔ)音識(shí)別(Random Utterance Concatenation Based Data Augmentation for Improving Short-video Speech Recognition)
一般來(lái)說(shuō),端到端自動(dòng)語(yǔ)音識(shí)別(ASR)框架的限制之一,就是如果訓(xùn)練和測(cè)試語(yǔ)句的長(zhǎng)度不匹配,其性能可能會(huì)受到影響。在該論文中,火山語(yǔ)音團(tuán)隊(duì)提出了一種基于即時(shí)隨機(jī)語(yǔ)句串聯(lián)(RUC)的數(shù)據(jù)增強(qiáng)方法作為前端數(shù)據(jù)增強(qiáng),以減輕短視頻ASR任務(wù)中訓(xùn)練和測(cè)試語(yǔ)句長(zhǎng)度不匹配的問(wèn)題。
具體而言,團(tuán)隊(duì)得出這樣的創(chuàng)新實(shí)踐主要來(lái)自以下觀察:通常人工轉(zhuǎn)錄的訓(xùn)練語(yǔ)句在短視頻自發(fā)語(yǔ)音中要短很多(平均約3秒),相比而言從語(yǔ)音活動(dòng)檢測(cè)前端生成的測(cè)試語(yǔ)句要長(zhǎng)得多(平均約10秒),所以這種不匹配可能會(huì)導(dǎo)致性能不佳。
“對(duì)此,我們使用了來(lái)自15種語(yǔ)言的多類(lèi)ASR模型進(jìn)行了實(shí)證,這些語(yǔ)言的數(shù)據(jù)集范圍從1,000小時(shí)到30,000小時(shí)不等。在模型微調(diào)階段,還即時(shí)加入采樣多條數(shù)據(jù)后并拼接的數(shù)據(jù),相比于沒(méi)有增強(qiáng)過(guò)的數(shù)據(jù),此方法在所有語(yǔ)言上平均達(dá)到了5.72%的相對(duì)詞錯(cuò)誤率降低。”火山語(yǔ)音團(tuán)隊(duì)表示。

測(cè)試集上長(zhǎng)句的 WER 通過(guò) RUC 訓(xùn)練過(guò)后顯著下降(藍(lán)色 vs. 紅色)
根據(jù)實(shí)驗(yàn)觀察,所提出的RUC方法明顯改善了長(zhǎng)語(yǔ)句的識(shí)別,而短語(yǔ)句的性能則沒(méi)有下降。通過(guò)進(jìn)一步的分析,團(tuán)隊(duì)發(fā)現(xiàn)所提出的數(shù)據(jù)增強(qiáng)方法可以使ASR模型對(duì)于長(zhǎng)度歸一化的變化變得不太敏感,這或許意味著ASR模型對(duì)于多樣環(huán)境更具魯棒性。總結(jié)來(lái)說(shuō),RUC數(shù)據(jù)增強(qiáng)方法雖然實(shí)操簡(jiǎn)單,但效果相當(dāng)顯著。
基于語(yǔ)音和韻律自監(jiān)督方法的流利度打分(Phonetic and Prosody-aware Self-supervised Learning Approach for Non-native Fluency Scoring)
口語(yǔ)的流利程度是評(píng)價(jià)二語(yǔ)學(xué)習(xí)者語(yǔ)言能力的重要維度之一。流利的發(fā)音主要反映在輕松正常發(fā)出語(yǔ)音的同時(shí)很少伴隨停頓、猶豫或自我糾正等異常現(xiàn)象,因?yàn)榇蠖鄶?shù)二語(yǔ)學(xué)習(xí)者與母語(yǔ)者相比,通常會(huì)表現(xiàn)出較慢的語(yǔ)速以及更頻繁的停頓。對(duì)此火山語(yǔ)音團(tuán)隊(duì)提出了一種基于語(yǔ)音和韻律相關(guān)的自監(jiān)督建模方法用于口語(yǔ)流利度打分。
具體來(lái)說(shuō),在預(yù)訓(xùn)練階段,需要對(duì)模型的輸入序列特征(聲學(xué)特征、音素id、音素時(shí)長(zhǎng))進(jìn)行掩碼,將掩碼后的特征送入模型,利用上下文相關(guān)的編碼器根據(jù)時(shí)序信息來(lái)還原掩碼部分的音素id和音素時(shí)長(zhǎng)信息,從而模型具有更強(qiáng)大的語(yǔ)音和韻律表征能力。該方案將序列建模框架中原始時(shí)長(zhǎng)、音素和聲學(xué)信息這三種特征進(jìn)行掩碼重構(gòu),讓機(jī)器自動(dòng)去學(xué)習(xí)上下文的語(yǔ)音和時(shí)長(zhǎng)表征,更好用于流利度打分。

這種基于語(yǔ)音和韻律的自監(jiān)督學(xué)習(xí)方法超過(guò)了領(lǐng)域內(nèi)其他方法,在內(nèi)部測(cè)試集上機(jī)器預(yù)測(cè)結(jié)果和人類(lèi)專家打分之間相關(guān)性達(dá)到了0.833,與專家和專家之間的相關(guān)性 0.831持平。在開(kāi)源數(shù)據(jù)集上,機(jī)器預(yù)測(cè)結(jié)果和人類(lèi)專家打分之間相關(guān)性達(dá)到了0.835,性能超越過(guò)去在該任務(wù)上提出的一些自監(jiān)督方法。應(yīng)用場(chǎng)景方面,該方法可被應(yīng)用于有流利度自動(dòng)評(píng)估的需求場(chǎng)景中,例如口語(yǔ)考試以及各種在線口語(yǔ)練習(xí)等。
解耦非母語(yǔ)語(yǔ)音在發(fā)音評(píng)估中的貢獻(xiàn)(Disentangling the Contribution of Non-native Speech in Automated Pronunciation Assessment)
非母語(yǔ)發(fā)音評(píng)估的一個(gè)基本思想就是量化學(xué)習(xí)者發(fā)音與母語(yǔ)者發(fā)音的偏差,因此早期用于發(fā)音評(píng)測(cè)的聲學(xué)模型通常僅僅使用目的語(yǔ)的數(shù)據(jù)進(jìn)行訓(xùn)練,但最近的一些研究開(kāi)始將非母語(yǔ)語(yǔ)音數(shù)據(jù)納入模型訓(xùn)練。將非母語(yǔ)語(yǔ)音納入二語(yǔ)ASR 與非母語(yǔ)評(píng)估或發(fā)音錯(cuò)誤檢測(cè)中的目的存在根本區(qū)別:前者的目標(biāo)是盡可能使模型適應(yīng)非母語(yǔ)數(shù)據(jù)以達(dá)到最優(yōu) ASR 性能;后者則需要平衡兩個(gè)看似相悖的需求,即在非母語(yǔ)語(yǔ)音的較高識(shí)別精度以及對(duì)非母語(yǔ)發(fā)音的發(fā)音水平實(shí)現(xiàn)客觀的評(píng)估。
基于此,火山語(yǔ)音團(tuán)隊(duì)旨在從兩個(gè)不同角度,即對(duì)齊精度和評(píng)估表現(xiàn),研究非母語(yǔ)語(yǔ)音在發(fā)音評(píng)估中的貢獻(xiàn),從而設(shè)計(jì)了不同的數(shù)據(jù)組合和訓(xùn)練聲學(xué)模型時(shí)的文本轉(zhuǎn)錄形式,如上圖所示。
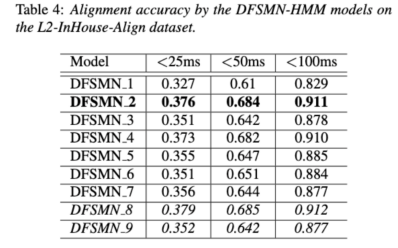
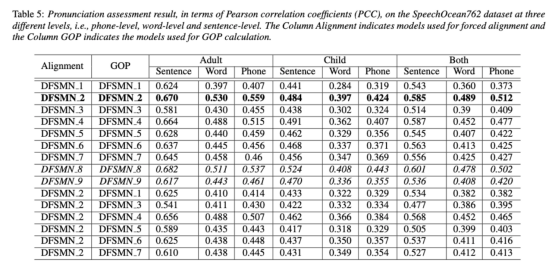
上述兩個(gè)表格分別展現(xiàn)了不同組合的聲學(xué)模型在對(duì)齊精度和評(píng)估中的性能。實(shí)驗(yàn)結(jié)果表明,在聲學(xué)模型訓(xùn)練期間僅使用帶有人工標(biāo)注的音素序列的非母語(yǔ)數(shù)據(jù),可以實(shí)現(xiàn)非母語(yǔ)語(yǔ)音的對(duì)齊以及發(fā)音評(píng)估的最高準(zhǔn)確度。具體來(lái)說(shuō),在訓(xùn)練中將一半母語(yǔ)數(shù)據(jù)和一半非母語(yǔ)數(shù)據(jù)(人工標(biāo)注的音素序列)混合可能會(huì)稍差,但可以媲美僅使用非母語(yǔ)數(shù)據(jù)與人工標(biāo)注的音素序列。
此外,上述這種混合情況在母語(yǔ)數(shù)據(jù)的發(fā)音評(píng)估上表現(xiàn)更好。在低資源條件下,與僅使用母語(yǔ)數(shù)據(jù)進(jìn)行聲學(xué)模型訓(xùn)練相比,無(wú)論使用哪種文本轉(zhuǎn)錄類(lèi)型,添加10小時(shí)的非母語(yǔ)數(shù)據(jù)都可以顯著提高對(duì)齊準(zhǔn)確性和評(píng)估性能,該研究對(duì)于語(yǔ)音評(píng)估領(lǐng)域數(shù)據(jù)的運(yùn)用具有指導(dǎo)性意義。
在端到端語(yǔ)音識(shí)別通過(guò)非尖峰的CTC優(yōu)化幀分類(lèi)器解決時(shí)間戳問(wèn)題(Improving Frame-level Classifier for Word Timings with Non-peaky CTC in End-to-End Automatic Speech Recognition)
自動(dòng)語(yǔ)音識(shí)別(ASR)領(lǐng)域的端到端系統(tǒng)已經(jīng)展示出與混合系統(tǒng)相媲美的性能。作為ASR的附帶產(chǎn)物,時(shí)間戳在許多應(yīng)用中都是至關(guān)重要的,特別在字幕生成和計(jì)算輔助發(fā)音訓(xùn)練等場(chǎng)景,本論文旨在優(yōu)化端到端系統(tǒng)中的幀級(jí)分類(lèi)器來(lái)獲取時(shí)間戳。對(duì)此團(tuán)隊(duì)引入使用CTC(connectionist temporal classification)損失來(lái)訓(xùn)練幀級(jí)分類(lèi)器,并且引入標(biāo)簽先驗(yàn)的信息使得CTC的尖峰現(xiàn)象有所緩解,還將梅爾濾波器與ASR編碼器的輸出相結(jié)合,作為輸入特征。
在內(nèi)部的中文實(shí)驗(yàn)上,該方法在單詞時(shí)間戳200ms準(zhǔn)確性上達(dá)到了95.68%/94.18%,而傳統(tǒng)混合系統(tǒng)僅為93.0%/90.22%。此外,相對(duì)于之前的端到端方法,團(tuán)隊(duì)在內(nèi)部的7種語(yǔ)言上取得了4.80%/8.02%的絕對(duì)性能提升。通過(guò)逐幀的知識(shí)蒸餾方法,還進(jìn)一步提高了單詞定時(shí)的準(zhǔn)確性,盡管此實(shí)驗(yàn)僅針對(duì)LibriSpeech進(jìn)行。
這項(xiàng)研究結(jié)果表明,端到端語(yǔ)音識(shí)別系統(tǒng)中的時(shí)間戳性能可以通過(guò)引入標(biāo)簽先驗(yàn)和融合不同級(jí)別的特征進(jìn)行有效優(yōu)化。在內(nèi)部中文實(shí)驗(yàn)上,該方法相較于混合系統(tǒng)和之前的端到端方法,都取得了顯著的改進(jìn);此外對(duì)于多種語(yǔ)言,方法也展現(xiàn)出了明顯的優(yōu)勢(shì);通過(guò)知識(shí)蒸餾方法的應(yīng)用進(jìn)一步提高了單詞定時(shí)的準(zhǔn)確性。這些結(jié)果不僅對(duì)字幕生成和發(fā)音訓(xùn)練等應(yīng)用具有重要意義,還為自動(dòng)語(yǔ)音識(shí)別技術(shù)的發(fā)展提供了有益的探索方向。
基于語(yǔ)種區(qū)分聲學(xué)邊界學(xué)習(xí)的中英混語(yǔ)音識(shí)別(Language-specific Acoustic Boundary Learning for Mandarin-English Code-switching Speech Recognition )
眾所周知Code-switch(CS)的主要目標(biāo)是促進(jìn)跨不同語(yǔ)言或技術(shù)領(lǐng)域的有效交流。 CS 需要在一個(gè)句子中交替使用兩種或多種語(yǔ)言,然而合并來(lái)自多種語(yǔ)言的單詞或短語(yǔ)可能會(huì)導(dǎo)致語(yǔ)音識(shí)別的錯(cuò)誤和混淆,這使Code-switching語(yǔ)音識(shí)別(CSSR) 成為一項(xiàng)更具挑戰(zhàn)性的任務(wù)。
通常端到端ASR模型由編碼器、解碼器和對(duì)齊機(jī)制組成。 現(xiàn)有的端到端 CSASR 模型大多只關(guān)注優(yōu)化編碼器和解碼器結(jié)構(gòu),很少會(huì)探討對(duì)齊機(jī)制是否需要進(jìn)行語(yǔ)種相關(guān)的設(shè)計(jì),大多數(shù)已有工作都是針對(duì)中英混場(chǎng)景使用普通話字符和英語(yǔ)子詞的混合作為建模單元。 通常普通話字符表示普通話中的單個(gè)音節(jié),并且聲學(xué)邊界清晰;而英文子詞是在不參考任何聲學(xué)知識(shí)的情況下獲得的,所以它們的聲學(xué)邊界可能是模糊的。 為了在 CSASR 系統(tǒng)中獲得普通話和英語(yǔ)的良好聲學(xué)邊界(對(duì)齊),進(jìn)行語(yǔ)種相關(guān)的聲學(xué)邊界學(xué)習(xí)是十分必要的。對(duì)此團(tuán)隊(duì)在CIF模型的基礎(chǔ)上進(jìn)行了改進(jìn),提出了一種語(yǔ)種區(qū)分的聲學(xué)邊界學(xué)習(xí)方法來(lái)用于CSASR任務(wù),模型架構(gòu)的詳細(xì)信息見(jiàn)下圖。
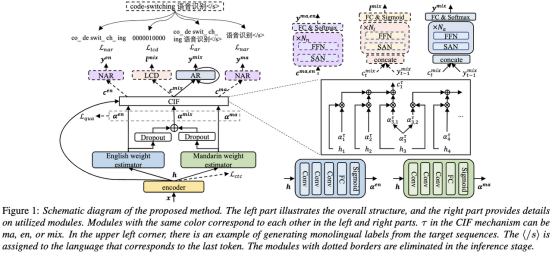
該模型由六個(gè)組件組成,分別是編碼器、語(yǔ)種區(qū)分的權(quán)重估計(jì)器(LSWE)、CIF模塊、自回歸(AR)解碼器、非自回歸(NAR)解碼器和語(yǔ)種變化檢測(cè)(LCD)模塊。編碼器和自回歸解碼器以及CIF的計(jì)算過(guò)程與原始的CIF-based的ASR方法無(wú)異,語(yǔ)種區(qū)分的權(quán)重估計(jì)器負(fù)責(zé)完成語(yǔ)種獨(dú)立的聲學(xué)邊界的建模,非自回歸(NAR)解碼器和語(yǔ)種變化檢測(cè)(LCD)模塊都是設(shè)計(jì)來(lái)輔助模型的訓(xùn)練,在解碼階段不再保留。
實(shí)驗(yàn)結(jié)果顯示,該方法在開(kāi)源中英混數(shù)據(jù)集SEAME的兩個(gè)測(cè)試集testman和testsge上獲得了新的SOTA效果,分別是16.29%和22.81%的MER。為了進(jìn)一步驗(yàn)證該方法在更大數(shù)據(jù)量中的效果,團(tuán)隊(duì)在9000小時(shí)的內(nèi)部數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),最終也是獲得了相對(duì)7.9%的MER收益。據(jù)了解,本論文也是第一篇在CSASR任務(wù)中進(jìn)行語(yǔ)種區(qū)分的聲學(xué)邊界學(xué)習(xí)的工作內(nèi)容。
USTR:基于統(tǒng)一的表征和純文本進(jìn)行 ASR 領(lǐng)域適應(yīng)(Text-only Domain Adaptation using Unified Speech-Text Representation in Transducer)
眾所周知,領(lǐng)域遷移一直是ASR中十分重要的任務(wù),但在目標(biāo)領(lǐng)域獲取成對(duì)的語(yǔ)音數(shù)據(jù)非常耗時(shí)且成本很高,因此其中很多工作都是利用目標(biāo)領(lǐng)域相關(guān)文本數(shù)據(jù)來(lái)提升識(shí)別效果。傳統(tǒng)方法中,TTS 會(huì)增加訓(xùn)練的周期和相關(guān)數(shù)據(jù)的存儲(chǔ)成本,ILME和Shallow fusion等方法會(huì)增加推理時(shí)的復(fù)雜度。
基于該任務(wù),團(tuán)隊(duì)在 RNN-T的基礎(chǔ)上,將Encoder拆分成Audio Encoder和Shared Encoder,同時(shí)引入Text Encoder用于學(xué)習(xí)和語(yǔ)音信號(hào)類(lèi)似的表征;語(yǔ)音和文本的表征則通過(guò)Shared Encoder,使用RNN-T loss進(jìn)行訓(xùn)練,被稱為 USTR(Unified Speech-Text Representation)。“對(duì)于Text Encoder這部分,我們探究了不同類(lèi)型的表征形式,包括Character序列,Phone序列和Sub-word 序列,最終結(jié)果表明Phone序列的效果最好。對(duì)于訓(xùn)練方式,本文探究了基于給定RNN-T模型的Multi-step訓(xùn)練方式和完全隨機(jī)初始化的Single-step訓(xùn)練方式。”
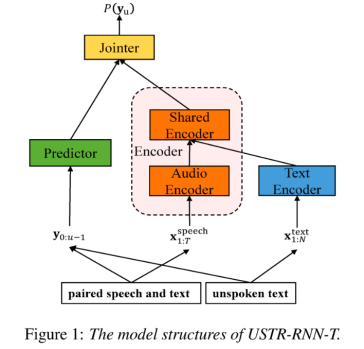
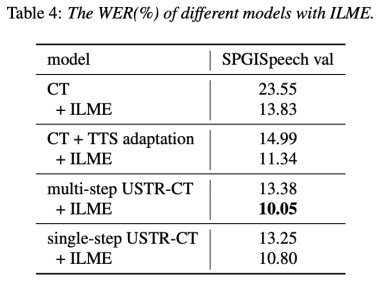
具體來(lái)說(shuō),團(tuán)隊(duì)使用LibriSpeech數(shù)據(jù)集作為Source domain,并利用 SPGISpeech 的標(biāo)注文本作為純文本進(jìn)行領(lǐng)域遷移實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果表明,該方法在目標(biāo)領(lǐng)域的效果提升可以和 TTS 基本持平;Single-step訓(xùn)練效果更高,效果和 Multi-step基本持平;同時(shí)還發(fā)現(xiàn)USTR方法可以和ILME這種外掛語(yǔ)言模型的方法進(jìn)一步結(jié)合,即便LM使用的是相同的文本訓(xùn)練語(yǔ)料。最終,在目標(biāo)領(lǐng)域測(cè)試集上,不結(jié)合外部語(yǔ)言模型,本方法相對(duì)基線 WER 23.55% -> 13.25%,相對(duì)下降 43.7%。
基于知識(shí)蒸餾的高效內(nèi)部語(yǔ)言模型估計(jì)方法 (Knowledge Distillation Approach for Efficient Internal Language Model Estimation)
盡管內(nèi)部語(yǔ)言模型估計(jì)(ILME)已經(jīng)證明其在端到端ASR語(yǔ)言模型融合中的有效性,但是與傳統(tǒng)的Shallow fusion相比,ILME額外引入了內(nèi)部語(yǔ)言模型的計(jì)算,增加了推理成本。為了估計(jì)內(nèi)部語(yǔ)言模型,需要基于ASR解碼器上做一次額外的前向計(jì)算,或者基于密度比率(Density Ratio)方法,用ASR訓(xùn)練集文本訓(xùn)練一個(gè)獨(dú)立的語(yǔ)言模型(DR-LM),作為內(nèi)部語(yǔ)言模型的近似。基于ASR解碼器的ILME方法,由于直接利用ASR參數(shù)進(jìn)行估計(jì),通常可以取得優(yōu)于密度比率方法的性能,但其計(jì)算量取決于ASR解碼器的參數(shù)量;密度比率方法的優(yōu)勢(shì)則在于可以通過(guò)控制DR-LM的大小實(shí)現(xiàn)高效的內(nèi)部語(yǔ)言模型估計(jì)。
為此火山語(yǔ)音團(tuán)隊(duì)提出在密度比率方法的框架下,用基于ASR解碼器的ILME方法作為教師,蒸餾學(xué)習(xí)DR-LM,從而在保持ILME性能的同時(shí),大幅降低ILME的計(jì)算成本。

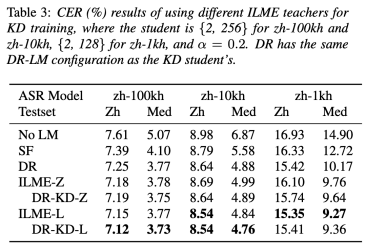
實(shí)驗(yàn)結(jié)果表明,這一方法能夠減少95%的內(nèi)部語(yǔ)言模型參數(shù)量,同時(shí)性能與基于ASR解碼器的ILME方法相當(dāng);采用性能更好的ILME方法作為教師時(shí),相應(yīng)的學(xué)生模型也能取得更好的效果;與計(jì)算量相當(dāng)?shù)膫鹘y(tǒng)密度比率方法相比,這一方法在高資源場(chǎng)景下性能略優(yōu),在低資源跨領(lǐng)域遷移場(chǎng)景下CER收益可達(dá)8%,并且對(duì)于融合權(quán)重更加魯棒。
GenerTTS:跨語(yǔ)言語(yǔ)音合成中音色和風(fēng)格與發(fā)音解耦和泛化(GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech)
跨語(yǔ)言音色和風(fēng)格可泛化的語(yǔ)音合成(TTS)旨在合成具有特定參考音色或風(fēng)格的語(yǔ)音,該音色或風(fēng)格并未在目標(biāo)語(yǔ)言中進(jìn)行過(guò)訓(xùn)練。它面臨著這樣的挑戰(zhàn),例如音色和發(fā)音之間難以分離,因?yàn)橥ǔ:茈y獲取特定說(shuō)話人的多語(yǔ)言語(yǔ)音數(shù)據(jù);風(fēng)格和發(fā)音混合在一起,因?yàn)檎Z(yǔ)音風(fēng)格包含語(yǔ)言無(wú)關(guān)和語(yǔ)言相關(guān)兩部分。
為了解決這些挑戰(zhàn),火山語(yǔ)音團(tuán)隊(duì)提出了GenerTTS,分別精心設(shè)計(jì)了基于HuBERT的信息瓶頸,以解藕音色和發(fā)音/風(fēng)格之間的聯(lián)系;最小化風(fēng)格和語(yǔ)言之間的互信息,以去除風(fēng)格中的語(yǔ)言特定信息。
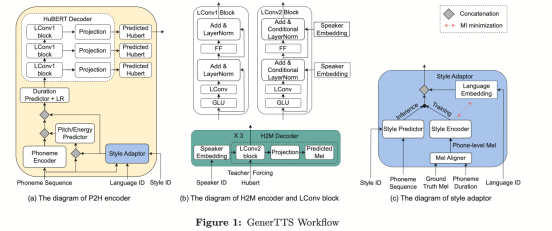

實(shí)驗(yàn)證明,GenerTTS在風(fēng)格相似性和發(fā)音準(zhǔn)確性方面優(yōu)于基準(zhǔn)系統(tǒng),并實(shí)現(xiàn)了跨語(yǔ)言音色和風(fēng)格的可泛化性。

一直以來(lái),火山語(yǔ)音團(tuán)隊(duì)面向字節(jié)跳動(dòng)內(nèi)部各業(yè)務(wù)線,提供優(yōu)質(zhì)的語(yǔ)音AI技術(shù)能力以及全棧語(yǔ)音產(chǎn)品解決方案,并通過(guò)火山引擎對(duì)外提供服務(wù)。自 2017 年成立以來(lái),團(tuán)隊(duì)專注研發(fā)行業(yè)領(lǐng)先的 AI 智能語(yǔ)音技術(shù),不斷探索AI 與業(yè)務(wù)場(chǎng)景的高效結(jié)合,以實(shí)現(xiàn)更大的用戶價(jià)值。