Interspeech 2023 | 火山引擎流媒體音頻技術之語音增強和AI音頻編碼

背景介紹
為了應對處理各類復雜音視頻通信場景,如多設備、多人、多噪音場景,流媒體通信技術漸漸成為人們生活中不可或缺的技術。為達到更好的主觀體驗,使用戶聽得清、聽得真,流媒體音頻技術方案融合了傳統機器學習和基于AI的語音增強方案,利用深度神經網絡技術方案,在語音降噪、回聲消除、干擾人聲消除和音頻編解碼等方向,為實時通信中的音頻質量保駕護航。
作為語音信號處理研究領域的旗艦國際會議,Interspeech一直代表著聲學領域技術最前沿的研究方向,Interspeech 2023 收錄了多篇和音頻信號語音增強算法相關的文章,其中,火山引擎流媒體音頻團隊共有 4 篇研究論文被大會接收,論文方向包括語音增強、基于AI編解碼 、回聲消除、無監督自適應語音增強。
值得一提的是,在無監督自適應語音增強領域,字節跳動與西工大聯合團隊在今年的CHiME (Computational Hearing in Multisource Environments) 挑戰賽子任務無監督域自適應對話語音增強(Unsupervised domain adaptation for conversational speech enhancement, UDASE) 獲得了冠軍(https://www.chimechallenge.org/current/task2/results)。CHiME挑戰賽是由法國計算機科學與自動化研究所、英國謝菲爾德大學、美國三菱電子研究實驗室等知名研究機構所于2011年發起的一項重要國際賽事,重點圍繞語音研究領域極具挑戰的遠場語音處理相關任務,今年已舉辦到第七屆。歷屆CHiME比賽的參賽隊伍包括英國劍橋大學、美國卡內基梅隆大學、約翰霍普金斯大學、日本NTT、日立中央研究院等國際著名高校和研究機構,以及清華大學、中國科學院大學、中科院聲學所、西工大、科大訊飛等國內頂尖院校和研究所。
本文將介紹這 4 篇論文解決的核心場景問題和技術方案,分享火山引擎流媒體音頻團隊在語音增強,基于AI編碼器,回聲消除和無監督自適應語音增強領域的思考與實踐。
基于可學習梳狀濾波器的輕量級語音諧波增強方法
論文地址:https://www.isca-speech.org/archive/interspeech_2023/le23_interspeech.html
背景
受限于時延和計算資源,實時音視頻通信場景下的語音增強,通常使用基于濾波器組的輸入特征。通過梅爾和ERB等濾波器組,原始頻譜被壓縮至維度更低的子帶域。在子帶域上,基于深度學習的語音增強模型的輸出是子帶的語音增益,該增益代表了目標語音能量的占比。然而,由于頻譜細節丟失,在壓縮的子帶域上增強的音頻是模糊的,通常需要后處理以增強諧波。RNNoise和PercepNet等使用梳狀濾波器增強諧波,但由于基頻估計以及梳狀濾波增益計算和模型解耦,它們無法被端到端優化;DeepFilterNet使用一個時頻域濾波器抑制諧波間噪聲,但并沒有顯式利用語音的基頻信息。針對上述問題,團隊提出了一種基于可學習梳狀濾波器的語音諧波增強方法,該方法融合了基頻估計和梳狀濾波,且梳狀濾波的增益可以被端到端優化。實驗顯示,該方法可以在和現有方法相當的計算量下實現更好的諧波增強。
模型框架結構
基頻估計器(F0 Estimator)
為了降低基頻估計難度并使得整個鏈路可以端到端運行,將待估計的目標基頻范圍離散化為N個離散基頻,并使用分類器估計。添加了1維代表非濁音幀,最終模型輸出為N+1維的概率。和CREPE一致,團隊使用高斯平滑的特征作為訓練目標,并使用Binary Cross Entropy作為損失函數:


可學習梳狀濾波器(Learnable Comb Filter)
對上述每一個離散基頻,團隊均使用類似PercepNet的FIR濾波器進行梳狀濾波,其可以表示為一個受調制的脈沖串:

在訓練時使用二維卷積層(Conv2D)同時計算所有離散基頻的濾波結果,該二維卷積的權重可以表示為下圖矩陣,該矩陣有N+1維,每一維均使用上述濾波器初始化:

通過目標基頻的獨熱標簽和二維卷積的輸出相乘得到每一幀基頻對應的濾波結果:


諧波增強后的音頻將和原始音頻加權相加,并和子帶增益相乘得到最后的輸出:

在推斷時,每一幀僅需要計算一個基頻的濾波結果,因此該方法的計算消耗較低。
模型結構

團隊使用雙路卷積循環神經網絡(Dual-Path Convolutional Recurrent Network, DPCRN)作為語音增強模型主干,并添加了基頻估計器。其中Encoder和Decoder使用深度可分離卷積組成對稱結構,Decoder有兩個并行支路分別輸出子帶增益G和加權系數R。基頻估計器的輸入是DPRNN模塊的輸出和線性頻譜。該模型的計算量約為300 M MACs,其中梳狀濾波計算量約為0.53M MACs。
模型訓練
在實驗中,使用VCTK-DEMAND和DNS4挑戰賽數據集進行訓練,并使用語音增強和基頻估計的損失函數進行多任務學習。


實驗結果
流媒體音頻團隊將所提出的可學習梳狀濾波模型和使用PercepNet的梳狀濾波以及DeepFilterNet的濾波算法的模型進行對比,它們分別被稱作DPCRN-CF、DPCRN-PN和DPCRN-DF。在VCTK測試集上,本文提出的方法相對現有方法均顯示出優勢。

同時團隊對基頻估計和可學習的濾波器進行了消融實驗。實驗結果顯示,相對于使用基于信號處理的基頻估計算法和濾波器權重,端到端學習得到的結果更優。

基于Intra-BRNN 和GB-RVQ 的端到端神經網絡音頻編碼器
論文地址:https://www.isca-speech.org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
背景
近年來,許多神經網絡模型被用于低碼率語音編碼任務,然而一些端到端模型未能充分利用幀內相關信息,且引入的量化器有較大量化誤差導致編碼后音頻質量偏低。為了提高端到端神經網絡音頻編碼器質量,流媒體音頻團隊提出了一種端到端的神經語音編解碼器,即CBRC(Convolutional and Bidirectional Recurrent neural Codec)。CBRC使用1D-CNN(一維卷積) 和Intra-BRNN(幀內雙向循環神經網絡) 的交錯結構以更有效地利用幀內相關性。此外,團隊在CBRC中使用分組和集束搜索策略的殘差矢量量化器(Group-wise and Beam-search Residual Vector Quantizer,GB-RVQ)來減少量化噪聲。CBRC以20ms幀長編碼16kHz音頻,沒有額外的系統延遲,適用于實時通信場景。實驗結果表明,碼率為3kbps的 CBRC編碼語音質量優于12kbps的Opus。
模型框架結構

CBRC總體結構
Encoder和Decoder網絡結構
Encoder采用4個級聯的CBRNBlocks來提取音頻特征,每個CBRNBlock由三個提取特征的ResidualUnit和控制下采樣率的一維卷積構成。Encoder中特征每經過一次下采樣則特征通道數翻倍。在ResidualUnit中由殘差卷積模塊和殘差雙向循環網絡構成,其中卷積層采用因果卷積,而Intra-BRNN中雙向GRU結構只處理20ms幀內音頻特征。Decoder網絡為Encoder的鏡像結構,使用一維轉置卷積進行上采樣。1D-CNN和Intra-BRNN的交錯結構使Encoder和Decoder充分利用20ms音頻幀內相關性而不引入額外的延時。

CBRNBlock結構
分組和集束搜索殘差矢量量化器 GB-RVQ
CBRC使用殘差矢量量化器(Residual Vector Quantizer,RVQ)將編碼網絡輸出特征量化壓縮到指定比特率。RVQ以多層矢量量化器(Vector Quantizer,VQ)級聯來壓縮特征,每層VQ對前一層VQ量化殘差進行量化,可顯著降低同等比特率下單層VQ的碼本參數量。團隊在CBRC中提出了兩種更優的量化器結構,即分組殘差矢量量化器 (Group-wise RVQ) 和集束搜索殘差矢量量化器(Beam-search RVQ)。
分組殘差矢量量化器 Group-wise RVQ | 集束搜索殘差矢量量化器 Beam-search RVQ |
|
|


Group-wise RVQ將Encoder輸出進行分組,同時使用分組的RVQ對分組后特征進行獨立量化,隨后分組量化輸出拼接輸入Decoder。Group-wise RVQ以分組量化方式降低了量化器的碼本參數量和計算復雜度,同時降低了CBRC端到端訓練難度進而提升了CBRC編碼音頻質量。
團隊將Beam-search RVQ引入到神經音頻編碼器端到端訓練中,使用Beam-search算法選擇RVQ中量化路徑誤差最小的碼本組合,以降低量化器的量化誤差。原RVQ算法在每層VQ量化中選擇誤差最小的碼本為輸出,但每層VQ量化最優的碼本組合后不一定是全局最優碼本組合。團隊使用Beam-search RVQ,在每層VQ中以量化路徑誤差最小準則保留k個最優的量化路徑,實現在更大的量化搜索空間中選擇更優的碼本組合,降低量化誤差。
Beam-search RVQ算法簡要過程: 1、每層VQ輸入前層VQ的個候選量化路徑,得到個候選量化路徑。 2、從個候選量化路徑中選擇個量化路徑誤差最小的個量化路徑作為當前VQ層輸出。 3、在最后一層VQ中選擇量化路徑誤差最小的路徑作為量化器的輸出。 |
|

模型訓練
在實驗中,使用LibriTTS數據集中245小時的16kHz語音進行訓練,將語音幅度乘以隨機增益后輸入模型。訓練中損失函數由頻譜重建多尺度損失,判別器對抗損失和特征損失,VQ量化損失和感知損失構成。

實驗結果
主客觀得分
為了評估CBRC編碼語音質量,構建了10條多語種音頻對比集,在該對比集上與其他音頻編解碼器進行了對比。為了降低計算復雜的影響,團隊設計了輕量化的CBRC-lite,其計算復雜度略高于Lyra-V2。由主觀聽感比較結果可知,CBRC在3kbps上語音質量超過了12kbps的Opus,同樣超過了3.2kbps的Lyra-V2,這表明所提出方法的有效性。https://bytedance.feishu.cn/docx/OqtjdQNhZoAbNoxMuntcErcInmb中提供了CBRC編碼后音頻樣音。
客觀分 | 主觀聽感得分 |
|
|


消融實驗
團隊設計了針對Intra-BRNN、Group-wise RVQ 和 Beam-search RVQ的消融實驗。實驗結果表明在Encoder和Decoder使用Intra-BRNN均可明顯提升語音質量。此外,團隊統計了RVQ中碼本使用頻次并計算熵解碼以對比不同網絡結構下碼本使用率。相比于全卷積結構,使用Intra-BRNN的CBRC將潛在編碼比特率從4.94kbps提升到5.13kbps。同樣,在 CBRC中使用Group-wise RVQ 和 Beam-search RVQ均能顯著提升編碼語音質量,且相比于神經網絡本身的計算復雜度, GB-RVQ帶來的復雜度增加幾乎可忽略。


樣音
原始音頻
arctic_a0023_16k,字節跳動技術團隊,5秒
es01_l_16k,字節跳動技術團隊,10秒
CBRC 3kbps
arctic_a0023_16k_CBRC_3kbps,字節跳動技術團隊,5秒
es01_l_16k_CBRC_3kbps,字節跳動技術團隊,10秒
CBRC-lite 3kbps
arctic_a0023_16k_CBRC_lite_3kbps,字節跳動技術團隊,5秒
es01_l_16k_CBRC_lite_3kbps,字節跳動技術團隊,10秒
基于兩階段漸進式神經網絡的回聲消除方法
論文地址:https://www.isca-speech.org/archive/pdfs/interspeech_2023/chen23e_interspeech.pdf
背景
在免提通信系統中,聲學回聲是令人煩惱的背景干擾。當遠端信號從揚聲器播放出來,然后由近端麥克風記錄時,就會出現回聲。回聲消除 (AEC) 旨在抑制麥克風拾取的不需要的回聲。在現實世界中,有很多非常需要消除回聲的應用,例如實時通信、智能教室 、車載免提系統等等。
最近,采用深度學習 (DL) 方法的數據驅動 AEC 模型已被證明更加穩健和強大 。這些方法將 AEC 表述為一個監督學習問題,其中輸入信號和近端目標信號之間的映射函數通過深度神經網絡 (DNN) 進行學習。然而,真實的回聲路徑極其復雜,這對 DNN 的建模能力提出了更高的要求。為了減輕網絡的建模負擔,大多數現有的基于 DL 的 AEC 方法采用一個前置的線性回聲消除(LAEC) 模塊來抑制大部分回聲的線性分量。但是,LAEC 模塊有兩個缺點:1)不合適的 LAEC 可能會導致近端語音的一些失真,以及 2)LAEC 收斂過程使線性回聲抑制性能不穩定。由于 LAEC 是自優化的,因此 LAEC 的缺點會給后續的神經網絡帶來額外的學習負擔。
為了避免 LAEC 的影響并保持更好的近端語音質量,本文探索了一種新的基于端到端 DL 的兩階段處理模式,并提出了一種由粗粒度 (coarse-stage) 和細粒度 (fine-stage) 組成的兩階段級聯神經網絡(TSPNN) 用于回聲消除任務。大量的實驗結果表明,所提出的兩階段回聲消除方法能夠達到優于其他主流方法的性能。
模型框架結構
如下圖所示,TSPNN 主要由三個部分組成:時延補償模塊 (TDC)、粗粒度處理模塊 (coarse-stage) 和細粒度處理模塊 (fine-stage)。TDC 負責對輸入的遠端參考信號 (ref) 和近端麥克風信號 (mic) 進行對齊,有利于后續模型收斂。coarse-stage 負責將大部分的回聲 (echo) 和噪聲 (noise) 從 mic 中去除,極大減輕后續 fine-stage 階段模型學習負擔。同時,coarse-stage 結合了語音活躍度檢測 (VAD) 任務進行多任務學習,強化模型對近端語音的感知能力,減輕對近端語音的損傷。fine-stage 負責進一步消除殘余回聲和噪聲,并結合鄰居頻點信息來較好地重構出近端目標信號。

為了避免獨立優化每個階段的模型而導致的次優解,本文采用級聯優化的形式來同時優化 coarse-stage 和 fine-stage,同時松弛對 coarse-stage 的約束,避免對近端語音造成損傷。此外,為了讓模型能夠具有感知近端語音的能力,本發明引入了 VAD 任務進行多任務學習,在損失函數中加入 VAD 的 Loss。最終損失函數為:
其中 分別表示目標近端信號復數譜、coarse-stage 和 fine-stage 估計的近端信號復數譜;分別表示coarse-stage估計的近端語音活躍狀態、近端語音活躍檢測標簽; 為一個控制標量,主要用于調節訓練階段對不同階段的關注程度。本發明限制 來松弛對 coarse-stage 的約束,有效避免 coarse-stage 對近端的損傷。
實驗結果
實驗數據
火山引擎流媒體音頻團隊所提兩階段回聲消除系統還與其他方法做了比較,實驗結果表明,所提能夠達到優于其他主流方法的效果。

具體例子
- 實驗結果 Github 鏈接:https://github.com/enhancer12/TSPNN
- 雙講場景效果表現:

CHiME-7 無監督域自適應語音增強(UDASE)挑戰賽冠軍方案
論文地址:https://www.chimechallenge.org/current/task2/documents/Zhang_NB.pdf
背景:
近年來,隨著神經網絡和數據驅動的深度學習技術的發展,語音增強技術的研究逐漸轉向基于深度學習的方法,越來越多基于深度神經網絡的語音增強模型被提出。然而這些模型大多基于有監督學習,都需要大量的配對數據進行訓練。然而在實際場景中,無法同時收錄到嘈雜場景的語音和與之配對的不受干擾的干凈語音標簽,通常采用數據仿真的形式,單獨采集干凈語音與各種各樣的噪聲,將其按照一定信噪比混合得到帶噪音頻。這導致了訓練場景與實際應用場景的不匹配,模型性能在實際應用中有所下降。
為了更好的解決以上域不匹配問題,利用真實場景中大量無標簽數據,無監督、自監督語音增強技術被提出。CHiME挑戰賽賽道2旨在利用未標記的數據來克服在人工生成的標記數據上訓練的語音增強模型因訓練數據與實際應用場景的不匹配導致的性能下降問題,研究的重點在于如何借助目標域的無標簽數據和集外的有標簽數據來提升目標域的增強結果。
模型框架結構:

無監督域自適應語音增強系統流程圖
如上圖所示,所提框架是一個教師學生網絡。首先在域內數據上使用語音活動檢測、UNA-GAN、仿真房間沖擊響應、動態加噪等技術生成最接近目標域的有標簽數據集,在該域外有標簽數據集上預訓練教師降噪網絡Uformer+。接著在域內無標簽數據上借助該框架更新學生網絡,即利用預訓練的教師網絡從帶噪音頻中估計干凈語音和噪聲作為偽標簽,將他們打亂順序重新混合作為學生網絡輸入的訓練數據,利用偽標簽有監督的訓練學生網絡。使用預訓練的MetricGAN判別器估計學生網絡生成的干凈語音質量評分,并與最高分計算損失,以指導學生網絡生成更高質量的干凈音頻。每訓練一定步長后以一定權重將學生網絡的參數更新到教師網絡中,以獲取更高質量的監督學習偽標簽,如此重復。
Ufomer+網絡
Uformer+是在Uformer網絡基礎上加入MetricGAN改進得到的。Uformer是一個基于 Unet 結構的復數實數雙路徑conformer網絡,它具有兩條并行的分支,幅度譜分支和復數譜分支,網絡結構如下圖所示。幅度分支用于進行主要的噪聲抑制功能,能夠有效抑制大部分噪聲。復數分支作為輔助,用于補償語譜細節和相位偏差等損失。MetricGAN的主要思想是使用神經網絡模擬不可微的語音質量評價指標,使其可以被用于網絡訓練中,以減少訓練和實際應用時評價指標不一致帶來的誤差。這里團隊使用感知語音質量評價(PESQ)作為MetricGAN網絡估計的目標。

Uformer網絡結構圖
RemixIT-G框架
RemixIT-G是一個教師學生網絡,首先在域外有標簽數據上預訓練教師Uformer+模型,使用該預訓練教師模型解碼域內帶噪音頻,估計噪聲和語音。接下來在同一批次內打亂估計的噪聲和語音的順序,重新將噪聲和語音按打亂后的順序混合成為帶噪音頻,作為訓練學生網絡的輸入。由教師網絡估計的噪聲和語音作為偽標簽。學生網絡解碼重混合的帶噪音頻,估計噪聲和語音,與偽標簽計算損失,更新學生網絡參數。學生網絡估計的語音被送入預訓練的MetricGAN判別器中預測PESQ,并與PESQ最大值計算損失,更新學生網絡參數。
所有訓練數據完成一輪迭代后根據如下公式更新教師網絡的參數:,其中為訓練第K輪教師網絡的參數, 為第K輪學生網絡的參數。即將學生網絡的參數以一定權重與教師網絡相加。
數據擴充方法 UNA-GAN

UNA-GAN結構圖
無監督噪聲自適應數據擴充網絡UNA-GAN是一種基于生成對抗網絡的帶噪音頻生成模型。其目的是在無法獲取獨立的噪聲數據的情況下,只使用域內帶噪音頻,直接將干凈語音轉化為帶有域內噪聲的帶噪音頻。生成器輸入干凈語音,輸出仿真的帶噪音頻。判別器輸入生成的帶噪音頻或真實的域內帶噪音頻,判斷輸入的音頻來自真實場景還是仿真生成。判別器主要根據背景噪聲的分布來區分來源,在這個過程中,人類語音被視為無效信息。通過執行以上對抗訓練的過程,生成器試圖將域內噪聲直接添加在輸入的干凈音頻上,以迷惑判別器;判別器試圖盡力區分帶噪音頻的來源。為了避免生成器添加過多噪聲,覆蓋掉輸入音頻中的人類語音,使用了對比學習。在生成的帶噪音頻、和輸入的干凈語音對應位置采樣256個塊。相同位置的塊的配對被視為正樣例,不同位置的塊的配對被視為負樣例。使用正負樣例計算交叉熵損失。
實驗結果
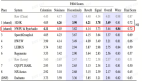
結果表明所提出的Uformer+相比基線Sudo rm-rf具有更強的性能,數據擴充方法UNA-GAN也具有生成域內帶噪音頻的能力。域適應框架RemixIT基線在SI-SDR上取得了較大提升,但在DNS-MOS上指標較差。團隊提出的改進RemixIT-G同時在兩個指標上都取得了有效提升,并在競賽盲測集上取得了最高的主觀測聽MOS打分。最終測聽結果如下圖所示。

總結與展望
上述介紹了火山引擎流媒體音頻團隊基于深度學習在特定說話人降噪,AI編碼器,回聲消除和無監督自適應語音增強方向做出的一些方案及效果,未來場景依然面臨著多個方向的挑戰,如怎么樣在各類終端上部署運行輕量低復雜度模型及多設備效果魯棒性,這些挑戰點也將會是流媒體音頻團隊后續重點的研究方向。