













RLHF vs RL「AI」F,谷歌實證:大模型訓練中人類反饋可被AI替代
根據人類反饋的強化學習(RLHF)是一種對齊語言模型與人類偏好的有效技術,而且其被認為是 ChatGPT 和 Bard 等現代對話語言模型的成功的關鍵驅動因素之一。通過使用強化學習(RL)進行訓練,語言模型可以優化用于復雜的序列級目標 —— 使用傳統的監督式微調時,這些目標不是輕易可微的。
在擴展 RLHF 方面,對高質量人類標簽的需求是一大障礙;而且人們很自然地會問:生成的標簽是否也能得到可媲美的結果?
一些研究表明大型語言模型(LLM)能與人類判斷高度對齊 —— 在某些任務上甚至優于人類。
2022 年,Bai et al. 的論文《Constitutional AI: Harmlessness from AI Feedback》最早提出使用 AI 偏好來訓練用于強化學習微調的獎勵模型,該技術被稱為根據人工智能反饋的強化學習(RLAIF)。這項研究表明,通過混合使用人類與 AI 偏好,并組合 Constitutional AI 自我修正技術,可讓 LLM 的表現超越使用監督式微調的方法。不過他們的研究并未直接對比使用人類反饋和 AI 反饋時的效果,于是能否使用 RLAIF 適當地替代 RLHF 就仍舊是一個有待解答的問題。
Google Research 決定填補這一空白,憑借強大的實驗資源,他們直接比較了 RLAIF 和 RLHF 方法在摘要任務上的表現。

論文:https://arxiv.org/pdf/2309.00267.pdf
給定一段文本和兩個候選響應,研究者使用現有的 LLM 為其分配一個偏好標簽。然后再基于該 LLM 偏好,使用對比損失訓練一個獎勵模型(RM)。最后,他們使用該 RM 來提供獎勵,通過強化學習方法微調得到一個策略模型。
結果表明,RLAIF 能與 RLHF 媲美,這體現在兩個方面:

一、谷歌觀察到,RLAIF 和 RLHF 策略分別在 71% 和 73% 的時間里比監督式微調(SFT)基準更受人類青睞,而這兩個勝率在統計學意義上沒有顯著差別。
二、當被要求直接比較 RLAIF 與 RLHF 的結果時,人類對兩者的偏好大致相同(即 50% 勝率)。這些結果表明 RLAIF 可以替代 RLHF,其不依賴于人類標注,并且具有良好的擴展性。
此外,該團隊還研究了能盡可能使 AI 生成的偏好與人類偏好對齊的技術。他們發現,通過 prompt 為 LLM 提供詳細的指示并借助思維鏈推理能提升對齊效果。
他們觀察到了出乎意料的現象:少樣本上下文學習和自我一致性(采樣多個思維鏈原理并對最終偏好進行平均的過程)都不能提升準確度,甚至會導致準確度下降。
他們還進行了縮放實驗,以量化打標簽 LLM 的大小與偏好示例數量之間的權衡。
這項研究的主要貢獻包括:
- 基于摘要任務表明 RLAIF 能取得與 RLHF 相當的表現。
- 比較了多種用于生成 AI 標簽的技術,并為 RLAIF 實踐者確定了最優設置。
RLAIF 方法
這一節將描述使用 LLM 生成偏好標簽的技術、執行強化學習的方法以及評估指標。

使用 LLM 標記偏好
谷歌在實驗中的做法是使用一個現成可用的 LLM 來在成對的候選項中標記偏好。給定一段文本和兩個候選摘要,LLM 的任務是評判哪個摘要更好。LLM 的輸入的結構如下(表 1 給出了一個示例):

- 序言 —— 描述當前任務的介紹和指示
- 少樣本示例(可選)—— 一段示例文本、兩個摘要、一個思維鏈原理(如果可用)和一個偏好判斷
- 所要標注的樣本 —— 一段文本和一對要標記的摘要
- 結尾 —— 一段用于提示 LLM 的結束字符串(如 Preferred Summary=)
通過為 LLM 提供輸入而得到的偏好結果 1 和 2,可以得到生成 1 和 2 的對數概率,然后計算 softmax,得到偏好分布。
從 LLM 獲取偏好標簽的方法有很多,比如從模型中解碼自由形式的響應并以啟發式方法提取偏好(比如輸出 =「第一個偏好更好」)或將偏好分布表示成一個單樣本表征。但是,谷歌這個團隊并未實驗這些方法,因為他們的方法已能得到較高的準確度。
對于序言,研究者實驗了兩種類型:
- 基本型:就是簡單地問:「哪個摘要更好?」
- OpenAI 型:模仿了給人類偏好標注者的評級指令,該指令生成了 OpenAI TL;DR 偏好數據集并且包含有關組成優良摘要的內容的詳細信息。完整序言見下表。

研究者還實驗了上下文學習,即在 prompt 中添加少樣本示例,其中的示例是人工選取的以覆蓋不同的主題。
解決位置偏見
眾所周知,LLM 有位置偏見,也就是候選項在輸入中的位置會影響 LLM 給出的評估結果。
為了緩解偏好標注中的位置偏見,這個研究團隊采用的做法是為每一對候選項做兩次推理 —— 兩次中候選項在輸入中的位置相互調換。然后再對兩次推理的結果做平均,得到最終的偏好分布。
思維鏈推理
他們也使用了思維鏈(CoT)推理來提升與人類偏好的對齊程度。為此,他們將結尾的標準 prompt 替換成了「Consider the coherence, accuracy, coverage, and overall quality of each summary and explain which one is better. Rationale:」然后解碼 LLM 給出的響應。最后,再將原始 prompt、響應和原始結尾字符串「Preferred Summary=」連接到一起,按照前述的評分流程得到一個偏好分布。圖 3 給出了圖示說明。
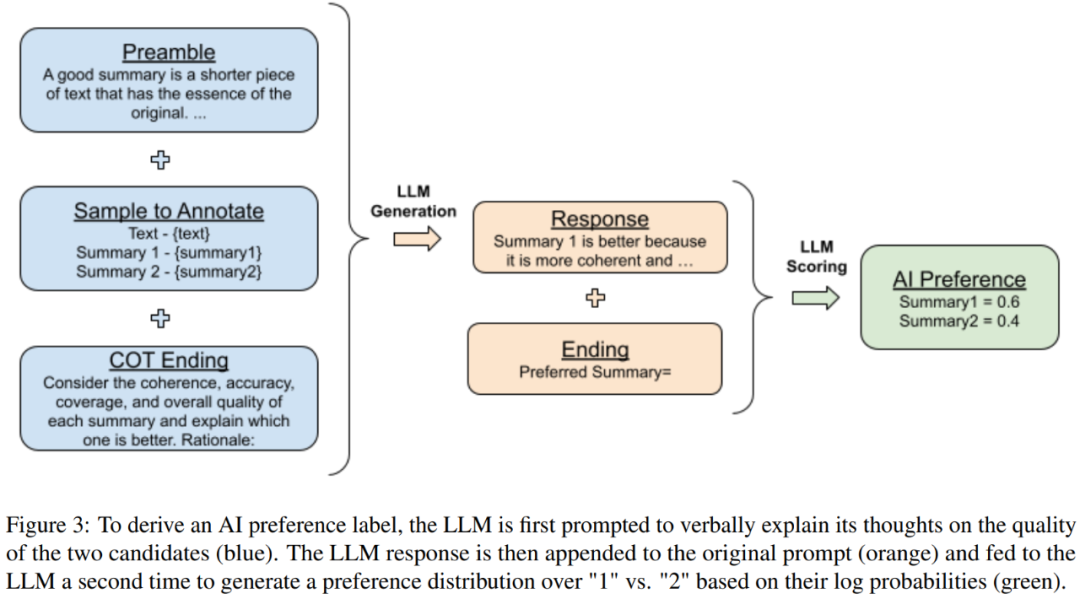
自我一致性
對于思維鏈 prompt,研究者也實驗了自我一致性 —— 這項技術是通過采樣多個推理路徑并聚合每個路徑末尾產生的最終答案來改進思維鏈推理。研究者使用非零解碼溫度對多個思想鏈原理進行采樣,然后得到每個思維鏈的 LLM 偏好分布。然后對結果進行平均,以得到最終的偏好分布。
根據人工智能反饋的強化學習
使用 LLM 標記好偏好之后,就可以用這些數據來訓練一個預測偏好的獎勵模型(RM)。由于這里的方法是得到軟標簽(如 preferences_i = [0.6, 0.4] ),因此他們對 RM 生成的獎勵分數的 softmax 使用了交叉熵損失。softmax 會將 RM 的下限分數轉換成一個概率分布。
在 AI 標簽數據集上訓練 RM 可以被視為一種模型蒸餾,尤其是因為打標簽的 AI 往往比 RM 強大得多。另一種方法是不用 RM,而是直接把 AI 反饋用作強化學習的獎勵信號,不過這種方法計算成本要高得多,因為打標簽的 AI 比 RM 大。
使用訓練得到的 RM 就能執行強化學習了,這里研究者使用了一種針對語言建模領域修改過的 Advantage Actor Critic (A2C) 算法。
評估
這項研究使用了三個評估指標:打標簽 AI 對齊度、配對準確度和勝率。
打標簽 AI 對齊度衡量的是 AI 標注的偏好與人類偏好對齊的程度。對于各個示例,其計算方式是將軟性的 AI 標記的偏好轉換成二元表征(如 preferences_i = [0.6, 0.4] → [1, 0]);如果 AI 給出的標簽與目標人類偏好一致,則分配 1,否則分配 0。其可以表示為:

其中 p_ai 和 p_h 分別是 AI 和人類偏好的二元表征,x 是索引,D 是數據集。
配對準確度衡量的是訓練好的獎勵模型相對于一個保留的人類偏好集的準確度如何。給定共享的上下文和一對候選響應,如果 RM 給人類偏好的候選項的分數高于人類不偏好的候選項,那么配對準確度為 1。否則其值為 0。將多個示例的該值平均之后,可以衡量 RM 的總準確度。
勝率則是通過人類更喜歡兩個策略中哪個策略來端到端地評估策略的質量。給定一個輸入和兩個生成結果,讓人類標注者標記自己更喜歡的那一個。在所有實例中,相比于來自策略 B 的結果,人類標注者更偏好來自策略 A 的結果的百分比稱為「A 對 B 的勝率」。
實驗
結果表明 RLAIF 與 RLHF 的表現相當,如圖 1 所示。相比于基礎 SFT 策略,人類標注者在 71% 的情況下都更偏愛 RLAIF。
研究者實驗了三種類型的 prompt 設計方案 —— 序言具體指定、思維鏈推理、和少樣本上下文學習,結果見表 2。

總體而言,研究者觀察到,最優配置為:采用詳細的序言、思維鏈推理、不采用上下文學習(OpenAI + COT 0-shot)。這一組合的打標簽 AI 對齊度為 78.0%,比使用最基礎的 prompt 時高 1.9%。
在自我一致性方面,研究者實驗了 4 和 16 個樣本的情況,而解碼溫度設置為 1。

結果發現,相比于不使用自我一致性,這兩種情況下對齊度都下降了 5% 以上。研究者以人工方式檢查了思維鏈原理,但未能揭示出自我一致性導致準確度更低的常見模式。
他們也實驗了不同模型大小的標注偏好,并觀察到對齊度與模型大小之間存在緊密關聯。

研究者也通過實驗觀察了獎勵模型(RM)準確度隨訓練樣本數量的變化模式。結果如圖 5 所示。

定性分析
為了更好地理解 RLAIF 和 RLHF 孰優孰劣,研究者讓人類評估了這兩個策略生成的摘要。很多時候,這兩個策略得到的摘要很相近,這也反映在它們相近的勝率上。但是,研究者也找到了兩種它們會出現差異的模式。
其中一個模式是 RLAIF 似乎比 RLHF 更不容易出現幻覺。RLHF 中的幻覺往往看似合理,但又與原文本不一致。

另一個模式是:相比于 RLHF,RLAIF 有時候會生成更不連貫和更不符合語法的摘要。
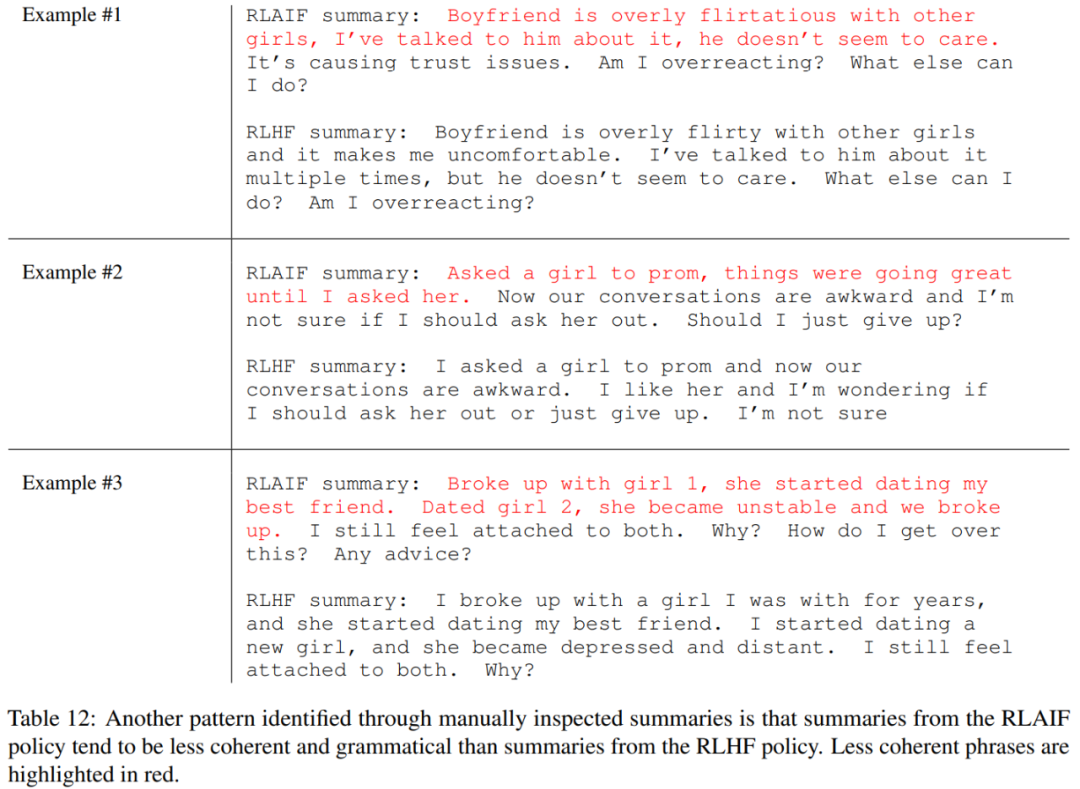
總體而言,盡管這兩個策略各自有一定的傾向性,但卻能產生相當接近的高質量摘要。




























