













多模態融合全新框架 | FusionFormer:BEV時空融合新高度!
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。

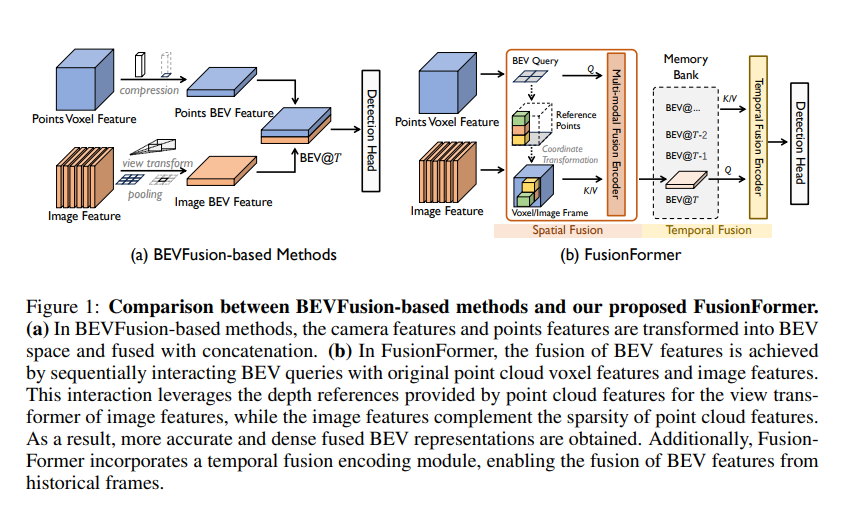
我們這篇論文解讀介紹了一種名為FusionFormer的多模態融合框架,用于三維目標檢測。該框架旨在解決自動駕駛中的一些挑戰,包括傳感器之間的差異以及信息融合的有效性。
在自動駕駛技術中,通常會使用多個傳感器來提高安全性,例如激光雷達、攝像頭和雷達。這些傳感器具有不同的特點,例如激光雷達可以提供準確但稀疏的三維點云信息,而圖像具有密集的特征但缺乏深度信息。為了提高性能,可以使用多模態融合來整合這些傳感器的優點。通過結合多個傳感器的信息,自動駕駛系統可以實現更高的準確性和魯棒性,從而在實際應用中更可靠。
傳統的多模態特征融合方法通常使用簡單的拼接操作將不同傳感器的特征在鳥瞰圖空間中進行拼接。然而,這些方法存在一些局限性。首先,在這些方法中,為了得到點云的鳥瞰圖特征,點云的Z軸信息被壓縮到通道維度中,這可能導致高度信息的丟失。這可能會影響涉及高度信息的下游任務的性能,例如需要預測邊界框的高度的三維目標檢測。其次,目前的方法獨立地獲取來自圖像和點云的鳥瞰圖特征,沒有充分利用每種模態的互補優勢。例如,將圖像特征轉換為鳥瞰圖特征的過程嚴重依賴于準確的深度預測。然而,單目深度預測是一個不適定問題,很難實現高精度。不準確的深度預測可能導致視角變換錯誤,影響檢測性能。實際上,稀疏的激光雷達點云特征可以提供補充的深度信息,以提高視角變換的準確性。然而,目前的方法未能有效地利用這個潛力。
為了解決這些問題,我們提出了一種名為FusionFormer的新型多模態融合框架。FusionFormer通過使用可變形注意力順序地融合激光雷達和圖像特征,可以生成融合的鳥瞰圖特征。通過開發一種統一的采樣策略,FusionFormer可以同時從二維圖像和三維體素特征中進行采樣,從而在不同模態輸入之間展現出靈活的適應性。因此,多模態特征可以以它們的原始形式輸入,避免了轉換為鳥瞰圖特征時的信息損失。在融合編碼過程中,點云特征可以作為圖像特征的視角變換的深度參考,而來自圖像的稠密語義特征則互補了點云特征的稀疏性,從而生成更準確和更密集的融合的鳥瞰圖特征。值得注意的是,多模態融合編碼器采用了殘差結構,確保了模型在缺失點云或圖像特征的情況下的魯棒性。此外,FusionFormer還支持歷史鳥瞰圖特征的時間融合,使用了基于可變形注意力的插件式時間融合模塊。當與三維目標檢測頭部結合時,FusionFormer可以進行端到端的訓練,并具有最先進的性能。此外,基于FusionFormer對輸入模態表示的靈活適應性,論文還提出了一種方法,利用單目深度預測結果而不是激光雷達分支來提高基于攝像頭的三維目標檢測的性能。
我們的方法
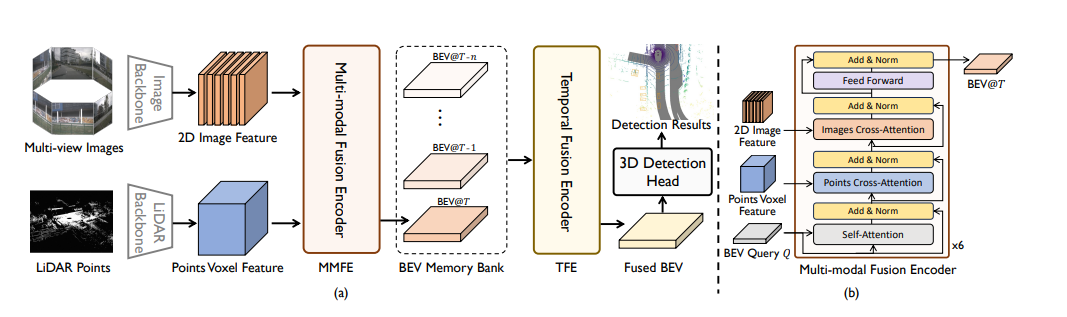
1 MULTI-MODAL BRANCHES
MULTI-MODAL BRANCHES是FusionFormer方法中用于處理多模態特征的分支。
- Camera Branch:該分支用于從多視圖相機圖像中提取圖像特征。通常使用諸如ResNet-101等骨干網絡提取圖像特征。提取的圖像特征經過Feature Pyramid Network (FPN)處理,生成多尺度的圖像特征。
- LiDAR Branch:FusionFormer方法支持多種多模態特征的表示形式。該研究探索了兩種不同的LiDAR特征表示形式,具體是BEV(Bird's Eye View)特征和體素特征。原始的點云數據經過體素化處理,并通過稀疏的三維卷積操作進行處理。在一種情況下,通過使用三維卷積操作對體積表示進行編碼,得到體素特征。在另一種情況下,將特征的Z軸壓縮到通道維度,并使用二維卷積操作獲取BEV特征。
通過這些多模態分支,FusionFormer方法能夠同時處理來自相機和LiDAR的多模態特征,為后續的融合和目標檢測任務提供豐富的輸入信息。
2 MULTI-MODAL FUSION ENCODER
Multi-modal Fusion Encoder是FusionFormer方法中的一個模塊,用于融合多模態特征。該模塊包含6個編碼層,每個編碼層都包括自注意力(self-attention)、點云交叉注意力(points cross-attention)和圖像交叉注意力(image cross-attention)。下面對Multi-modal Fusion Encoder的各個部分進行介紹:
- BEV Queries(BEV查詢):首先,將BEV(Bird's Eye View)空間劃分為網格,每個網格單元對應一個BEV查詢。在輸入到融合編碼器之前,對BEV查詢進行位置編碼,根據其對應的BEV空間坐標進行操作。
- Self-Attention(自注意力):為了減少計算資源的使用,采用了基于可變形注意力的自注意力機制。每個BEV查詢只與其在ROI范圍內的相應查詢進行交互。通過在每個查詢的2D參考點進行特征采樣來實現交互。
- Points Cross-Attention(點云交叉注意力):該層也采用了可變形注意力機制,但根據LiDAR特征的形式的不同,實現點云交叉注意力的方式有所不同。當使用BEV特征作為輸入時,點云交叉注意力層的實現如下所示。它將BEV特征作為輸入,并在LiDAR分支輸出的BEV特征上執行可變形注意力操作。
- Image Cross-Attention(圖像交叉注意力):圖像交叉注意力的實現方式與點云交叉注意力類似,但是針對使用體素特征作為輸入的情況。由于圖像具有多個視角,每個查詢的3D參考點只能投影到一部分相機視圖上。因此,在圖像交叉注意力過程中,僅將可投影的相機視圖作為參與計算的對象。
通過這些編碼層的多次迭代,最終得到融合了多模態特征的BEV特征。Multi-modal Fusion Encoder模塊的目標是通過自注意力、點云交叉注意力和圖像交叉注意力相互作用,充分利用不同模態的信息,提高特征的表達能力和融合效果。
3 TEMPORAL FUSION ENCODER

TFE包括三個層,每個層都包括BEV時間注意力(BEV temporal-attention)和前饋網絡(feedforward networks)。在第一層,查詢(queries)使用當前幀的BEV特征進行初始化,并通過歷史BEV特征的時間注意力進行更新。得到的查詢通過前饋網絡進行處理,并作為下一層的輸入。經過三層融合編碼后,得到最終的時間融合BEV特征。
時間注意力的過程可以表示為:
其中,表示時間時刻的BEV特征。
上述公式表示,在時間注意力過程中,通過對歷史幀的BEV特征與當前查詢進行自注意力操作,得到加權的歷史特征表示。
TFE模塊通過多層的時間注意力和前饋網絡,實現了時間序列數據的融合編碼。它充分利用了歷史幀的信息,通過自注意力機制對查詢進行更新,從而得到更準確的時間融合BEV特征。TFE模塊的輸出可以作為后續的3D檢測頭(3D Detection Head)的輸入,用于直接生成BEV特征的3D檢測框和速度預測,無需進行后處理的非最大抑制(NMS)操作。
4 3D DETECTION HEAD
論文提出了基于Deformable DETR的3D檢測頭,它可以直接從BEV特征輸出3D檢測框和速度預測,無需進行NMS后處理。為了解決類似DETR檢測頭中遇到的不穩定匹配問題并加快訓練收斂速度,論文提出了一種受DN-DETR啟發的新方法。在訓練過程中,論文使用帶有噪聲的真實編碼(ground-truth encodings)增強查詢,并通過將預測結果與真實值進行直接比較來計算損失,而無需進行匹配過程。
5 FUSION WITH DEPTH PREDICTION
為了在僅有相機圖像的場景中近似點云分支,FusionFormer具有很高的靈活性,可以添加基于圖像的單目深度預測分支。如圖所示,我們提出了一個深度預測網絡,用于從輸入圖像特征生成基于區間的深度預測。利用3D卷積將深度預測結果編碼為每個相機視錐體中的體素特征。然后,采用深度交叉注意力來融合深度特征。深度交叉注意力的過程定義如下:
其中,表示第j個相機的編碼深度預測特征,表示查詢的第i個三維參考點在第j個相機的視錐體坐標系上的投影點。上述公式表示,在深度交叉注意力過程中,通過將查詢與每個相機視錐體中的投影點進行自注意力操作,對深度特征進行加權融合。Fusion with Depth Prediction模塊利用深度預測網絡生成的深度特征,并通過深度交叉注意力機制將其與其他模態的特征進行融合。這樣,即使只有相機圖像,也能夠近似地捕捉到點云的信息,并與其他模態的特征相結合,提高最終的融合特征的表達能力。
實驗對比分析

根據提供的實驗結果表格,我們可以進行以下結果分析:
- 模態對比:從表格中可以看出,使用多模態數據(Camera和LiDAR)的方法(如BEVFusion、CMT和DeepInteraction)在大多數評估指標上表現較好。單獨使用相機或LiDAR數據的方法(如BEVFusion和BEVFusion4D)相對而言表現較差。這說明多模態信息的融合可以提高3D檢測的性能。
- 時間信息對比:與只使用當前幀信息的方法相比,使用時間序列信息的方法(如BEVFusion4D和FusionFormer)在NDS、mATE和mAOE等指標上取得了更好的結果。這表明引入時間序列數據有助于改善3D檢測的穩定性和準確性。
- FusionFormer性能:FusionFormer在大多數評估指標上都達到了最佳結果。它在NDS指標上超過了其他方法,并在mAAE指標上達到了最低值。這表明FusionFormer在綜合性能和平均角度誤差方面優于其他方法。
也就是說FusionFormer方法在多模態數據和時間序列數據的融合上取得了良好的效果,具有較高的性能和穩定性,能夠直接從BEV特征中輸出3D檢測框和速度預測,無需進行后處理的非最大抑制(NMS)操作。

根據實驗結果表格的數據對比,在nuScenes數據集的驗證集上,我們對比了多種方法的性能。多模態數據融合方法,如BEVFusion、CMT和DeepInteraction,展現了相對較好的mAP和NDS指標,說明多模態信息的綜合利用對于3D檢測的性能至關重要。同時,引入時間序列信息的方法,如BEVFusion4D和FusionFormer,在mAP和NDS指標上取得了更好的結果,這表明時間序列數據對于提高3D檢測的準確性和穩定性具有積極影響。
在這些方法中,FusionFormer在綜合性能上表現出色。它通過有效地融合相機、LiDAR和時間序列數據,能夠直接從BEV特征中輸出3D檢測結果,無需進行后處理的非最大抑制(NMS)操作。FusionFormer在mAP和NDS指標上均取得最佳結果,超過了其他方法。這顯示出FusionFormer在復雜場景下具有強大的檢測能力和魯棒性。

因此,綜合考慮多模態數據融合和時間序列信息的重要性,以及FusionFormer在綜合性能上的優勢,我們可以得出結論:FusionFormer方法在nuScenes數據集上展現出卓越的性能,為3D檢測任務提供了一種效果優秀且高效的解決方案。
一些討論

我們這個工作的優點之一是它對多模態數據融合和時間序列信息的重要性進行了深入的研究和探討。通過將相機和LiDAR數據進行融合,并引入時間序列信息,論文提出了一種名為FusionFormer的方法,該方法在3D檢測任務中取得了出色的性能。這種綜合利用多模態數據和時間序列數據的策略,能夠提高檢測的精度和魯棒性,使得系統能夠在復雜場景下更好地理解和預測物體的行為。
另一個優點是FusionFormer方法的直接輸出特征,避免了后處理的非最大抑制(NMS)操作。這種設計簡化了系統流程,提高了實時性和效率,并且有助于減少信息損失和誤差傳播。此外,FusionFormer還能夠直接從BEV特征中輸出3D檢測結果,進一步簡化了系統架構。
然而,論文也存在一些潛在的缺點。首先,盡管FusionFormer在實驗中展現了出色的性能,但其在其他數據集或場景中的泛化能力仍需進一步驗證。其次,論文可能沒有充分探索模型的可解釋性和推理過程,缺乏對于模型決策的解釋和可視化分析。此外,論文可能沒有對實驗結果的統計顯著性進行詳細的討論,如假設檢驗或置信區間分析,以確認結果的可靠性和一致性。
總體而言,這篇論文通過提出FusionFormer方法,系統地探索了多模態數據融合和時間序列信息在3D檢測任務中的重要性,并在實驗中取得了令人滿意的結果。然而,在進一步研究中,應該考慮驗證其泛化能力、加強模型的可解釋性分析,并對實驗結果進行更全面的統計推斷。
結論

本論文提出了一種名為FusionFormer的方法,通過綜合利用多模態數據融合和時間序列信息,實現了在3D檢測任務中的優秀性能。FusionFormer能夠直接從BEV特征中輸出3D檢測結果,避免了后處理的非最大抑制(NMS)操作,簡化了系統架構并提高了實時性和效率。實驗結果表明,FusionFormer在多模態數據和時間序列數據的融合上取得了出色的性能,在mAP和NDS等指標上超過了其他方法。然而,進一步的研究還需要驗證其泛化能力、加強模型的可解釋性分析,并對實驗結果進行更全面的統計推斷。總體而言,FusionFormer為3D檢測任務提供了一種有效且高效的解決方案,具有廣闊的應用前景。





















