如何構建與優化數據倉庫架構與模型設計?
數據倉庫是企業中存儲和管理大量結構化數據的核心組件,用于支持業務分析和決策制定。構建和優化數據倉庫的架構和模型設計是確保數據倉庫能夠高效、可擴展地滿足業務需求的關鍵要素。本文將探討如何構建與優化數據倉庫架構與模型設計的關鍵步驟和最佳實踐。
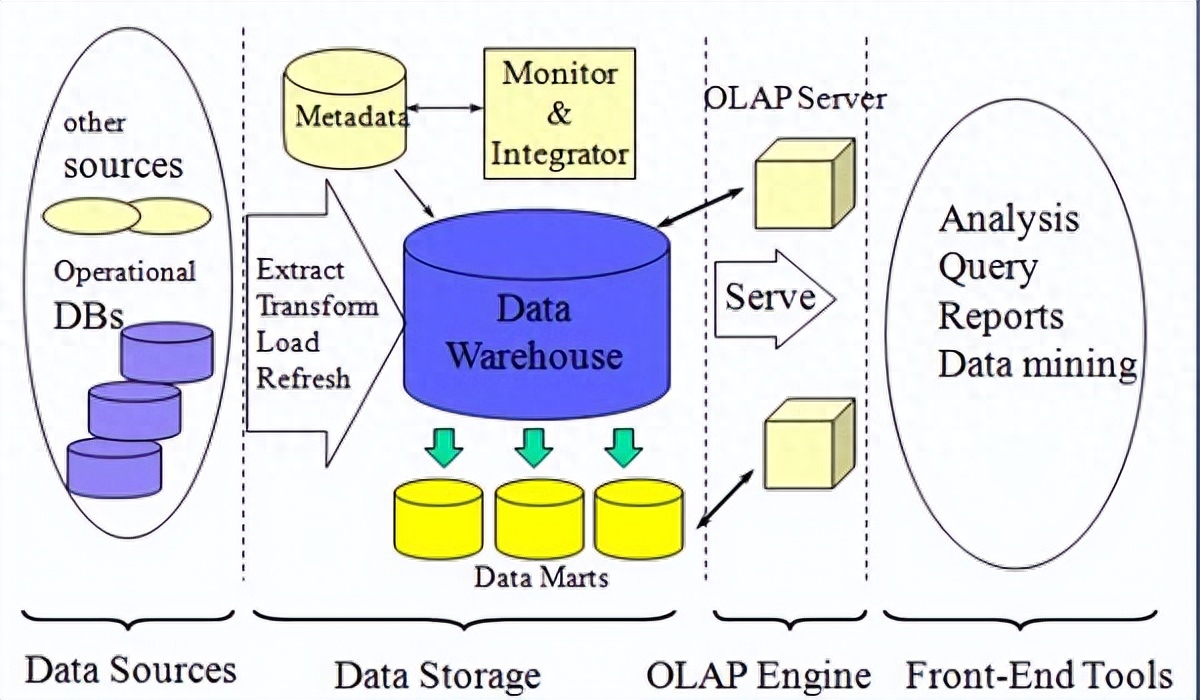
1、架構設計
數據倉庫的架構設計決定了數據的存儲、處理和訪問方式,影響著數據倉庫的性能和擴展性。以下是一些構建數據倉庫架構的關鍵步驟:

業務需求分析:深入了解業務需求,明確數據倉庫的功能和服務范圍。與業務部門緊密合作,確定數據倉庫的關鍵業務指標和數據粒度。

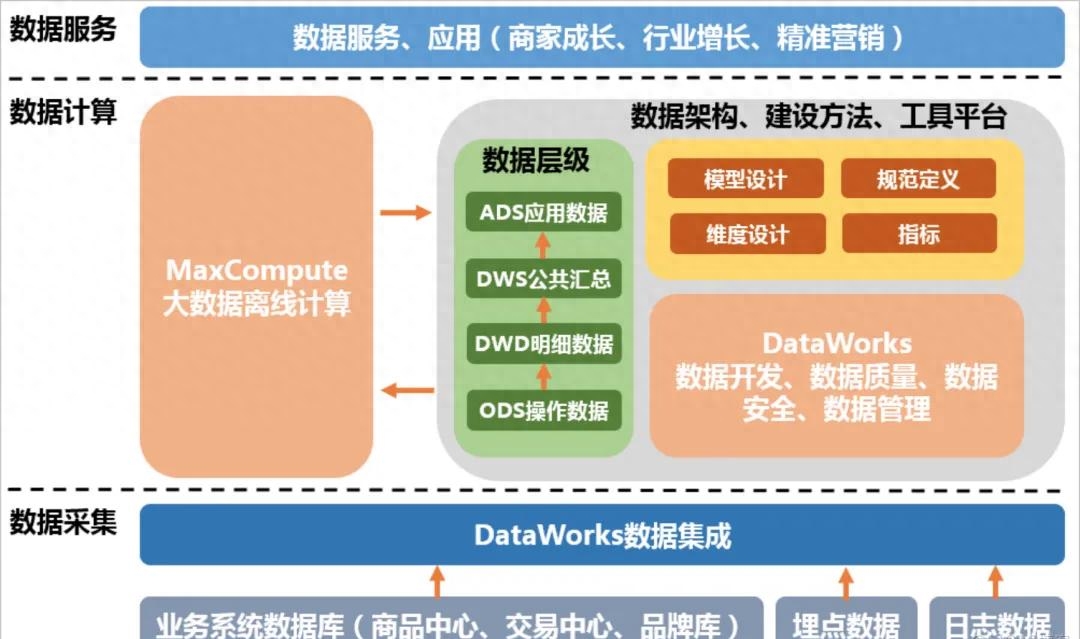
數據源集成:識別和整合企業內外部的數據源,包括數據庫、應用系統、API等。通過ETL(抽取、轉換、加載)過程將數據源的數據導入到數據倉庫中。

數據模型設計:基于業務需求和數據關系,設計合適的數據模型。常見的數據模型包括維度建模(如星型模型和雪花模型)和面向文檔的模型(如文檔數據庫)。數據模型需要考慮數據的查詢和分析需求,以及數據的一致性和可擴展性。

數據存儲和處理:選擇合適的數據存儲和處理技術,如關系型數據庫、列式數據庫、大數據平臺等。根據數據量和性能要求,確定數據的分區、索引和分布策略,優化數據的存儲和訪問效率。

數據訪問和報表:設計合適的數據訪問接口和報表工具,以便用戶能夠方便地查詢和分析數據。提供靈活的查詢功能和可視化報表,支持自定義指標和數據透視。
2、模型設計與優化
數據倉庫的模型設計是構建高效的數據分析和查詢環境的關鍵。以下是一些模型設計與優化的最佳實踐:

維度建模:采用維度建模可以簡化數據模型的設計和查詢操作,提高查詢性能。使用事實表和維度表來描述業務事實和業務維度,構建星型模型或雪花模型。合理定義維度層次、維度關系和度量指標,以滿足不同粒度的查詢需求。

數據分區:對大規模數據進行數據分區可以提高數據查詢的性能。根據數據的特點和查詢模式,將數據按照時間、地理位置、業務部門等進行分區。分區可以提高數據的存取效率,減少不必要的數據掃描和計算。
索引優化:合理設計和管理索引可以加速數據查詢。根據查詢的字段和條件,創建合適的索引。考慮索引的選擇性、大小和更新成本,權衡查詢性能和維護成本。

數據聚合:通過數據聚合可以減少數據的冗余和復雜性,提高查詢性能。根據業務需求,對數據進行聚合,生成預計算的匯總數據或指標。通過聚合操作,可以加速復雜的查詢和分析操作。

緩存優化:利用緩存技術可以減少數據倉庫的訪問次數,提高查詢性能。將常用的查詢結果和計算結果緩存起來,以便下次查詢時直接獲取。緩存可以使用內存緩存、分布式緩存或者查詢結果緩存等方式實現。

數據壓縮與分區裁剪:對數據進行壓縮可以減少存儲空間,并提高數據的讀取速度。使用合適的壓縮算法和壓縮技術,根據數據的特點選擇合適的壓縮方式。同時,利用分區裁剪技術可以減少不必要的數據掃描,提高查詢效率。

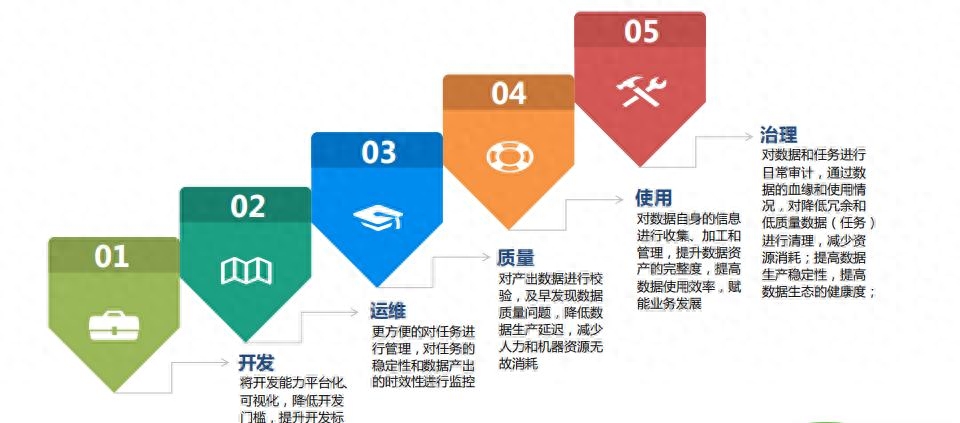
定期維護和優化:數據倉庫的模型設計和優化是一個持續的過程。定期進行性能分析和優化,識別潛在的性能瓶頸和問題。根據監測結果進行索引重建、數據重分區和性能調優,保持數據倉庫的高效運行。

通過合理的架構設計和模型優化,構建和優化數據倉庫可以提供高效、可靠的數據分析環境。充分了解業務需求,設計合適的數據模型,選擇適當的數據存儲和處理技術,以及進行模型優化和性能調優,可以實現數據倉庫的高性能查詢和分析,為企業提供準確、及時的數據支持,推動業務決策和創新的發展。