24小時內、200美元復制RLHF過程,斯坦福開源「羊駝農場」
2 月底,Meta 開源了一個大模型系列 LLaMA(直譯為羊駝),參數量從 70 億到 650 億不等,被稱為 Meta 版 ChatGPT 的雛形。之后斯坦福大學、加州大學伯克利分校等機構紛紛在 LLaMA 的基礎上進行「二創」,陸續推出了 Alpaca、Vicuna 等多個開源大模型,一時間「羊駝」成為 AI 圈頂流。開源社區構建的這些類 ChatGPT 模型迭代速度非常快,并且可定制性很強,被稱為 ChatGPT 的開源平替。
然而,ChatGPT 之所以能在文本理解、生成、推理等方面展現出強大的能力,是因為 OpenAI 為 ChatGPT 等大模型使用了新的訓練范式 ——RLHF (Reinforcement Learning from Human Feedback) ,即以強化學習的方式依據人類反饋優化語言模型。使用 RLHF 方法,大型語言模型可與人類偏好保持對齊,遵循人類意圖,最小化無益、失真或偏見的輸出。但 RLHF 方法依賴于大量的人工標注和評估,通常需要數周時間、花費數千美元收集人類反饋,成本高昂。
現在,推出開源模型 Alpaca 的斯坦福大學又提出了一種模擬器 ——AlpacaFarm(直譯為羊駝農場)。AlpacaFarm 能在 24 小時內僅用約 200 美元復制 RLHF 過程,讓開源模型迅速改善人類評估結果,堪稱 RLHF 的平替。

AlpacaFarm 試圖快速、低成本地開發從人類反饋中學習的方法。為了做到這一點,斯坦福的研究團隊首先確定了研究 RLHF 方法的三個主要困難:人類偏好數據的高成本、缺乏可信賴的評估、缺乏參考實現。
為了解決這三個問題,AlpacaFarm 構建了模擬注釋器、自動評估和 SOTA 方法的具體實現。目前,AlpacaFarm 項目代碼已開源。

- GitHub 地址:https://github.com/tatsu-lab/alpaca_farm
- 論文地址:https://tatsu-lab.github.io/alpaca_farm_paper.pdf
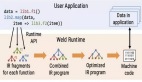
如下圖所示,研究人員可以使用 AlpacaFarm 模擬器快速開發從人類反饋數據中學習的新方法,也能將已有 SOTA 方法遷移到實際的人類偏好數據上。

模擬注釋器
AlpacaFarm 基于 Alpaca 數據集的 52k 指令構建,其中 10k 指令用于微調基本的指令遵循模型,剩余的 42k 指令用于學習人類偏好和評估,并且大部分用于從模擬注釋器中學習。該研究針對 RLHF 方法的注釋成本、評估和驗證實現三大挑戰,逐一提出解決方法。
首先,為了減少注釋成本,該研究為可訪問 API 的 LLM(如 GPT-4、ChatGPT)創建了 prompt,使得 AlpacaFarm 能夠模擬人類反饋,成本僅為 RLHF 方法收集數據的 1/45。該研究設計了一種隨機的、有噪聲的注釋方案,使用 13 種不同的 prompt,從多個 LLM 提取出不同的人類偏好。這種注釋方案旨在捕獲人類反饋的不同方面,如質量判斷、注釋器之間的變化性和風格偏好。
該研究通過實驗表明 AlpacaFarm 的模擬是準確的。當研究團隊使用 AlpacaFarm 訓練和開發方法時,這些方法與使用實際人類反饋訓練和開發的相同方法排名非常一致。下圖顯示了由 AlpacaFarm 模擬工作流和人類反饋工作流產生的方法在排名上的高度相關性。這一特性至關重要,因為它說明從模擬中得出的實驗結論在實際情況下也有可能成立。
除了方法層面的相關性,AlpacaFarm 模擬器還可以復制獎勵模型過度優化等定性現象,但以此針對代理獎勵(surrogate reward)的持續 RLHF 訓練可能會損害模型性能。下圖是在人類反饋 (左) 和 AlpacaFarm (右) 兩種情況下的該現象,我們可以發現 AlpacaFarm 最初捕獲了模型性能提升的正確定性行為,然后隨著 RLHF 訓練的持續,模型性能下降。

評估
在評估方面,研究團隊使用與 Alpaca 7B 的實時用戶交互作為指導,并通過結合幾個現有公共數據集來模擬指令分布,包括 self-instruct 數據集、anthropic helpfulness 數據集和 Open Assistant、Koala 和 Vicuna 的評估集。使用這些評估指令,該研究比較了 RLHF 模型與 Davinci003 模型的響應(response)情況,并使用一個分值度量 RLHF 模型響應更優的次數,并將這個分值稱為勝率(win-rate)。如下圖所示,在該研究的評估數據上進行的系統排名量化評估表明:系統排名和實時用戶指令是高度相關的。這一結果說明,聚合現有的公開數據能實現與簡單真實指令相近的性能。

參考方法
對于第三個挑戰 —— 缺少參考實現,研究團隊實現并測試了幾種流行的學習算法 (如 PPO、專家迭代、best-of-n 采樣)。研究團隊發現在其他領域有效的更簡單方法并不比該研究最初的 SFT 模型更好,這表明在真實的指令遵循環境中測試這些算法是非常重要的。

根據人工評估,PPO 算法被證明是最有效的,它將模型與 Davinci003 相比的勝率從 44% 提高到 55%,甚至超過了 ChatGPT。
這些結果表明,PPO 算法在為模型優化勝率方面是非常有效的。需要注意的是,這些結果是特定于該研究的評估數據和注釋器得出的。雖然該研究的評估指令代表了實時用戶指令,但它們可能無法涵蓋更具有挑戰性的問題,并且并不能確定有多少勝率的改進來源于利用風格偏好,而不是事實性或正確性。例如,該研究發現 PPO 模型產生的輸出要長得多,并且通常為答案提供更詳細的解釋,如下圖所示:


總的來說,使用 AlpacaFarm 在模擬偏好上訓練模型能夠大幅改善模型的人類評估結果,而不需要讓模型在人類偏好上重新訓練。雖然這種遷移過程比較脆弱,并且在效果上仍略遜于在人類偏好數據上重新訓練模型。但能在 24 小時內,僅用 200 美元就復制出 RLHF 的 pipeline,讓模型迅速提升人類評估性能,AlpacaFarm 這個模擬器還是太香了,是開源社區為復刻 ChatGPT 等模型的強大功能做出的又一努力。