上海交大發布大模型雙語編程評估基準CodeApex,機器真的開始挑戰人類寫代碼了嗎?
打造能自己寫代碼的機器,這是計算機科學和人工智能先鋒者一直在追尋的目標。而隨著 GPT 類大模型的快速發展,這樣的目標正在從遙不可及開始變得近在咫尺。
大語言模型 (Large Language Models) 的出現,讓模型的編程能力越來越受到研究者的關注。在此態勢下,上海交通大學 APEX 實驗室推出了 CodeApex-- 一個專注于評估 LLMs 的編程理解和代碼生成能力的雙語基準數據集。
在評估大語言模型的編程理解能力上,CodeApex 設計了三種類型的選擇題:概念理解、常識推理和多跳推理。此外,CodeApex 也利用算法問題和相應的測試用例來評估 LLMs 的代碼生成能力。CodeApex 總共評估了 14 個大語言模型在代碼任務上的能力。其中 GPT3.5-turbo 表現出最好的編程能力,在這兩個任務上分別實現了大約 50% 和 56% 的精度。可以看到,大語言模型在編程任務上仍有很大的改進空間,打造能自己寫代碼的機器,這樣的未來十分可期。

- 網站:https://apex.sjtu.edu.cn/codeapex/
- 代碼:https://github.com/APEXLAB/CodeApex.git
- 論文:https://apex.sjtu.edu.cn/codeapex/paper/
簡介
編程理解和代碼生成是軟件工程中的關鍵任務,在提高開發人員生產力、增強代碼質量和自動化軟件開發過程中起著關鍵作用。然而,由于代碼的復雜性和語義多樣性,這些任務對于大模型來說仍然具有挑戰性。與普通的自然語言處理相比,使用 LLMs 生成代碼需要更加強調語法、結構、細節處理和上下文理解,對生成內容的準確度有著極高要求。傳統的方法包括基于語法規則的模型、基于模板的模型和基于規則的模型,它們通常依賴于人工設計的規則和啟發式算法,這些規則和算法在覆蓋范圍和準確性方面受到限制。
近年來,隨著 CodeBERT 和 GPT3.5 等大規模預訓練模型的出現,研究人員開始探索這些模型在編程理解和代碼生成任務中的應用。這些模型在訓練期間集成了代碼生成任務,使它們能夠理解并生成代碼。然而,由于缺乏標準的、公開可用的、高質量的、多樣化的基準數據集,對 LLMs 在代碼理解和生成方面的進步進行公平的評估是很困難的。因此,建立一個廣泛覆蓋代碼語義和結構的基準數據集對于促進編程理解和代碼生成的研究至關重要。
現有的代碼基準數據集在應用于 LLMs 時,存在著適用性和多樣性的問題。例如,部分數據集更適用于評估 Bert 類型的、雙向語言建模的 LLMs。而現存的多語言代碼基準數據集(例如 Human-Eval)包含的問題比較簡單、缺乏多樣性、只能實現一些基本的功能代碼。
為了彌補以上空白,上海交通大學 APEX 數據與知識管理實驗室構建了一個新的大模型代碼理解與生成的評測基準 --CodeApex。作為一個開創性的雙語(英語,漢語)基準數據集,CodeApex 專注于評估 LLMs 的編程理解和代碼生成能力。

CodeApex 的整體實驗場景如上圖所示。
第一個任務編程理解包括 250 道單項選擇題,分為概念理解、常識推理和多跳推理。用于測試的題目選自高校的不同課程 (編程、數據結構、算法) 的期末考試題目,大大降低了數據已經在 LLMs 訓練語料庫中的風險。CodeApex 在 0-shot、2-shot、5-shot 三種場景下測試了 LLMs 的代碼理解能力,并同時測試了 Answer-Only 和 Chain-of-Thought 兩種模式對于 LLMs 能力的影響。
第二個任務代碼生成包括 476 個基于 C++ 的算法問題,涵蓋了常見的算法知識點,如二分搜索、深度優先搜索等。CodeApex 給出了問題的描述和實現問題的函數原型,并要求 LLMs 完成函數的主要部分。CodeApex 還提供了 function-only 和 function-with-context 兩種場景,它們的區別是:前者只有目標函數的描述,而后者除了目標函數的描述之外,還被提供了目標函數的調用代碼、時間空間限制、輸入輸出描述。
實驗結果表明,不同模型在代碼相關任務中的表現不同,GPT3.5-turbo 表現出卓越的競爭力和明顯的優勢。此外,CodeApex 比較了 LLMs 在雙語場景下的表現,揭示了不同的結果。總體而言,在 CodeApex 排行榜中,LLMs 的準確性仍有很大的提高空間,這表明 LLMs 在代碼相關任務中的潛力尚未被完全開發。
代碼理解
要將大語言模型完全集成到實際代碼生產場景中,編程理解是必不可少的。編程理解需要從各個方面理解代碼的能力,例如對語法的掌握、對代碼執行流程的理解以及對執行算法的理解。
CodeApex 從高校期末考試題目中抽取了 250 道選擇題作為測試數據,這些測試數據被分成了三類:概念理解、常識推理、多跳推理。

測試模式包括兩類:Answer-Only 和 Chain-of-Thought。

實驗結果與結論
CodeApex 在代碼理解任務上的中英評測結果如以下兩表所示。(表現最好的模型加粗顯示;表現次好的模型用下劃線標注。)
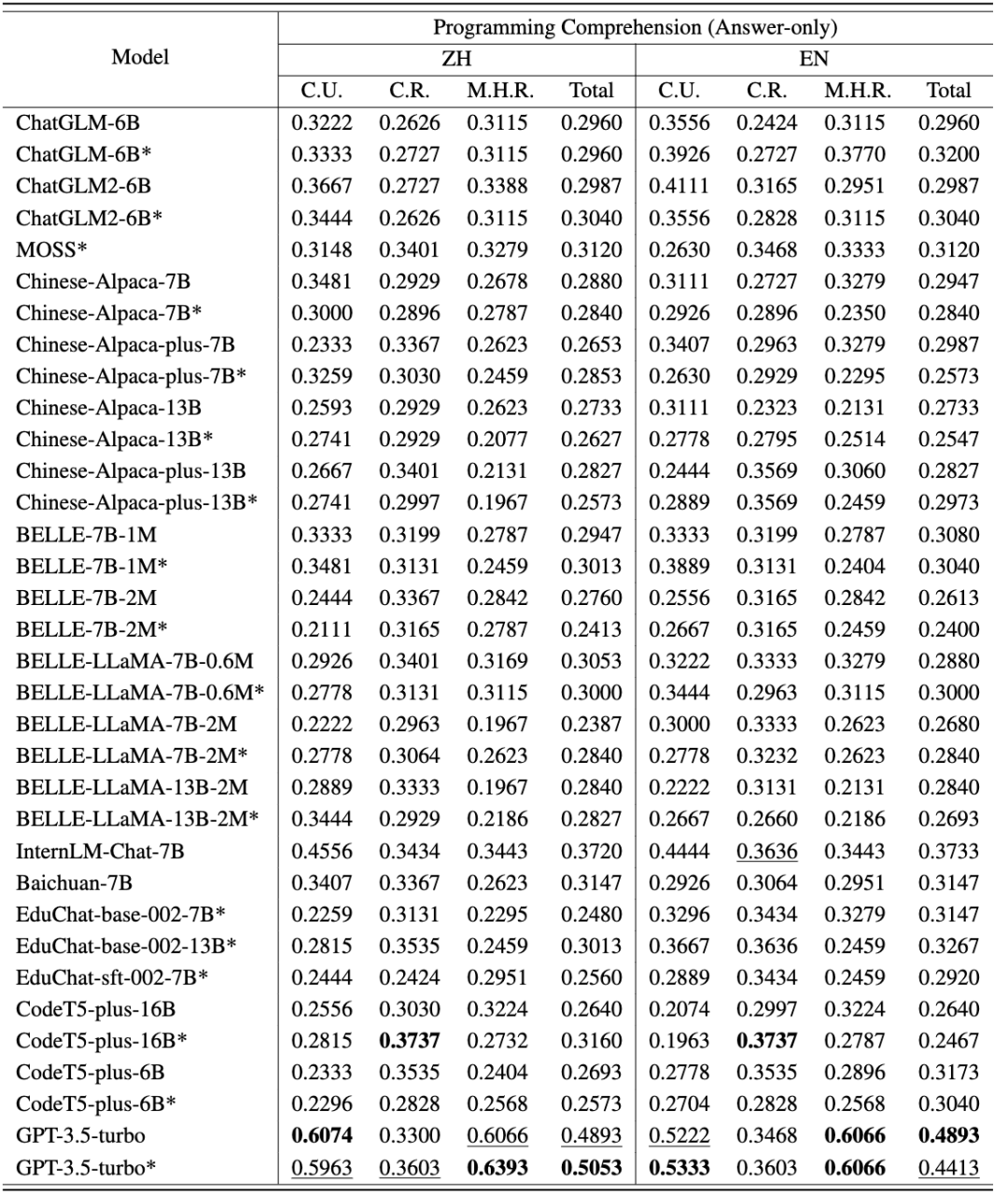

從中可以得到以下結論:
- 雙語能力比較。中文版的得分高于英文版。主要有兩個原因:(1)源題描述來源于中國高校的期末考試,因此試題最初是用中文呈現的。即使翻譯成英文,它們仍然包含了一些中國人特有的語言習慣。因此,當將這些帶有偏差的英語問題輸入到 LLMs 中時,可能會在模型的編碼結果中引入一些噪聲。(2)大多數被評估的模型主要是在中文數據上進行訓練的,這導致了較差的結果。
- 不同題型的能力比較。在這三個問題類別中,大約有一半的模型在概念理解方面表現最好,這表明它們在被訓練期間可能包含了編程概念的知識。與多跳推理相比,大多數模型在常識推理方面得分更高,這表明 LLMs 的能力隨著推理步驟的增加而顯著降低。
- CoT 思維鏈模式的作用。大多數模型在 CoT 模式下的準確度接近或低于 Answer-Only 模式。出現這種現象的原因有兩個方面:(1)評估的模型規模沒有達到具有 CoT 涌現能力的模型尺寸。此前的研究認為,CoT 的出現要求 LLMs 至少具有 60B 個參數。當參數數量不夠時,CoT 設置可能會引入額外的噪聲,LLMs 生成的響應不穩定。而 GPT3.5-turbo 已經達到了涌現能力出現點,在 CoT 設置上可以達到更高的精度。(2)在回答概念理解和常識性推理問題時,不太需要多步推理。因此,LLMs 的 CoT 能力并不能為這類問題提供幫助。然而,對于多跳推理問題,某些模型 (如 ChatGLM2、educhat 和 GPT3.5-turbo) 在 CoT 場景中的準確性有明顯提高。(由于 CodeT5 無法通過思維鏈生成響應,CodeApex 將其排除在 CoT 設置之外。)
代碼生成
訓練大語言模型生成準確且可執行的代碼是一項具有挑戰性的任務。CodeApex 主要評估 LLMs 基于給定描述生成算法的能力,并通過單元測試自動評估生成代碼的正確性。
CodeApex 的代碼生成任務包括 476 個基于 C++ 的算法問題,涵蓋了常見的算法知識點,如二分搜索和圖算法等。CodeApex 給出了問題的描述和實現問題的函數原型,并要求 LLMs 完成函數的主要部分。

CodeApex 提供了 Function-only 和 Function-with-context 兩種場景。Function-only 場景只提供了目標函數的描述,而 Function-with-context 場景不僅提供了目標函數描述,還提供了目標函數的調用代碼、 時間空間限制、輸入輸出描述。

實驗結果與結論
每種語言版本都采用了兩種 Prompt 策略 (Function-Only 和 Function-with-Context)。為了和人類代碼測試場景對齊,評估指標包括了 AC@1, AC@all 和 AC 率。



各模型的代碼生成任務結果如以下兩張表格所示。(表現最好:加粗;表現次好:下劃線。)


可以得到以下結論:
- GPT3.5-turbo 表現優于其他 11 個 LLMs,平均得分超過 50%。
- WizardCoder 和 StarCoder 排名第二和第三,突出了通過基于代碼的微調在代碼生成能力方面的顯著改進。
- 在代碼生成任務上,目前測試的模型在中英文題型上無明顯性能差異。
此外,CodeApex 還提供了每種場景中可編譯代碼的比例。在將生成函數和主函數連接起來之后,可編譯的代碼再去通過測試用例進行檢查。
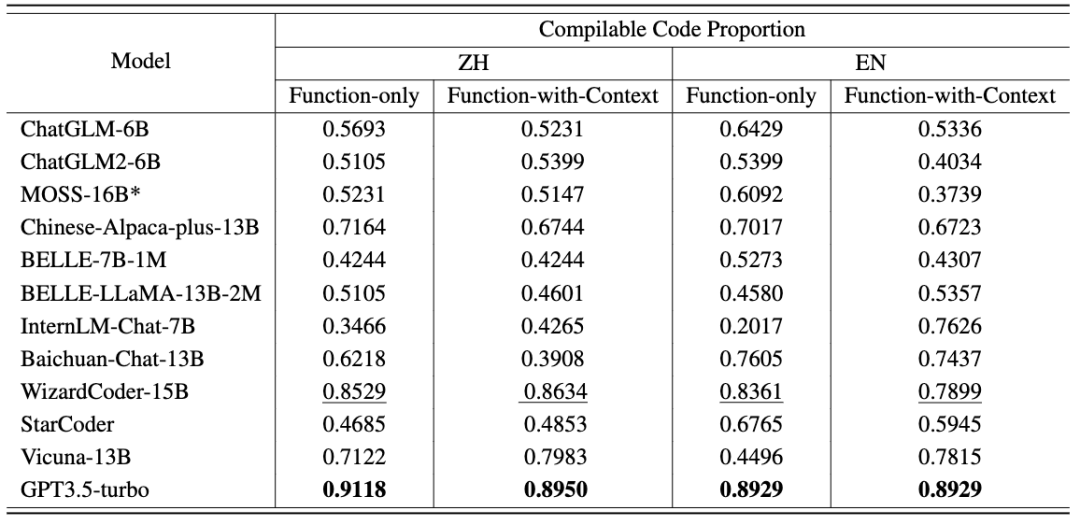
可以看到:
- 大多數模型能夠生成超過 50% 的可編譯代碼,這證明了 LLMs 理解函數原型的能力。
- 通常,提供有關函數的上下文信息可以幫助 LLMs 生成可編譯代碼。
結論
CodeApex 作為一個關注 LLMs 編程能力的雙語基準,評估了大語言模型的編程理解和代碼生成能力。在編程理解上,CodeApex 在三類選擇題中評估了不同模型的能力。在代碼生成上,CodeApex 利用測試代碼用例的通過率來評估模型的能力。對于這兩個任務,CodeApex 精心設計了 Prompt 策略,并在不同的場景下進行了比較。CodeApex 在 14 個 LLMs 上進行了實驗評估,包括通用 LLMs 和基于代碼微調的專用 LLMs 模型。
目前,GPT3.5 在編程能力方面達到了比較良好的水平,在編程理解和代碼生成任務上分別實現了大約 50% 和 56% 的精度。CodeApex 顯示,大語言模型在編程任務上的潛力尚未被完全開發。我們期待在不久的將來,利用大型語言模型生成代碼將徹底改變軟件開發領域。隨著自然語言處理和機器學習的進步,這些模型在理解和生成代碼片段方面將變得更加強大和熟練。開發人員將發現他們在編碼工作中擁有了一個前所未有的盟友,因為他們可以依靠這些模型來自動化繁瑣的任務,提高他們的生產力,并提高軟件質量。
在未來,CodeApex 將發布更多用于測試大語言模型代碼能力的測試(例如代碼校正),CodeApex 的測試數據也會持續更新,加入更多元的代碼問題。同時,CodeApex 榜單也會加入人類實驗,將大語言模型的代碼能力和人類水平做對比。CodeApex 為大語言模型編程能力的研究提供了基準與參考,將促進大語言模型在代碼領域的發展與繁榮。
APEX 實驗室簡介
上海交大 APEX 數據與知識管理實驗室成立于 1996 年,其創辦人為 ACM 班總教頭俞勇教授。實驗室致力于探索將數據有效挖掘和管理并總結出知識的人工智能技術,發表 500 篇以上國際學術論文,并追求在實際場景中的落地應用。27 年來,APEX 實驗室在多次世界技術浪潮中成為全球范圍內的先鋒者,實驗室于 2000 年開始研究語義網(現稱知識圖譜)核心技術,于 2003 年開始研究個性化搜索引擎和推薦系統技術,于 2006 年開始研究遷移學習理論與算法,于 2009 年開始探索深度學習技術并基于 GPU 開發神經網絡訓練庫。產出豐碩的科研和落地成果的同時,APEX 實驗室也鍛煉出了一支功底扎實的數據科學與機器學習研究團隊,走出了包括薛貴榮、張雷、林晨曦、劉光燦、王昊奮、李磊、戴文淵、黎珍輝、陳天奇、張偉楠、楊笛一等人工智能領域杰出校友。