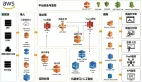
數字AI時代下的數據湖與數據倉庫
我們曾經把數據比作21世紀的石油,真正的價值不在數據本身,而是如何高效存儲、提取并轉化這些數據。
數據湖與數據倉庫正是企業管理海量數據的兩大關鍵設施,它們如同企業數據管理體系的雙引擎,各司其職又相互協作。

數據湖:容納一切的藍色海洋
數據湖本質是一個超大規模的存儲庫,以原始形態存儲各類數據。
設想你擁有一片藍色海洋,能容納任何形式的"數據水滴"——不管是結構化的表格數據,半結構化的JSON文件,還是非結構化的圖片視頻和文本內容,全都能原汁原味地保存。
數據湖打破了傳統存儲方式對數據類型的限制,采用"讀時定義"(Schema-on-Read)模式,讓數據先存儲,使用時再定義結構。
這種設計哲學使企業能夠以極低成本存儲海量數據,同時保留數據的完整性和靈活性。

某互聯網巨頭日均處理超過100PB的數據,如果沒有數據湖的彈性存儲能力,單是存儲費用就會讓財務總監頭痛不已。數據湖讓企業避免了"為存而存"的尷尬,轉而專注于數據價值的挖掘。
數據湖最大優勢在于它能夠跨越時間和空間限制,保存企業全量數據資產。
這意味著分析師可以隨時回溯歷史數據,發現新的業務洞見;數據科學家能夠利用完整數據訓練更準確的AI模型;業務團隊能夠自助式獲取所需數據,無需反復請求IT部門支持。
數據倉庫:井然有序的價值工廠
相比數據湖的包容萬象,數據倉庫則像一座高度組織化的工廠,專注于將原料(數據)轉化為精確加工的產品(業務洞察)。
數據倉庫采用"寫時定義"(Schema-on-Write)模式,要求數據在進入前就經過嚴格的清洗和轉換處理,以符合預設的結構。
這種嚴謹性使得數據倉庫在處理結構化數據查詢分析時表現出色,為業務決策提供高效可靠的數據支持。
某零售巨頭通過數據倉庫對銷售數據進行實時分析,秒級響應速度讓門店經理能夠隨時調整庫存和促銷策略。數據倉庫的高性能查詢能力,正是支撐企業核心業務運轉的關鍵引擎。
數據倉庫最擅長處理業務數據,通過多維度的聚合分析,生成各類報表和儀表盤,直觀展現業務運營狀況。這種結構化、標準化的數據處理方式,確保了企業各部門使用統一口徑的數據,避免"數據打架"現象。
雙引擎協作:數據價值最大化
數據湖與數據倉庫并非替代關系,而是協同作用的雙引擎系統。理想的數據架構應該充分利用兩者優勢,形成"數據湖+數據倉庫"的混合架構。

在這種架構下,數據湖負責全量數據存儲和探索性分析,數據倉庫則專注于已知業務場景的高效查詢。數據湖中的原始數據經過篩選和處理后,可以加載到數據倉庫中形成結構化數據模型;同時,數據倉庫中的匯總數據也可以回流到數據湖,與其他數據源結合產生新的分析價值。
某金融科技公司通過"湖倉一體"架構,既滿足了傳統業務報表的需求,又支持了風控模型的創新。
風控專家可以在數據湖中自由探索客戶行為特征,發現潛在風險因子;同時,這些發現可以固化到數據倉庫中,應用到日常業務流程。
結語
企業數據戰略應根據自身情況靈活選擇。初創企業可能優先建設數據湖,以低成本積累數據資產;傳統企業則可能先強化數據倉庫,保障核心業務運轉。
無論選擇哪種路徑,關鍵是構建統一的數據管理框架,確保數據資產能夠被充分利用。
我們正處于數據AI驅動決策的時代,數據湖與數據倉庫這對"雙引擎"將持續助力企業釋放數據價值,驅動業務創新與增長。掌握這兩種技術的核心理念與適用場景,也行是每位數據從業者的必備素養。