













如何保護數據平臺的隱私數據?
作者 | 楊林山
一、前言
去年12月20日,某知名汽車品牌發生了數據泄露事件,而且泄露的數據包含用戶個人隱私數據,也包含了公司的運營銷售信息等商業機密數據。泄露的個人隱私信息將用戶暴露于短信、電話騷擾甚至電信詐騙的危害之下,同時也造成了用戶對企業的信任危機,企業也將會面臨監管的調查。
而在不久之前的12月13號,“通信行程卡”小程序下線后,各大通信運營商隨即發布了刪除相關數據的通告。通信行程碼中保存了個人身份信息和個人行程信息等敏感隱私數據。如果因為該數據的泄露,很可能會導致一些電信詐騙案件出現,對個人危害極大。業務下線后,運營商通過刪除了個人信息來保護廣大市民的敏感信息。
隨著信息安全攻擊的頻繁發生,任何企業都面臨潛在數據泄露安全事件的風險。通過一些簡單的隱私數據保護措施,可以降低發生數據泄露事件的可能性,或者在發生數據泄露事件時,減少其危害性。
本文先簡要介紹一下隱私數據保護基本知識,然后再介紹在數據平臺中不同場景下應用對應的數據保護措施。

二、為什么需要保護隱私數據?
處理個人數據的私密和安全非常重要,原因有兩個。一是遵守數據隱私法律和規定。在大多數國家和地區,都有嚴格的法律保護個人隱私。這些法律規定了如何收集、使用和儲存個人數據,并規定了違反這些規定的后果。負責處理個人數據有助于遵守這些法律和規定,避免違反法律的后果。另一個原因是數據泄露事件會給企業帶來嚴重的信任危機和經濟成本。數據泄露會導致客戶和利益相關者的信任危機,并可能導致昂貴的罰款和法律程序。
1.什么是隱私數據?
第一類隱私數據是PII。PII(Personally Identifiable Information)是指與個人身份相關的信息。這些信息包括姓名、電話號碼、郵箱地址、社會安全號碼、銀行賬號信息等,這些信息可以直接或結合其他信息用于識別某個特定個人。
第二類隱私數據是與個人相關的信息,但不屬于PII。這包括個人的興趣愛好、性格、活動和信仰、個人的行程信息、健康信息等。
第三類隱私數據是個人、企業或組織的專有且保密的信息。通常,與商業性質有關或與合同有關的數據被認為是敏感的,泄露這類數據往往會影響商業運營或面臨法律風險。
2.如何識別隱私數據?
對于數據工程團隊,一般來說沒有統一的敏感信息的標準。不同的地區,不同的行業有不同的規定和法律。不同的公司對隱私數據的定義都不一樣。在企業內,一般需要遵守數據治理團隊、數據隱私團隊或者企業安全團隊建立的數據安全框架和安全策略。
此外我們還可以基于一些隱私掃描工具來檢測數據中可能存在的隱私風險,比如微軟開源的Microsoft Presidio。甚至云廠商們都不斷推出隱私數據保護相關的安全產品來識別隱私數據的合規性風險。
3.怎么保護隱私數據?
對于保護隱私數據的關鍵技術有數據脫敏、匿名化,此外還有隱私計算和數據合成。
處理隱私數據時需要考慮兩個基本的要求:
- 數據保密性:需要保證潛在的數據泄露事件發生后,攻擊者無法獲取到敏感信息。
- 數據可用性:保證被處理后的數據,仍然保持某些統計特性或者業務含義,在某些業務場景中是可用的。
這兩個指標是矛盾的,我們需要根據實際的業務需求和安全需求來調節和平衡。
(1) 數據脫敏 (Data Masking)
數據脫敏,也叫假名化(Pseudonymous),通過用虛假信息替換PII信息或者對敏感信息進行加密來實現對隱私數據的。大部分脫敏技術處理過后數據不可逆,即沒辦法還原成原文。
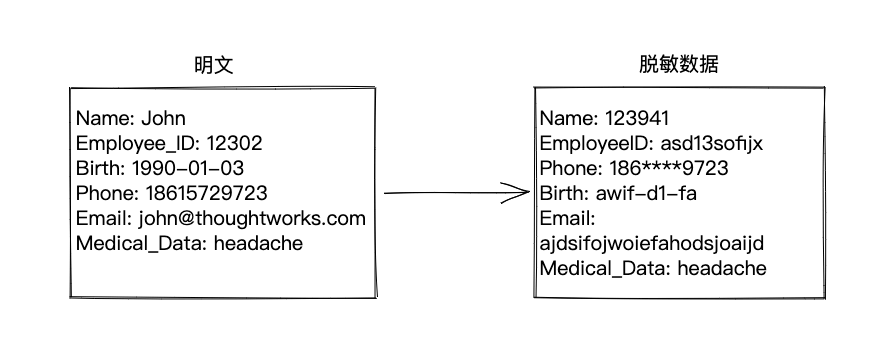
數據脫敏

常見數據脫敏方法
脫敏后的數據不再包含PII信息但是仍然屬于個人信息的范疇,受大部分數據安全保護法律法規保護。某些場景下,攻擊者可以通過結合外部數據來確定個人。例如當我們能把某位職員的公司信息和職位信息和脫敏后的個人數據結合在一起,那么幾乎可以確認這個人的身份。

與外部關聯數據結合后,數據脫敏后仍不是完全安全
(2) 匿名化(Anonymous)
數據匿名通過完全消除PII信息來保護數據的隱私。數據匿名化的目的是使數據集中的個人身份信息不能被確定,從而使數據更加安全。匿名化的數據通常不再屬于個人信息的范疇,因此也不受大部分個人數據保護相關的法律法規的限制。
常見的匿名化的技術方法有:
- 數據刪除:從數據中刪除某些字段,以此來消除數據中的個人身份信息。
- 數據隨機化:對數據進行隨機處理,以此來消除數據中的個人身份信息。
- 數據泛化、K匿名:將數據中的個人身份信息替換為區間值來保護個人隱私,同時也能保留一些數據價值。
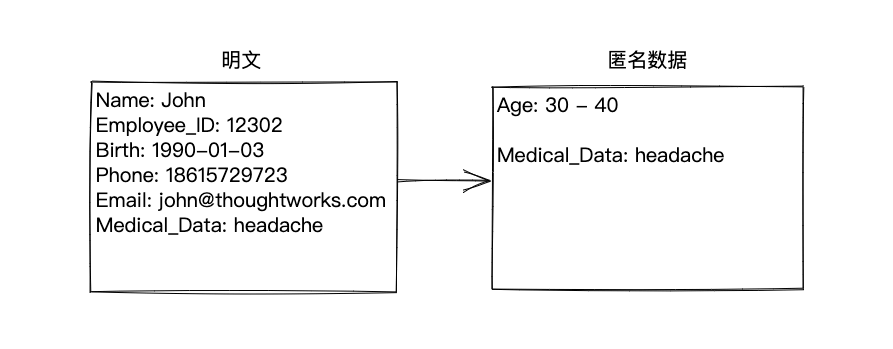
數據匿名化
數據匿名化的好處有:
- 更安全地保護個人隱私數據數據泄漏發生后對個人造成的危害性是較小的
- 更安全地進行數據協作和共享
- 沒有了法律法規上對個人信息數據使用的限制
匿名化后的數據帶來數據安全的同時也會降低數據質量和數據可用性。匿名化的數據也不是絕對安全的。
(3) 其他技術
除了最基本的隱私數據處理技術外,還有一些在快速發展的隱私數據保護技術。
隱私計算是一種技術,旨在保護數據的隱私和安全,同時允許在不泄露原始數據的情況下進行數據處理和分析。它通過在受信任的執行環境中進行數據處理來實現這一目的,以便在數據處理完成后將結果返回給請求方。
合成數據是人為生成的數據,而不是由真實世界事件產生的數據。它通常使用算法生成,可用于驗證數學模型和訓練機器學習模型。合成數據可以幫助保護原始數據的隱私,因為它不是真實的個人信息。
三、數據平臺隱私數據保護實踐
1.數據平臺隱私數據保護架構
數據平臺接收上游數據源中各種數據,其中包括大量的用戶和雇員的個人信息,以及公司運營、財務等機密信息。同時,數據平臺中會有數據工程師、數據分析師和數據科學家使用這些數據。作為企業數據集中采集、處理和共享的平臺,數據泄露發生的風險和危害程度都很高。
因此,數據平臺和數據倉庫承擔著隱私數據保護的重要責任。為了降低在數據平臺中發生數據泄露的可能性和危害性,數據平臺需要應用數據脫敏、數據加密等隱私數據保護技術。架構上,數據在數據平臺中生命周期中的不同階段會采取數據脫敏、數據加密等方式來構建端到端內建隱私數據保護的企業數據管道。
在基礎設施上:
- 業務平臺和數據平臺均使用了HashiCorp Vault作為安全管理和訪問密鑰的基礎設施
在數據源上:
- RDS中的數據一般依賴于上游業務系統的數據保護措施,數據平臺很難進行預先干預。
- 數據平臺運維的對象存儲AWS S3 Buckets,一般會讓上游業務系統放入文件級別加密后的文件。對于非技術用戶采用AWS KMS對S3 Buckets進行數據加密。
在數據倉庫中:
- 數據集成工具支持對行級別的加密和數據脫敏等操作,對于PII信息數據需要脫敏后或者加密后存儲到數據倉庫中。加密和數據脫敏所需要的加密密鑰和密碼學算法的參數,數據集成工具會從Vault的KV Secret Engine進行讀取。
- 數據倉庫內部通過創建Masking Policy來實現動態數據脫敏。針對不同角色的查詢操作員進行不同程度的數據遮蔽。
- 當下游的業務系統需要PII數據支持時,我們會在數據導出時對PII字段進行解密,再通過密碼學算法使用數據平臺的私鑰和下游數據消費方的公鑰對解密后的數據進行字段級別或者文件級別的加密,再寫入到數據倉庫應用層的數據集市中或者AWS S3 Buckets的文件中。
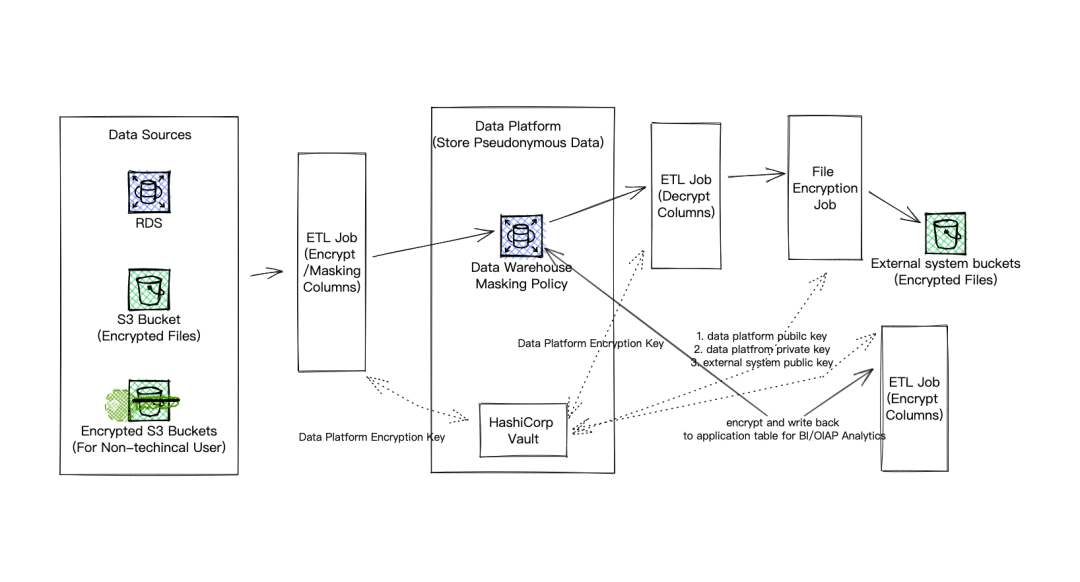
數據平臺隱私數據保護架構
2.數據脫敏(Data Masking):避免暴露敏感信息
數據脫敏的目的是避免暴露敏感信息給大部分數據消費方。
在數據平臺中,數據脫敏主要有兩種實現方式:
- 靜態脫敏:通過數據脫敏技術,將生產數據脫敏后導出到目標的存儲中,被存儲的數據已經改變了信息內容。
- 動態脫敏:通過準確地解析SQL語句匹配脫敏條件,在匹配成功后,改寫查詢語句或者返回數據,將脫敏后的數據返回。
靜態脫敏實現方式主要是在數據管道中內建數據脫敏。我們可以在數據集成工具中內建脫敏功能,使數據在進入數據倉庫后就已經是脫敏數據。動態脫敏主要基于數據庫系統或者云數據倉庫的RBAC機制和內建的數據脫敏功能,通過針對特定操作角色和數據列創建脫敏規則,在數據被查詢時,執行引擎會根據查詢上下文來決定返回的數據是源文本還是脫敏后的值。
動態脫敏更為靈活,能輕松應對數據安全需求的變化,但需要數據庫查詢引擎支持。靜態脫敏實現上更為簡單,但當數據安全需求變化時,我們通常也需要完全重建數據倉庫相關數據模型。
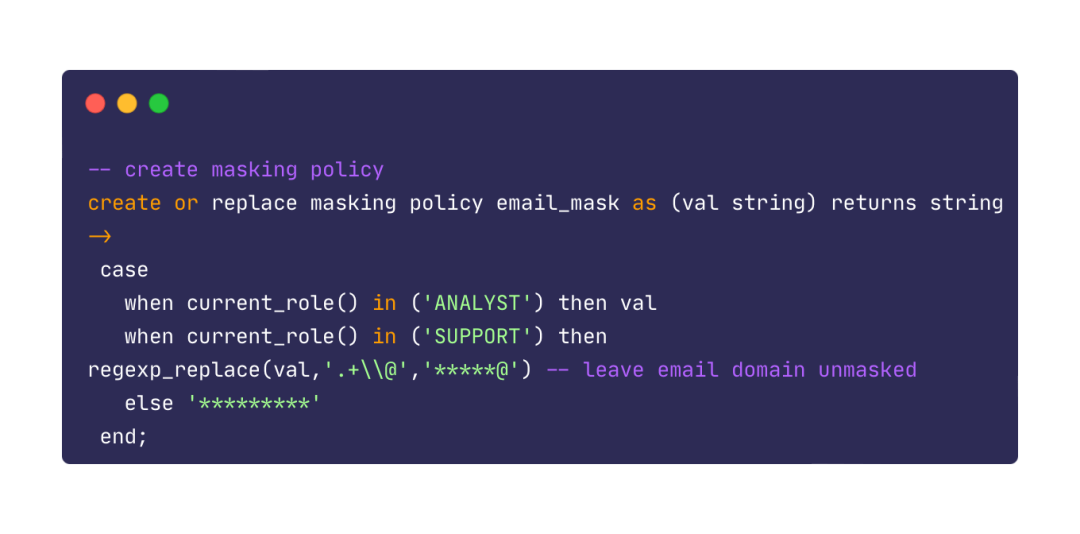
例如在Snowflake云數據倉庫中,我們可以設立如下規則對email列進行動態脫敏。當數據倉庫用戶角色為數據分析師的時候返回源文本,而其他角色查詢返回完全屏蔽的值。
3.數據加密(Data Encryption):安全數據分享
與數據脫敏不同,數據加密的主要目標是共享數據給授權過的可信方。
處理加密時需要考慮的問題:
- 如何管理加密密鑰,如何保證密鑰安全地和其他系統集成?
- 多個實體之間安全地共享加密密鑰?
對于問題1,我們選擇了開源的密鑰管理系統HashiCorp Vault。Hashicorp Vault是一個用于管理和保護機密信息的工具。它允許用戶存儲,管理和控制對機密信息的訪問。機密信息可以是密碼,API密鑰,證書或其他敏感信息。Vault可以很好地和Kubernetes結合,我們可以安全地在應用Pod啟動時將機密信息注入到Pod中。此外,Vault還可以動態生成或者定期刷新數據庫憑證,避免數據庫密碼泄露風險。
對于問題2,我們選擇了AES-256-GCM作為數據加密的算法同時使用ECDH算法來交換兩個實體的公鑰來創建共享AES-256-GCM的加密密鑰,來保證加密密鑰的安全性。

ECDH圖示
ECDH(Elliptic Curve Diffie–Hellman Key Exchange)算法過程如下圖:
- Alice和Bob通過ECC算法創建各自的公私鑰對,需采用相同的橢圓曲線。
- Alice和Bob互相交換公鑰。
- Alice計算加密密鑰 = Bob公鑰 * Alice私鑰
- Bob計算加密密鑰 = Alice公鑰 * Bob私鑰
- Alice和Bob的加密密鑰是相等的,Alice加密的數據,Bob也能解密。
使用OpenSSL命令行工具實現該過程。

端到端隱私數據加密解密過程如下:
- PII隱私數據加密后進入數據倉庫,加密密鑰是數據平臺自己維護的密鑰,從Vault中讀取
- 數據倉庫中存在的是密文數據,下游數據需要PII信息時,使用特定下游數據使用方的公鑰和數據平臺私鑰生成共享加密密鑰對數據文件進行加密,這樣只有該下游數據使用方才能解密數據。
- 下游去訪問或者接收到加密后的數據文件后,再用數據平臺的公鑰和該系統的私鑰生成共享加密密鑰對數據文件進行解密。當下游數據使用方無需給數據平臺共享數據時,我們可以在加密文件時,運行時生成一組新的公私鑰對,在數據文件中嵌入公鑰和相關密碼學參數。這樣只要雙方保持一致的加解密協議,下游在確保隱私數據的獲取和使用的同時,數據平臺方人員也不能解密數據文件,進一步減少了數據泄露的風險。

數據管道中加密過程

業務系統中解密過程
4.數據哈希(Data Hashing):跨數據域隱私數據關聯
有些場景期望與外部數據域的數據進行數據融合和數據共享時,通常需要通過個人隱私信息或者其他敏感信息將雙方數據域的數據關聯在一起。同時在數據傳輸、處理和存儲的過程中不期望暴露隱私信息。此時,我們可以利用數據哈希的特性來實現跨數據域的隱私數據關聯。
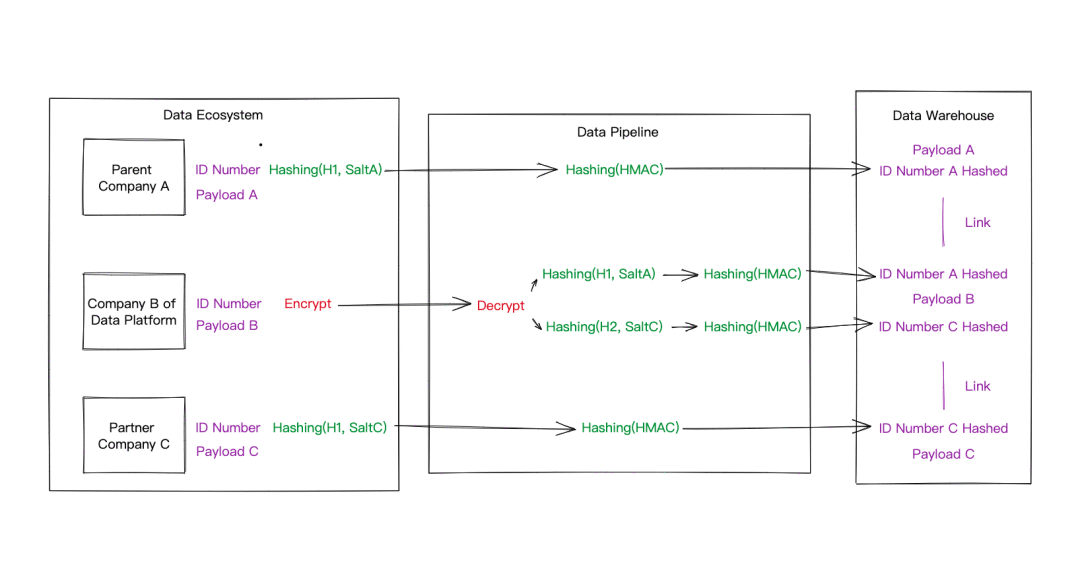
跨數據域隱私數據關聯
圖中場景存在三個數據域,數據平臺所屬公司B,母公司A和合作公司C,其隱私數據關聯過程如下:
- 母公司A選擇哈希算法Hashing(H1)和鹽值SaltA計算得到ID信息的哈希值ID_NUMBER_A_HASHED,提供給數據平臺。
- 合作公司C選擇哈希算法Hashing(H1)和鹽值SaltC計算得到ID信息的哈希值ID_NUMBER_C_HASHED,提供給數據平臺。
- 數據平臺公司B為了完全考慮,先對ID_NUMBER進行加密。
- 經過數據管道接入數據時,數據平臺先對ID_NUMBER進行解密,再根據不同公司的哈希算法和鹽值分別計算出對應的相等的哈希值。
- 在數據進入數據平臺之前,再次采用不同的哈希算法進行一次哈希,將得到的哈希值存入數據倉庫中。避免數據平臺和數據域中采用相同哈希算法導致可能存在的哈希字典攻擊。
- 數據倉庫里就可以通過不同數據域隱私信息的哈希值進行數據關聯,獲取來源于各個數據域的共享數據(Payload)。
四、總結
- 個人隱私數據受到法律法規的保護,企業越來越關注對個人隱私數據的處理。數據平臺數據倉庫作為數據的集中式采集處理場所也應該提高對個人隱私數據處理的關注度。
- 保護隱私數據的關鍵技術主要有數據脫敏、匿名化和加密技術。此外,隱私計算和合成數據等技術也值得關注和實踐。
- 在數據平臺隱私數據保護實踐中,數據脫敏用于避免暴露隱私數據給大部分數據消費者,數據加密技術用于分享隱私數據給可信方,最后數據哈希技術用于跨數據域的隱私數據關聯場景。此外我們還需要如Vault等的安全基礎設施,并且需要將Vault集成到數據采集、傳輸和處理的系統中。

















