GPT-4寫代碼不如ChatGPT,誤用率高達62%!加州大學兩位華人開源代碼可靠性基準RobustAPI
大型語言模型(LLM)在理解自然語言和生成程序代碼方面展現(xiàn)出了非凡的性能,程序員們也開始在編碼過程中使用Copilot工具輔助編程,或是要求LLM生成解決方案。
經(jīng)過幾版迭代后,目前LLM生成的代碼已經(jīng)很少有語法錯誤了,也更貼合用戶輸入的文本、符合預期語義,但針對LLM代碼生成的可靠性和魯棒性仍然缺乏徹底的研究。
代碼的可執(zhí)行并不等同于可靠,軟件的開發(fā)環(huán)境、部署環(huán)境都存在很大的不確定性。

如果直接使用LLM生成的代碼,可能會因為AP誤用(misuse)導致更嚴重的問題,例如資源泄漏、程序崩潰;最糟糕的是,使用LLM代碼生成服務的用戶大多數(shù)都是新手開發(fā)人員,很難識別出「貌似可運行代碼」下的隱藏問題,進一步增加了漏洞代碼在現(xiàn)實中的應用風險。
現(xiàn)有的代碼評估基準和數(shù)據(jù)集主要專注于小任務,例如面試中的編程問題,可能不符合開發(fā)人員在工作中的實際需求。
最近,來自加州大學的兩位華人研究人員發(fā)布了一個用于評估生成代碼可靠性和魯棒性的新數(shù)據(jù)集RobustAPI,包括從StackOverflow中收集得到的1208個編碼問題,涉及24個主流Java API的評估。

論文鏈接:https://arxiv.org/pdf/2308.10335.pdf
研究人員總結了這些API的常見誤用模式,并在當下常用的LLM上對其進行評估,結果表明,即使是GPT-4,也有高達62%的生成代碼包含API誤用問題,如果代碼被實際部署,可能會導致意想不到的后果。
論文相關的數(shù)據(jù)和評估器不久后將開源。
方法
數(shù)據(jù)收集
為了利用軟件工程領域現(xiàn)有的研究成果,RobustAPI沒有從零構建,而是基于在線問答論壇中頻繁出現(xiàn)的Java API誤用數(shù)據(jù)集ExampleCheck

研究人員從數(shù)據(jù)集中選擇了23個流行的Java APIs,涵蓋了字符串處理、數(shù)據(jù)結構、移動開發(fā)、加密和數(shù)據(jù)庫操作等。
然后再從Stack Overflow中爬取與上述API相關的問題,只選擇問題中包含在線答案的,可以保證RobustAPI是可回答的(answerable),能夠更有效地評估LLM在「人類容易犯錯問題」上的代碼能力。
收集數(shù)據(jù)后將問題轉換為JSON格式,包含四個字段:
1. id,為樣本分配的唯一標識符
2. api,用來提示大型語言模型問題相關API
3. question,包括問題的標題和描述
4. origin,樣本的原始URL
提示生成(prompt generation)
研究人員設計了一個提示模板,并用數(shù)據(jù)集中的樣本進行填充,再從LLMs收集回復內(nèi)容,并實現(xiàn)一個API使用檢查器來評估代碼的可靠性。

在少樣本演示下進行實驗時,每個示例都提供回復的格式,然后在最后放入數(shù)據(jù)集中的問題及相應API提示,模擬新手用戶詢問時提出的問題。
LLM在對話時可以識別特殊標簽的結構,所以研究人員將問題和答案封裝起來指示LLM生成問題的答案。
演示樣本(Demonstration Samples)
為了深入分析LLMs的代碼生成能力,研究人員設計了兩個少樣本實驗:
1. one-shot-irrelevant,使用不相關的API(如Arrays.stream)作為語言模型的提示樣例。

研究人員假定該示例可以消除生成代碼中的語法錯誤。
2. one-shot-relevant,使用相同的API作為示例,包括一組問題和答案。
JAVA API誤用
研究人員在使用API時,需要充分理解API的使用規(guī)則,以便實現(xiàn)理想的API效果。
一個典型的例子是文件操作,通過RandomAccessFile打開和寫入文件時,需要注意兩條使用規(guī)則:
1. 讀取文件可能會引發(fā)異常。
如果在讀取預期字節(jié)之前達到緩沖區(qū)限制,API將拋出IndexOutOfBoundsException異常;當該文件同時被其他進程關閉時,API將拋出ClosedChannelException。
為了處理這些異常,正確的實現(xiàn)應該將API包含在try-catch塊中。
2. 使用后應應該關閉文件通道,否則的話,如果此代碼片段位于在多個實例中并發(fā)運行的長期程序中,文件資源可能會耗盡,代碼需要在所有文件操作后調(diào)用close API

另一個容易被誤用的API使用規(guī)則的例子是一個特殊的數(shù)據(jù)對象TypedArray,需要開發(fā)人員調(diào)用recycle()來手動啟用垃圾收集,否則,即使不再使用此TypedArray,Java虛擬機中的垃圾收集也不會被觸發(fā)。

在沒有垃圾回收的情況下使用該API會導致未釋放的內(nèi)存消耗,在生產(chǎn)環(huán)境部署后,在大工作負載和高并發(fā)性下會降低甚至掛起軟件系統(tǒng)。
在RobustAPI數(shù)據(jù)集中,研究人員總結了40個API使用規(guī)則,具體包括:
1. API的保護條件,在API調(diào)用之前應該檢查,例如File.exists()應該在調(diào)用File.createNewFile()之前;
2. API的調(diào)用順序,例如close()的調(diào)用應該在File.write()之后;
3. API的控制結構,例如SimpleDataFormat.parse()應該被try-catch結構所包圍。
檢測API誤用
現(xiàn)有的評估LLMs生成的代碼的研究通常使用人工編寫或自動測試生成的測試用例,但即使是高覆蓋率的測試用例也只能覆蓋語義正確性,無法模擬生產(chǎn)環(huán)境中的各種意外輸入,無法對代碼的可靠性和健壯性進行完善的評估。
為了解決這個難題,研究人員使用靜態(tài)分析的方法,在不運行測試用例的情況下,通過代碼結構分析代碼誤用,可以保證對整個程序的全面覆蓋,并且比測試解決方案的效率更高。
為了評估代碼中API用法的正確性,先從代碼片段中提取調(diào)用結果和控制結構,然后根據(jù)API使用規(guī)則檢測API誤用。
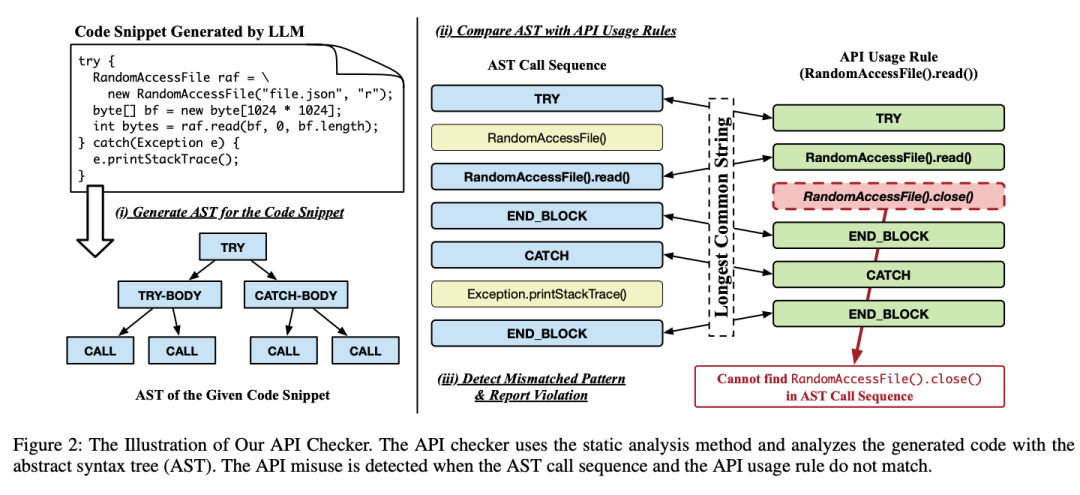
代碼檢查器(code checker)首先檢查代碼片段,判斷是一個方法的片段還是一個類的方法,然后就可以對代碼片段進行封裝,并從代碼片段中構造抽象語法樹(AST)。
然后檢查器遍歷AST,按順序記錄所有的方法調(diào)用和控制結構,從而生成一個調(diào)用序列;檢查器將調(diào)用序列與API使用規(guī)則進行比較,判斷每個方法調(diào)用的實例類型,并使用類型和方法作為鍵來檢索相應的API使用規(guī)則。
最后,檢查器計算調(diào)用序列和API使用規(guī)則之間的最長公共序列:如果調(diào)用序列與預期的API使用規(guī)則不匹配,則報告API誤用。
實驗結果
研究人員使用4個語言模型(GPT-3.5,GPT-4,Llama-2,Vicuna-1.5)在RobustAPI上進行評估。
將可編譯且包含API誤用的答案除以所有可編譯的答案后,計算得到各個語言模型的誤用率。
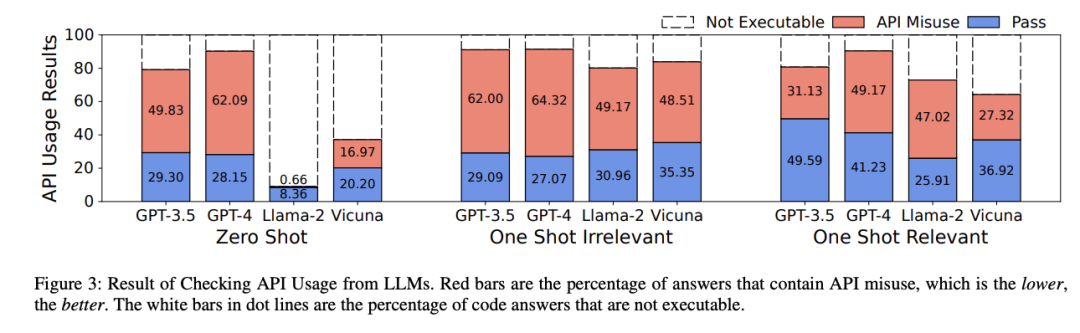
從實驗結果上來看,即便是最先進的商業(yè)模型,如GPT-3.5和GPT-4也存在誤用的問題。
在零樣本設置下,Llama的API誤用率最低,不過大多數(shù)Llama的答案中都不包含代碼。
一個與直覺相反的發(fā)現(xiàn)是,雖然OpenAI官方宣稱GPT-4比GPT-3.5在代碼生成上的性能提升達到40%,但實際上GPT-4的代碼誤用率要更高。
這一結果也表明,代碼在現(xiàn)實世界生產(chǎn)中的可靠性和健壯性沒有得到業(yè)界的重視,并且該問題存在巨大的改進空間。