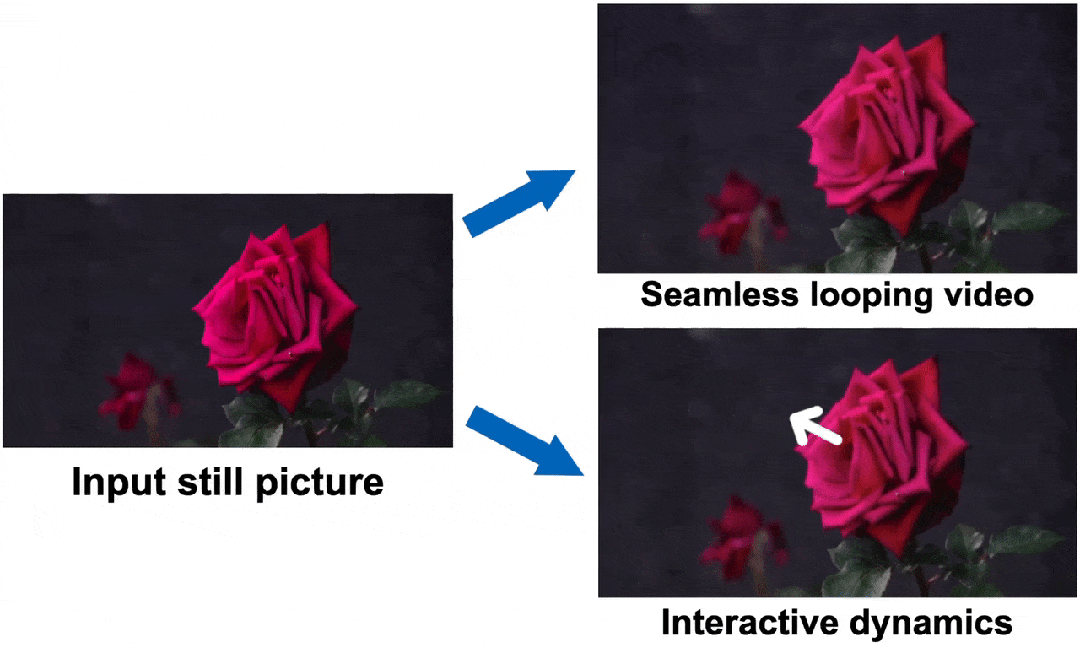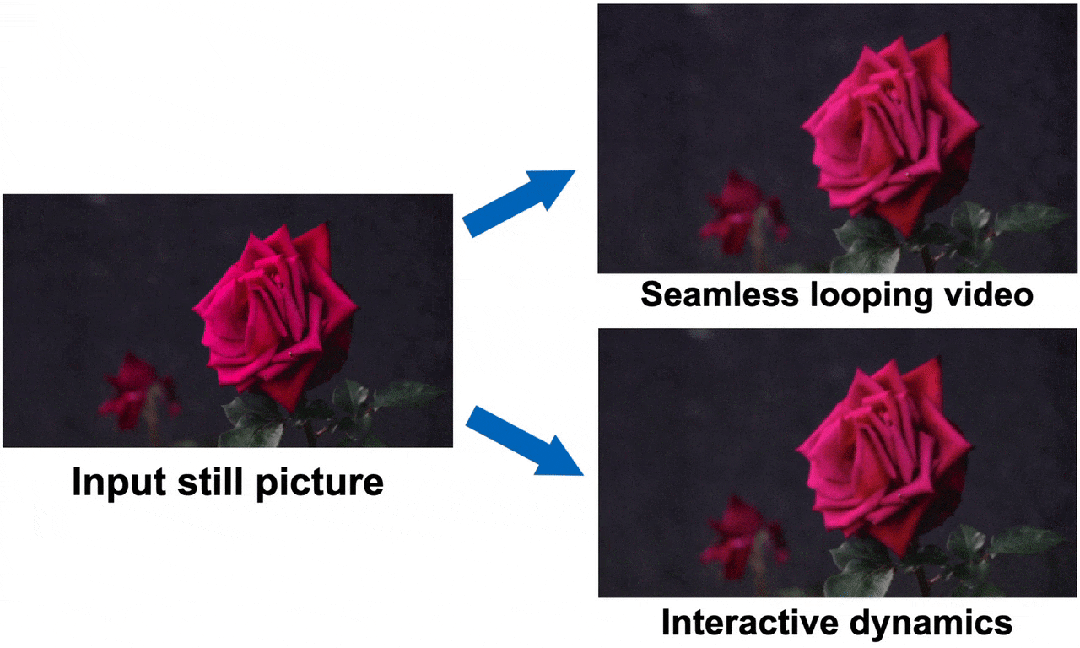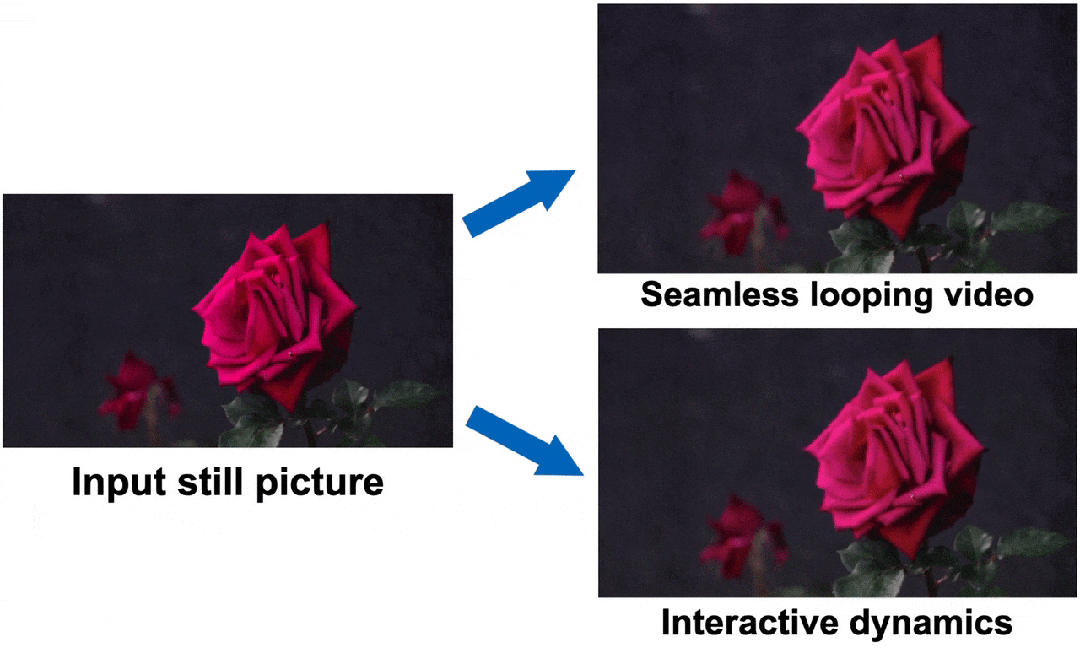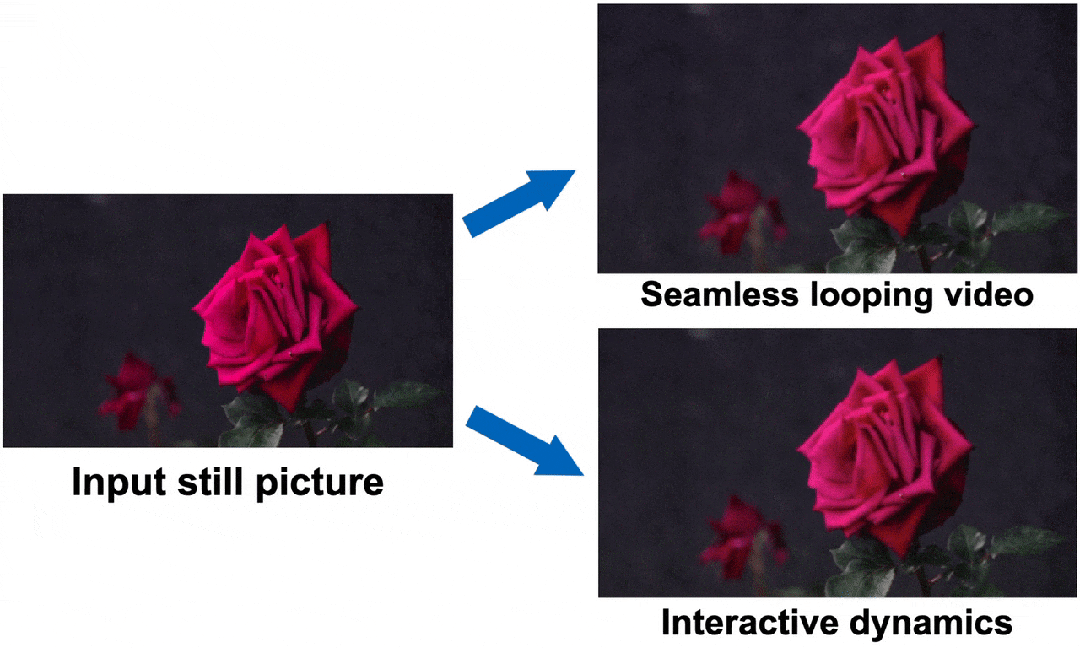
一拖一拽,玫瑰復活了!谷歌提出生成圖像動力學,從此萬物皆有靈
快看,輕輕一拉,玫瑰動就起來了。

拖著葉子往左一拉,這顆松柏向同樣的方向移動。

還有世界各種物體的圖片,隨手一拉,瞬間活靈活現。

這便是谷歌團隊最新研究,讓你的手變成「魔法金手指」,萬物皆可,一觸即動。

https://generative-dynamics.github.io/static/pdfs/GenerativeImageDynamics.pdf
在這篇論文中,谷歌提出了「Generative Image Dynamics」,通過對圖像空間先驗進行建模,然后訓練模型預測「神經隨機運動紋理」。
最后就實現了,與單個圖像交互,甚至可以生成一個無限循環的視頻。
未來,藝術家們的想象力不再受限于傳統的框架,一切皆有可能在這個動態的圖像空間實現。
圖中萬物,「活」起來了
世界中萬物的運動, 是多模態的。
院子里晾曬的衣服,隨著風前后擺動。

街邊的掛著的大紅燈籠,在空中搖擺。

還有窗簾邊睡覺的小貓,肚子呼吸的起伏,好慵懶。

這些運動并通常是可以預見的:蠟燭會以某種方式燃燒,樹木會隨著風搖曳,樹葉會沙沙作響...
拿起一張照片,或許研究人員就可以想象到,拍攝時它運動的樣子。
鑒于當前生成模型的發展,特別是擴散模型,使得人們能夠對高度豐富和復雜的分布進行建模。
這讓許多以往不可能的應用成為可能,比如文本生成任意逼真的圖像。除了在圖像領域大展身手,擴散模型同樣可以在視頻領域建模。

由此,谷歌團隊在這項研究中,對圖像空間場景運動的生成先驗進行建模,即單個圖像中所有像素的運動。
是根據從大量真實視頻序列中自動提取的運動軌跡,來進行模型訓練。
以輸入圖像為條件,訓練后的模型預測「神經隨機運動紋理」:一組運動基礎系數,用于描述每個像素未來的軌跡。
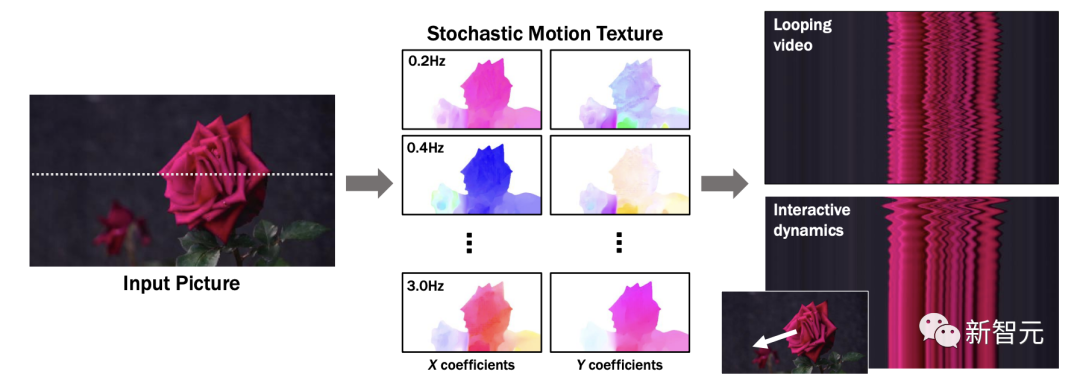
谷歌研究人員將研究范圍限定在,具有自然擺動動態的真實世界場景,如隨風飄動的樹木和花朵,因此選擇傅立葉級數作為基函數。
然后,使用擴散模型來預測「神經隨機運動紋理」,模型每次只生成一個頻率的系數,但會在不同頻段之間協調這些預測。
由此產生的頻率空間紋理,可以轉化為密集的長距離像素運動軌跡,可用于合成未來幀,將靜態圖像轉化為逼真的動畫。
接下來,具體看看是如何實現的?
技術介紹
基于單張圖片 ,研究人員的目標是生成長度為T的視頻
,研究人員的目標是生成長度為T的視頻 ,這段視頻能夠呈現動態的樹木、花朵,或者是在微風中搖曳的蠟燭火焰等。
,這段視頻能夠呈現動態的樹木、花朵,或者是在微風中搖曳的蠟燭火焰等。
研究人員的構架的的系統由兩個模塊組成:「動作預測模塊」和「基于圖像的渲染模塊」。
首先,研究人員使用「潛在擴散模型」為輸入圖片 預測一個神經隨機運動紋理
預測一個神經隨機運動紋理
它是輸入圖像中每個像素運動軌跡的頻率表示。
第二步,使用逆離散傅立葉變換將預測出的隨機運動紋理轉化為一系列運動位移場(motion displacement fields) 。
。
這些運動位移場將用于確定每個輸入像素在每一個未來時間步長的位置。
有了這些預測的運動場,研究人員的渲染模塊使用基于圖像的渲染技術,從輸入的RGB圖像中拾取編碼特征,并通過圖像合成網絡將這些拾取的特征解碼為輸出幀。
神經隨機運動紋理
運動紋理
之前的研究中,運動紋理定義了一系列時變的2D位移映射( displacement map)

其中,每個像素坐標p,從輸入圖像 中的2D位移向量定義了該像素在未來時間t的位置。
中的2D位移向量定義了該像素在未來時間t的位置。
為了在時間t生成一個未來幀,可以使用相應的位移映射,從 中拾取像素,從而得到一個前向變形的圖像:
中拾取像素,從而得到一個前向變形的圖像:
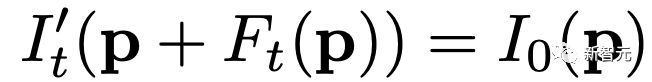
隨機運動紋理
正如之前在計算機圖形研究中所證明的,許多自然運動,特別是振蕩運動,可以描述為一小組諧振子(harmonic oscillators)的疊加,這些諧振子用不同的頻率、振幅和相位表示。
一種引入運動的隨機性的方法是整合噪聲場。但正如之前研究結果表明的,直接在預測的運動場的空間和時間域內添加隨機噪聲通常會導致不現實或不穩定的動畫。
更進一步,采用上面定義的時間域內的運動紋理意味著需要預測T個2D位移場,才能生成一個包含T幀的視頻片段。為了避免預測如此大的輸出表示,許多先前的動畫方法要么自回歸地生成視頻幀,要么通過額外的時間嵌入獨立預測每個未來的輸出幀。
然而,這兩種策略都不能確保生成的視頻幀在長期內具有時間上的一致性,而且都可能產生隨時間漂移或發散的視頻。
為了解決上述問題,研究人員在頻率域中表示輸入場景的每像素運動紋理(即所有像素的完整運動軌跡),并將運動預測問題表述為一種多模態的圖像到圖像的轉換任務。
研究人員采用潛在擴散模型(LDM)生成由一個4K通道的2D運動光譜圖組成的隨機運動紋理,其中K << T是建模的頻率數,而在每個頻率上,研究人員需要四個標量來表示x和y維度的復傅立葉系數。
下圖展示了這些神經隨機運動紋理。

那么,應該如何選擇研究人員表示的 K 輸出頻率呢?實時動畫之前的研究說明,大多數自然振蕩運動主要由低頻分量(low-frequency component)組成。
為了驗證這一假設,研究人員計算了從1000個隨機抽樣的5秒真實視頻剪輯中提取出來的運動的平均功率譜。如下圖左圖所示,功率主要集中在低頻分量上。

動作的頻譜隨著頻率的增加呈指數下降。這表明大多數自然振動動作確實可以由低頻項很好地表示。
在實踐中,研究人員發現前K=16個傅里葉系數足以在一系列真實視頻和場景中真實地重現原始的自然動作。
使用擴散模型預測動作
研究人員選擇潛在擴散模型(LDM)作為研究人員的動作預測模塊的核心,因為LDM在保持生成質量的同時,比像素空間擴散模型更加計算高效。
一個標準的LDM主要包括兩個模塊:
1.一個變分自編碼器(VAE)通過編碼器z = E(I)將輸入圖像壓縮到潛在空間,然后通過解碼器I = D(z)從潛在特征中重構輸入。
2.一個基于U-Net的擴散模型,這個模型學會從高斯隨機噪聲開始迭代地去噪潛在特征。
研究人員的訓練不是應用于輸入圖像,而是應用于來自真實視頻序列的隨機動作紋理,這些紋理被編碼然后在預定義的方差時間表中擴散n步以產生噪聲潛在變量zn。
頻率自適應歸一化(Frequency adaptive normalization)
研究人員觀察到一個問題,隨機動作紋理在頻率上具有特定的分布特性。上圖的左側圖所示,研究人員的動作紋理的幅度范圍從0到100,并且隨著頻率的增加大致呈指數衰減。
由于擴散模型需要輸出值位于0和1之間以實現穩定的訓練和去噪,因此研究人員必須在用它們進行訓練之前歸一化從真實視頻中提取的S系數。
如果研究人員根據圖像寬度和高度將S系數的幅度縮放到[0,1],那么在較高頻率處幾乎所有的系數都會接近于零,上圖(右側)所示。
在這樣的數據上訓練出的模型可能會產生不準確的動作,因為在推理過程中,即使是很小的預測誤差也可能在反歸一化后導致很大的相對誤差,當歸一化的S系數的幅度非常接近于零時。
為了解決這個問題,研究人員采用了一種簡單但有效的頻率自適應歸一化技術。具體而言,研究人員首先根據從訓練集中計算的統計數據獨立地對每個頻率處的傅里葉系數進行歸一化。
頻率協調去噪(Frequency-coordinated denoising)
預測具有K個頻率帶的隨機動作紋理S的直接方法是從標準擴散U-Net輸出一個具有4K通道的張量。
然而,訓練一個模型以產生如此大量的通道往往會產生過度平滑和不準確的輸出。
另一種方法是通過向LDM注入額外的頻率嵌入來獨立預測每個單獨頻率處的動作光譜圖,但這會導致頻率域中的不相關預測,從而產生不真實的動作。
因此,研究人員提出了下圖中所示的頻率協調去噪策略。具體來說,給定一個輸入圖像I0,研究人員首先訓練一個LDM來預測具有四個通道的每個單獨頻率的隨機動作紋理圖,其中研究人員將額外的頻率嵌入和時間步嵌入一起注入到LDM網絡中。

基于圖像的渲染
研究人員進一步描述如何利用為給定輸入圖像I0預測的隨機運動紋理S來渲染未來時刻t的幀?It。首先,研究人員使用逆時域FFT(快速傅里葉變換)在每個像素點p處計算運動軌跡場

這些運動軌跡場決定了每一個輸入像素在未來每一個時間步長的位置。為了生成未來的幀It,研究人員采用深度圖像基渲染技術,并執行使用預測的運動場的前向扭曲(splatting)來扭曲編碼的I0,如下圖所示。

由于前向扭曲可能導致圖像出現空洞,以及多個源像素可能映射到相同的輸出2D位置,研究人員采用了先前在幀插值研究中提出的特征金字塔Softmax扭曲策略。
研究人員共同訓練特征提取器和合成網絡,用從真實視頻中隨機抽取的起始和目標幀,其中研究人員使用從I0到It的估計流場來扭曲I0的編碼特征,并用VGG感知損失對預測的?It進行監督。

如上圖所示,與直接平均扭曲和基線深度扭曲方法相比,研究人員的運動感知特征扭曲生成了一個沒有空洞或者人工痕跡的幀。
進一步的擴展應用
研究人員進一步展示了利用研究人員提出的運動表示和動畫流程,為單張靜態圖像添加動態效果的應用。
圖像到視頻
研究人員的系統通過首先從輸入圖像預測出一個神經隨機運動紋理,并通過應用研究人員基于圖像的渲染模塊到從隨機運動紋理派生出的運動位移場,實現了單張靜態圖片的動畫生成。
由于研究人員明確地對場景運動進行了建模,這允許研究人員通過線性插值運動位移場來生成慢動作視頻,并通過調整預測的隨機運動紋理系數的振幅來放大(或縮小)動畫運動。
無縫循環
有時生成具有無縫循環運動的視頻是非常有用的,意味著視頻開始和結束之間沒有外觀或運動的不連續性。
不幸的是,很難找到一個大量的無縫循環視頻的訓練集。因此,研究人員設計了一種方法,使用研究人員的運動擴散模型,該模型訓練在常規的非循環視頻片段上,以產生無縫循環的視頻。
受近期有關圖像編輯指導研究的啟發,研究人員的方法是一種運動自引導技術,該技術使用明確的循環約束來引導運動去噪采樣過程。
具體來說,在推斷階段的每個迭代去噪步驟中,研究人員在標準的無分類器引導旁邊加入了一個額外的運動引導信號,其中研究人員強制每個像素在開始和結束幀的位置和速度盡可能相似。
從單一圖像生成可交互的動畫
振蕩物體的觀察視頻中的圖像空間運動譜近似于該物體的物理振動模態基礎。
模態形狀捕獲了物體在不同頻率下的振蕩動態,因此物體振動模式的圖像空間投影可以用于模擬物體對用戶定義的力(如戳或拉)的反應。
因此,研究人員采用了之前研究的模態分析技術,該技術假設物體的運動可以由一組諧振子的疊加來解釋。
這使得研究人員將物體的物理響應的圖像空間二維運動位移場寫為傅里葉譜系數與每個模擬時間步驟t的復模態坐標,以及時間t的加權和。
實驗評估
研究團隊對最新方法,與基線方法在未見視頻片段測試集上進行了定量比較。
結果發現,谷歌的方法在圖像和視頻合成質量方面都顯著優于先前的單圖像動畫基線。
具體來說,谷歌的FVD和DT-FVD距離要低得多,這表明這一方法生成的視頻更加真實且時間上更加連貫。

更進一步地,圖6顯示了不同方法生成的視頻的滑動窗口 FID 和滑動窗口 DT-FVD 距離。
由于谷歌采用了全局隨機運動紋理表示,其方法生成的視頻在時間上更加一致,并且不會隨著時間的推移而發生漂移或退化。

另外,谷歌團隊通過2種方式,對自己的方法和基線生成的視頻進行可視化定性比較。
首先,展示了生成視頻的X-t時空切片,如圖7所示。
谷歌生成的視頻動態,與相應真實參考視頻(第二列)中觀察到的運動模式更為相似。隨機I2V和MCVD等基線無法隨著時間的推移真實地模擬外觀和運動。

我們還通過可視化預測圖像 及其在時間t =128時相應的運動位移場,定性比較不同方法中各個生成的幀和運動的質量。
及其在時間t =128時相應的運動位移場,定性比較不同方法中各個生成的幀和運動的質量。
與其他方法相比,谷歌生成的方法生成的幀表現出較少的偽影和失真,相應的二維運動場與從相應的真實視頻中估算出的參考位移場最為相似。

消融研究:從表2中觀察到,與完整模型相比,所有更簡單或替代的配置都會導致性能更差。

作者介紹
Zhengqi Li

Zhengqi Li是谷歌研究院的一名研究科學家。他的研究興趣包括,3D/4D計算機視覺、基于圖像的渲染和計算攝影,尤其是in the wild圖像和視頻。他在康奈爾大學獲得了計算機科學博士學位,導師是Noah Snavely。
他是CVPR 2019最佳論文榮譽提名獎、2020年谷歌博士獎學金、2020年奧多比研究獎學金、2021年百度全球人工智能100強中國新星獎和CVPR 2023最佳論文榮譽獎的獲得者。