RLHF何以成LLM訓練關鍵?AI大牛盤點五款平替方案,詳解Llama 2反饋機制升級
在ChatGPT引領的大型語言模型時代,一個繞不過去的話題就是「基于人類反饋的強化學習」(RLHF),不僅提升了語言模型的性能,也將人類社會的價值觀注入到模型中,使得語言模型能夠幫助用戶解決問題,提高模型的安全性。
不過在ChatGPT之后,大量模型和相關技術不斷發布,RLHF也早已更新換代,并衍生出來一些無需人工的微調方法,效果提升也很明顯。
最近,Lightning AI創始人、AI研究大牛Sebastian Raschka發表了一篇博客,描述了Llama 2中的RLHF機制和原版相比做出了哪些改變和提升,還介紹了幾個RLHF算法的替代方案。

經典LLM的訓練流程
目前最先進的、基于Transformer的大型語言模型,例如ChatGPT或Llama 2,大體都包括三個訓練步驟:預訓練,有監督微調和對齊。
在預訓練階段,模型會吸收來自海量、無標注文本數據集的知識,然后使用有監督微調細化模型以更好地遵守特定指令;最后使用對齊技術使LLM可以更有用且更安全地響應用戶提示。
1. 預訓練(Pretraining)
預訓練階段通常需要包含數十億到數萬億個token的龐大文本語料庫,但訓練目標只是一個簡單的「下一個單詞預測」(next word prediction)任務,模型需要根據提供的文本來預測后續單詞或token。

自監督預訓練可以讓模型從大規模的數據中學習,只要能夠在不侵犯版權,或是無視創造者偏好的情況下收集到數據,就可以不依賴人工標注完成訓練,因為訓練標簽實際上就是文本的后續單詞,已經暗含在數據集中了。
2. 有監督微調(Supervised finetuning)
第二階段大體上來看也是「next token prediction」任務,不過需要人工標注的指令數據集,其中模型的輸入是一個指令(根據任務的不同,也可能包含一段文本),輸出為模型的預期回復內容。

數據形式類似于:
Instruction: "Write a about a pelican."
使用說明:“寫一首關于鵜鶘的打油詩。“
Output: "There once was a pelican so fine..."
輸出:“從前有一只鵜鶘很好...“
模型會將指令文本作為輸入,并逐個token輸出,訓練目標是與預期輸出相同。
雖然兩個階段都采用相似的訓練目標,但有監督微調數據集通常比預訓練數據小得多,指令數據集需要人類(或其他高質量的LLM)提供標注結果,所以無法大規模應用。
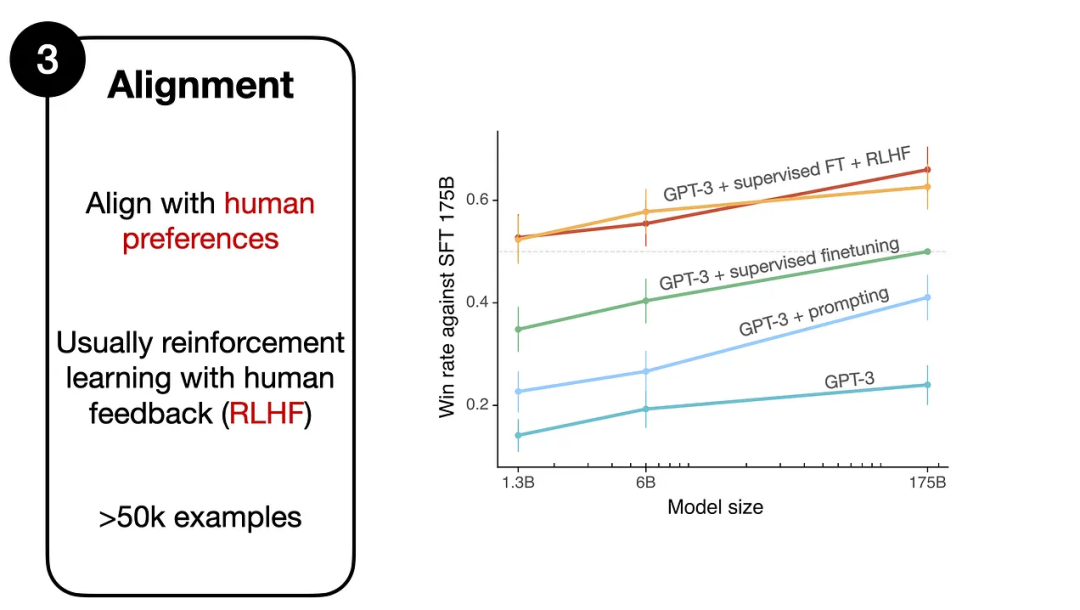
3. 對齊(Alignment)
第三階段依然是微調,不過其主要目標在于將語言模型與人類的偏好、價值觀進行對齊,也是RLHF機制發揮作用的地方。
RLHF主要包括三步:
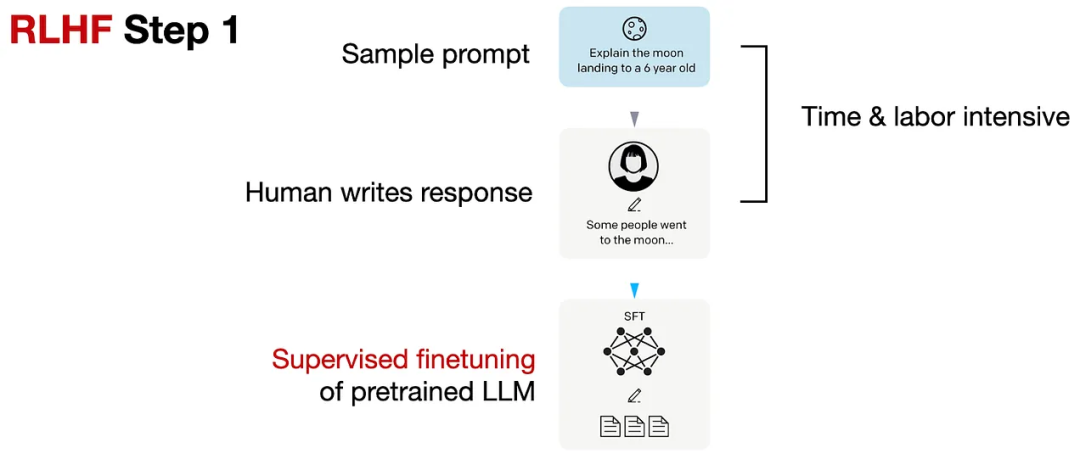
Step 1. 預訓練模型的有監督微調
先收集一個提示詞集合,并要求標注人員寫出高質量的回復,然后使用該數據集以監督的方式微調預訓練的基礎模型。
Step 2. 創建獎勵模型
對于每個提示,要求微調后的LLM生成四到九個回復,再由標注人員根據個人偏好對所有回復進行排序。
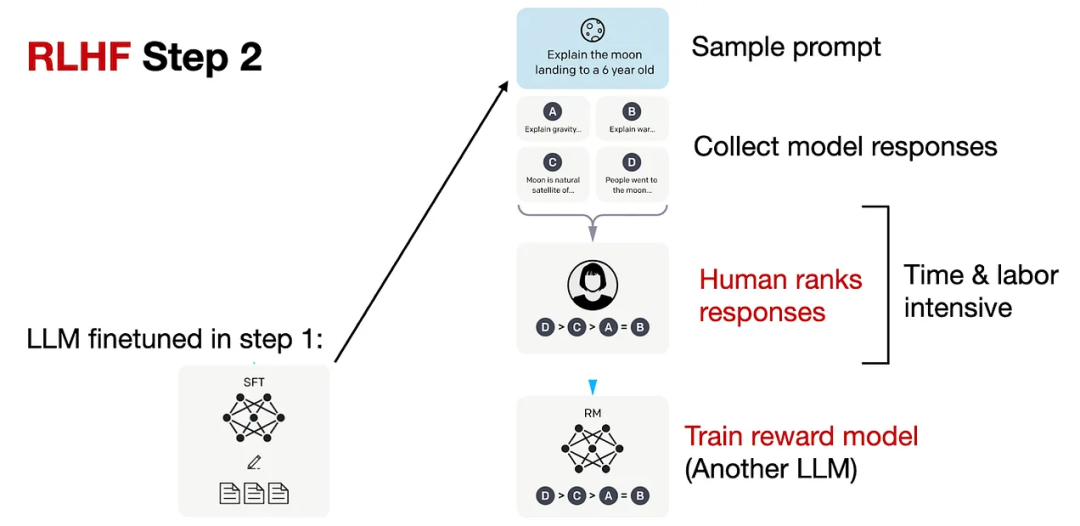
雖然排序過程很耗時,但工作量還是比第一步的數據集構建少一些。
在處理排序結果時,可以設計一個獎勵模型RM,將微調語言模型SFT的輸出通過一個回歸層(單個輸出節點)轉換為獎勵分數,用于后續優化。
Step 3.PPO微調
使用鄰近策略優化(PPO,proximal policy optimization ),根據獎勵模型提供的獎勵分數對SFT模型進一步優化。
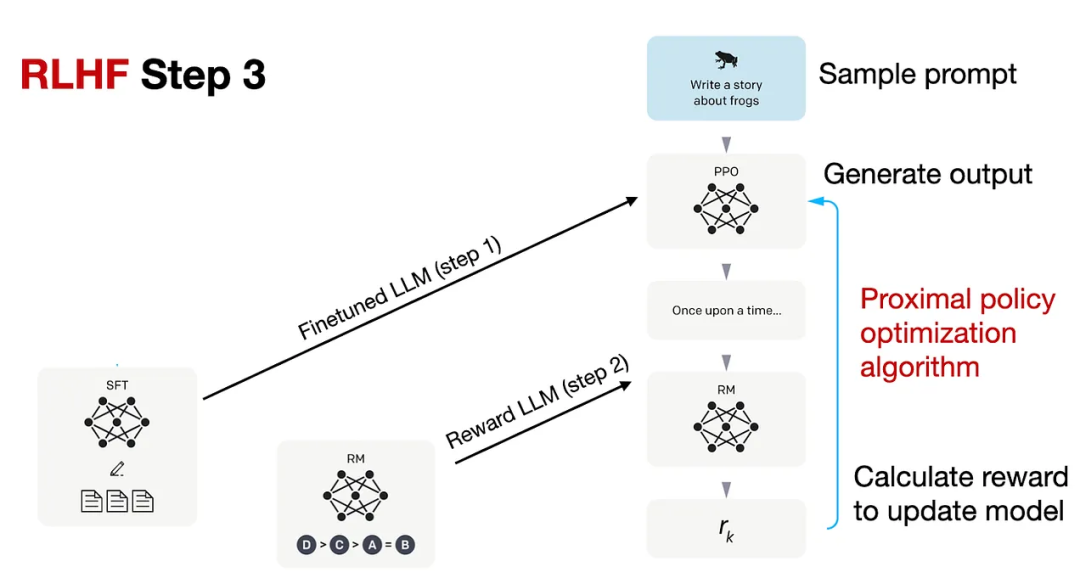
PPO的具體技術細節可以參考InstructGPT或下面的論文列表。
- Asynchronous Methods for Deep Reinforcement Learning (2016) ,https://arxiv.org/abs/1602.01783
- Proximal Policy Optimization Algorithms (2017),https://arxiv.org/abs/1707.06347
- Fine-Tuning Language Models from Human Preferences (2020),https://arxiv.org/abs/1909.08593
- Learning to Summarize from Human Feedback (2022) ,https://arxiv.org/abs/2009.01325
Llama 2中的RLHF
Meta AI在創建Llama-2-chat模型時也使用了RLHF技術,不過與ChatGPT相比還是有些細微區別。
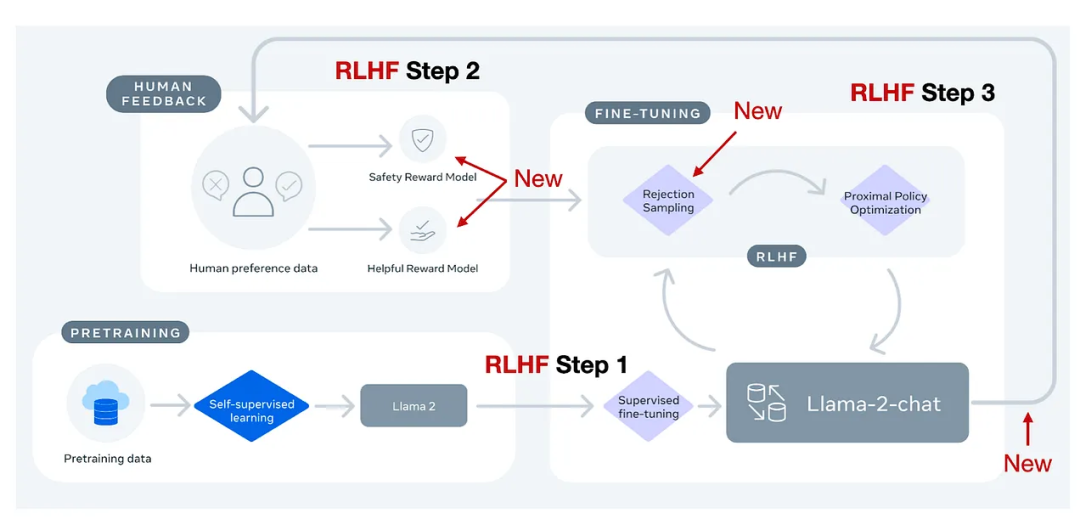
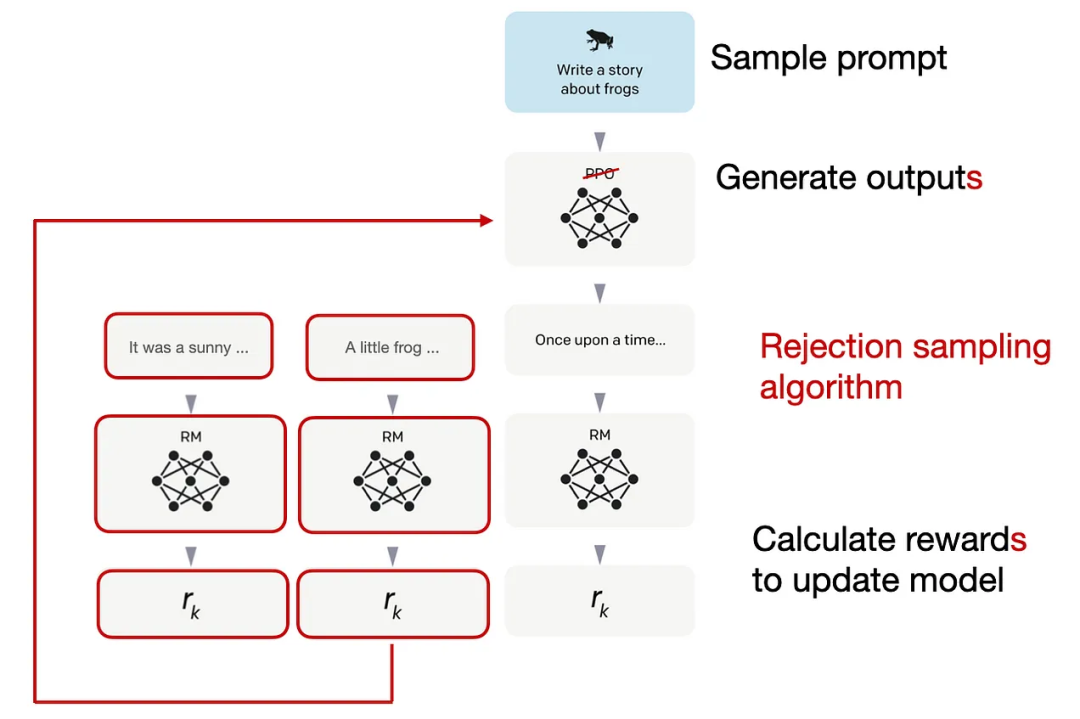
簡單來說,Llama-2-chat在第一步RLHF微調上使用相同的指令數據,但在第二步使用了兩個獎勵模型;通過多個階段的不斷進化,獎勵模型也會根據Llama-2-chat模型出現的錯誤進行更新;并且增加了拒絕采樣(rejection sampling)步驟。
Margin Loss
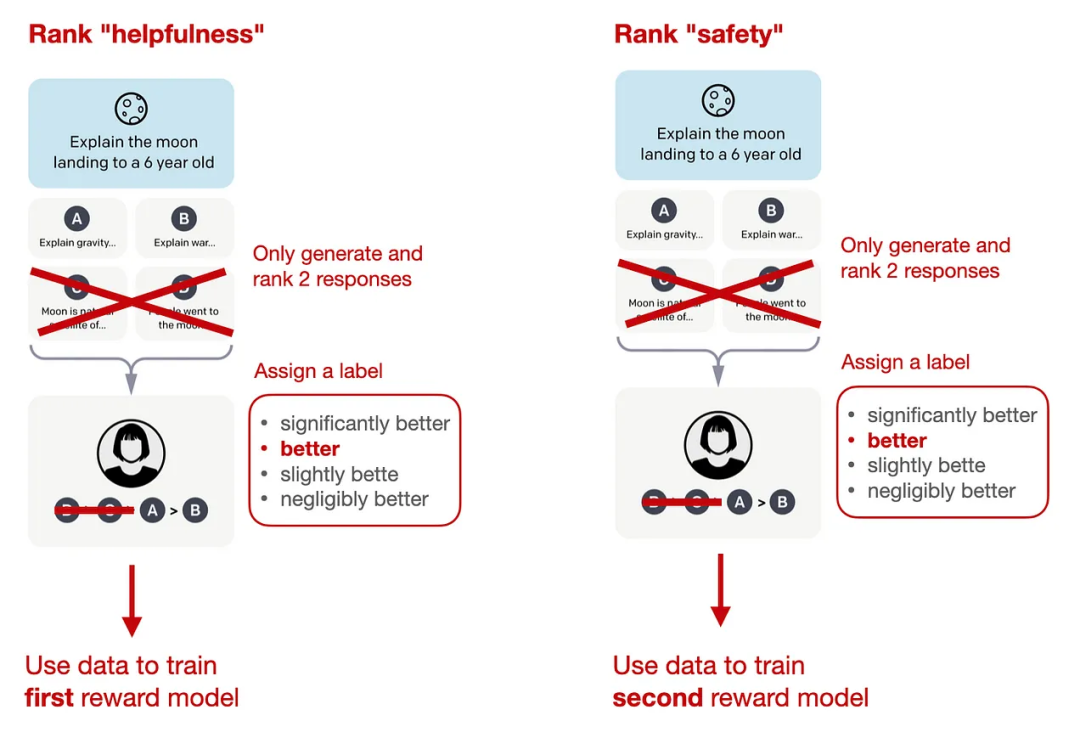
在標準InstructGPT中使用的RLHF PPO方法,研究人員需要收集同一個提示下的4-9個模型輸出并進行排序,比如四個回復的排序結果為A<C< D<B,那么就可以得到六個對比結果:A < C,A < D ,A < B,C < D,C < B,D < B
Llama 2的數據集也采用類似的方式,不過標注人員每次只能看到兩個(而非4-9個)回復并進行對比,但新增了一個邊際(margin)標簽,對比結果可以為「顯著更好」(significantly better)和「好的不明顯」(negligibly better)。
在排序訓練時中,Llama 2相比InstructGPT增加了邊際損失:
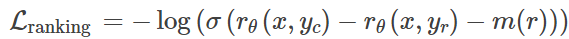
其中,rθ(x,y)是提示x和生成的回復y的標量分數輸出; θ為模型權重; σ是將層輸出轉換為范圍從0到1的分數的邏輯S形函數; yc是由標注人員選擇的更優回復; yr是較差的回復。
m(r)可以調節兩個回復之間的差值,如果對比結果為「顯著更好」,則會增加梯度值,加快更新速度。
兩種獎勵模式
Llama 2中的兩個獎勵模型分別側重「有用性」(helpfulness)和「安全性」(safety),用于模型優化的最終獎勵函數會將兩個分數進行線性組合。
拒絕采樣(Rejection sampling)
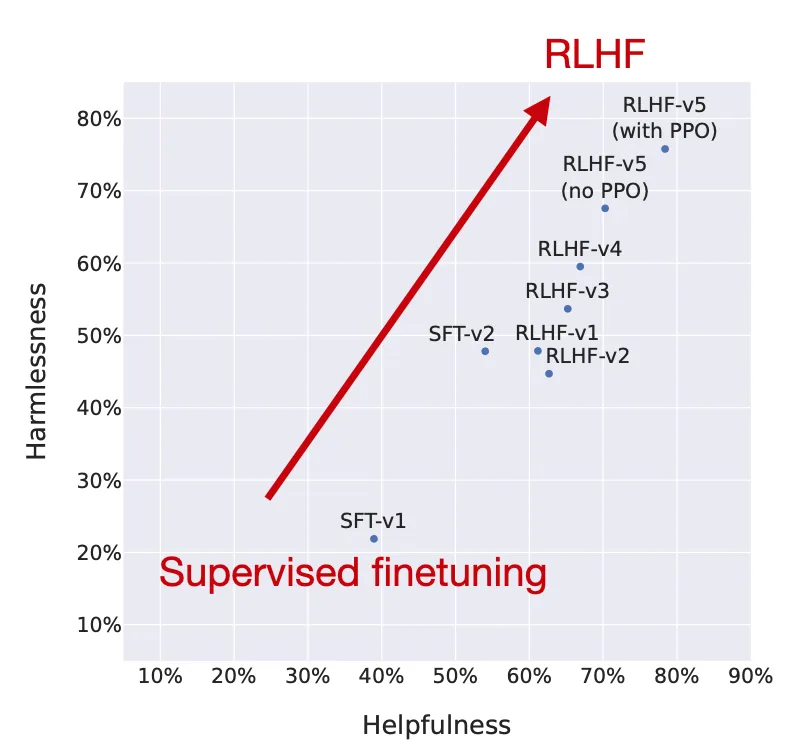
Llama 2的作者使用了一個訓練流水線,同時使用PPO和拒絕采樣算法,迭代地產生多個RLHF模型(從RLHF-V1到RLHF-V5),模型在拒絕采樣時會得到K個輸出,在每次優化迭代時選擇具有最高獎勵的輸出用于梯度更新,而PPO每次只基于單樣本進行更新。
從實驗結果來看,RLHF微調模型在無害性和有用性上都得到了改善,并且在最后階段RLHF-v5使用PPO算法的性能最好。
RLHF的替代方案
可以看到,RLHF是一個相當復雜的過程,如此精心的設計是否值得?
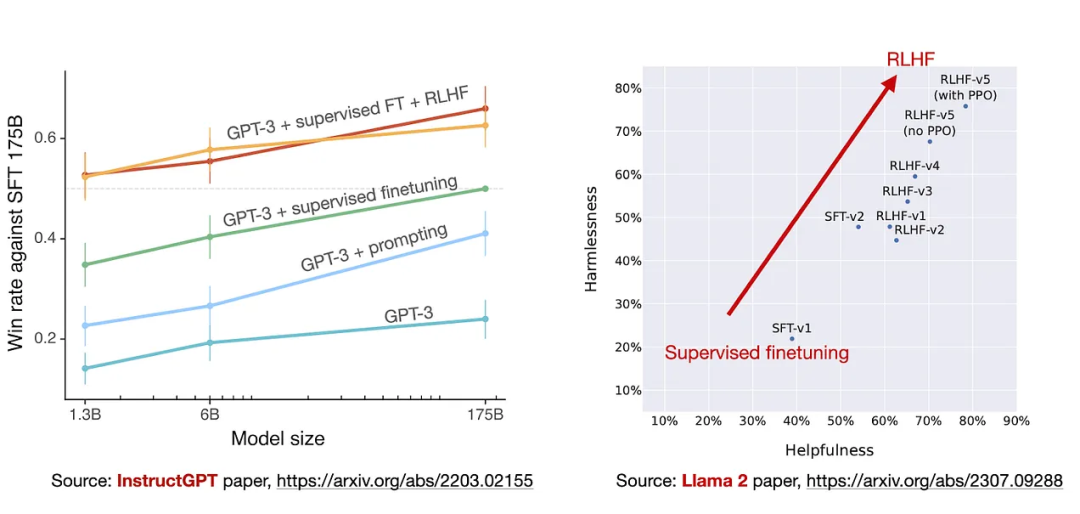
雖然InstructGPT和Llama 2論文實驗結果中證實了RLHF帶來的性能提升,但也有相關工作在關注開發更有效的替代品:
1. 憲政AI:人工智能反饋的無害性
研究人員提出了一種基于人類提供的規則列表的自我訓練機制,也使用了強化學習的方法。
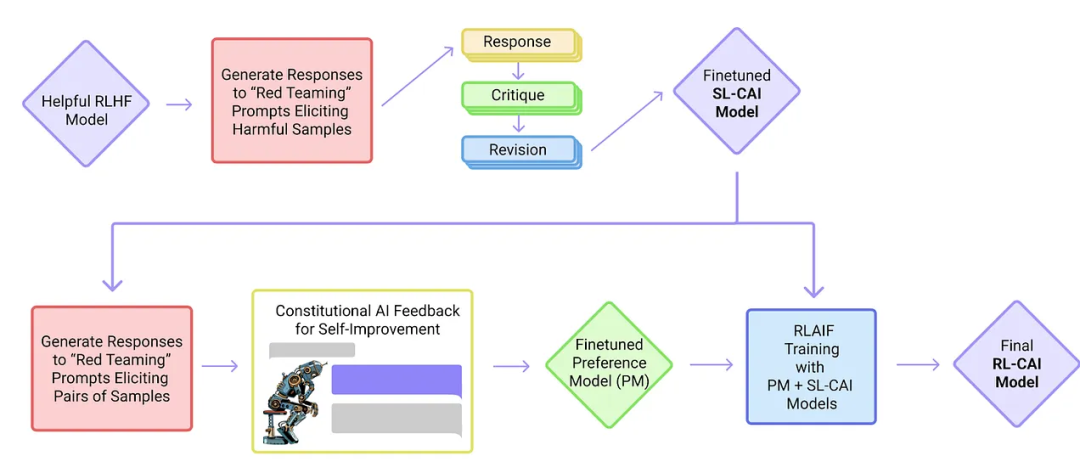
論文標題:Constitutional AI: Harmlessness from AI Feedback
論文鏈接:https://arxiv.org/abs/2212.08073
發表日期:2022年12月
上圖中的「紅隊」(Red Team)指的是測試目標系統的防御能力,即外部或內部專家模擬潛在對手的過程,通過模仿現實世界打擊者的戰術、技術和程序來挑戰、測試并最終改進系統。
2. 后見之明的智慧
研究人員提出了一種基于重新標注的有監督方法HIR用于微調,在12個BigBench任務上都優于RLHF算法。

論文標題:The Wisdom of Hindsight Makes Language Models Better Instruction Followers
論文鏈接:https://arxiv.org/abs/2302.05206
發表時間:2023年2月
HIR方法包括兩個步驟,采樣和訓練:在采樣時,提示和指令被饋送到LLM以收集回復,并基于對齊分數,在訓練階段適當的地方重新標注指令;然后使用新指令和原始提示用于微調LLM。
重新標注可以有效地將失敗案例(LLM創建的輸出與原始指令不匹配的情況)轉化為有用的訓練數據以用于監督學習。
3. 直接偏好優化
直接偏好優化(DPO)是使用PPO的RLHF的替代方案,實驗結果顯示,用于擬合RLHF中的獎勵模型的交叉熵損失可以直接用于微調LLM,并且DPO更有效,在回復生成質量方面通常也優于RLHF/PPO

論文標題:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
論文鏈接:https://arxiv.org/abs/2305.18290
發表日期:2023年5月
4. 強化自訓練(ReST)
ReST是RLHF的替代方案,可以將LLM與人類偏好對齊,其使用采樣方法來創建一個改進的數據集,在質量越來越高的子集上迭代訓練,以完善其獎勵函數。
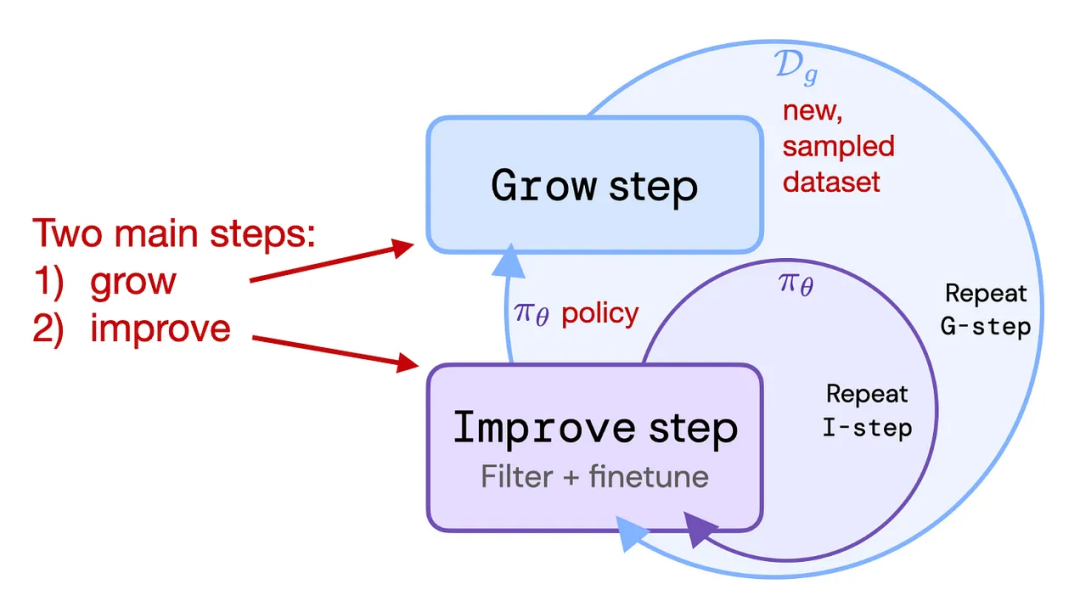
論文標題:Reinforced Self-Training (ReST) for Language Modeling
論文鏈接:https://arxiv.org/abs/2308.08998
發表日期:2023年8月
根據作者的說法,ReST通過離線生成其訓練數據集,與標準在線RLHF方法(PPO)相比,實現了更高的效率,但缺少與InstructGPT或Llama 2中使用的標準RLHF PPO方法的全面比較。
5. 基于人工智能反饋的強化學習
基于人工智能反饋的強化學習(RLAIF)的研究表明,RLHF中獎勵模型訓練的評級不一定必須由人類提供,也可以由LLM生成(如PaLM 2)。

論文標題:RLAIF:Scaling Reinforcement Learning from Human Feedback with AI Feedback
論文鏈接:https://arxiv.org/abs/2309.00267
發表日期:2023年9月
標注人員在一半的案例中更喜歡RLAIF模型,也就意味著兩個模型的差距并不大,并且RLHF和RLAIF都大大優于純粹通過監督指令微調訓練的模型。
這項研究的結果是非常有用的,基本上意味著我們可以更容易獲得RLHF的訓練數據,不過RLAIF模型如何在定性研究中表現還有待觀察,這項研究側重于信息內容的安全性和真實性,只是對人類偏好研究的部分捕獲。
但這些替代方案在實踐中是否有價值還有待觀察,因為目前還沒有哪個模型可以不用RLHF的情況下,取得與Llama 2和Code Llama相近的性能。