













GPT-4太燒錢,微軟想甩掉OpenAI?曝出Plan B:千塊GPU專訓(xùn)「小模型」,開(kāi)啟必應(yīng)內(nèi)測(cè)
GPT-4太吃算力,連微軟也頂不住了!
今年,無(wú)數(shù)場(chǎng)微軟AI大會(huì)上,CEO納德拉臺(tái)前激動(dòng)地官宣,將GPT-4、DALL·E 3整合到微軟「全家桶」。
微軟全系產(chǎn)品已被OpenAI的模型重塑,愿景是讓AI成為每個(gè)人的生活伴侶。

然而在幕后,因GPT-4運(yùn)行成本太高,微軟卻悄悄地搞起了plan B。
The Information獨(dú)家爆料稱,為了擺脫對(duì)OpenAI的依賴,由Peter Lee領(lǐng)導(dǎo)的1500人研究團(tuán)隊(duì)中,一部分人轉(zhuǎn)向研發(fā)全新對(duì)話式AI。

據(jù)稱,研發(fā)的模型性能可能不如GPT-4,但參數(shù)規(guī)模小,研究成本更低,運(yùn)行速度更快。
目前,微軟已經(jīng)在必應(yīng)聊天等產(chǎn)品中,開(kāi)啟了內(nèi)測(cè)。
不僅是微軟,包括谷歌在內(nèi)的其他科技巨頭,正在另辟蹊徑,以在AI聊天軟件和芯片兩方面節(jié)省成本。
而Llama 2宣發(fā)時(shí)微軟與Meta的合作,也不啻是一種擺脫完全依靠OpenAI的手段。
這是微軟帝國(guó)繼續(xù)向前成長(zhǎng)、突破當(dāng)前局限,注定要走的路。
更「精煉」的模型,必應(yīng)先嘗鮮
今年2月,微軟正式發(fā)布新必應(yīng)(New Bing),其中結(jié)合了ChatGPT和自家的普羅米修斯(Prometheus)模型。
在GPT-4公布后,微軟緊接著宣布,GPT-4整合到必應(yīng)中,將搜索體驗(yàn)帶上了一個(gè)新臺(tái)階。
微軟搜索主管Mikhail Parakhin近日表示,Bing Chat目前在「創(chuàng)意」和「精準(zhǔn)」模式下使用的是100%的GPT-4。
而在平衡模式下(多數(shù)用戶選擇的模式),微軟用普羅米修斯模型,以及圖靈語(yǔ)言模型(Turing language models)作為補(bǔ)充。
普羅米修斯模型是技能和技術(shù)的集合體。而圖靈模型不如GPT-4強(qiáng)大,旨在識(shí)別和回答簡(jiǎn)單的問(wèn)題,并將更難的問(wèn)題傳遞給GPT-4。
微軟內(nèi)部,已經(jīng)將其手頭的2000塊GPU中的大部分,都投入到了「小模型」的訓(xùn)練當(dāng)中。當(dāng)然,這與微軟提供給OpenAI的芯片數(shù)量相比,只能說(shuō)是小巫見(jiàn)大巫了。
不過(guò),這些模型可以執(zhí)行比GPT-4更簡(jiǎn)單的任務(wù),也是微軟為破冰所作的努力。
打破OpenAI束縛
多年來(lái),微軟與OpenAI這兩家公司,保持著千絲萬(wàn)縷的聯(lián)系。
但是,隨著ChatGPT,微軟必應(yīng)等全家桶競(jìng)相推出,微軟與OpenAI也開(kāi)始秘密開(kāi)展市場(chǎng)角逐戰(zhàn)。
盡管微軟的努力仍處于早期階段,但納德拉正帶領(lǐng)微軟,為自家AI產(chǎn)品開(kāi)辟一條不完全依賴OpenAI的路。

「這終究還是要發(fā)生的」,Databricks的高管Naveen Rao在談到微軟內(nèi)部的AI工作時(shí)說(shuō)。
「微軟是一家精明的企業(yè),當(dāng)你部署產(chǎn)品使用GPT-4巨型模型時(shí),他們要的是高效。這就好比說(shuō),我們并不需要一個(gè)擁有3個(gè)博士學(xué)位的人,來(lái)當(dāng)電話接線員,這在經(jīng)濟(jì)上是行不通的。」
然而,納德拉和研究主管Peter Lee希望在沒(méi)有OpenAI的情況下,開(kāi)發(fā)出復(fù)雜的AI,這大概只是一廂情愿。
自從微軟投資OpenAI后,這家巨頭的研究部門把大部分時(shí)間,都用來(lái)調(diào)整OpenAI的模型,以便使其適用微軟的產(chǎn)品,而不是開(kāi)發(fā)自己的模型。
微軟的研究團(tuán)隊(duì),也并沒(méi)有幻想自己能開(kāi)發(fā)出像GPT-4這樣強(qiáng)大的AI。

他們清楚地知道,自身沒(méi)有OpenAI的計(jì)算資源,也沒(méi)有大量的人類審查員來(lái)反饋LLM回答的問(wèn)題,以便工程師改進(jìn)模型。
過(guò)去一年里,隨著幾波研究人員的離職,包括一些轉(zhuǎn)入微軟內(nèi)部的產(chǎn)品團(tuán)隊(duì),研究部門的人才也在不斷流失。
對(duì)微軟自身來(lái)說(shuō),在沒(méi)有OpenAI幫助的情況下,開(kāi)發(fā)高質(zhì)量的LLM,可以在未來(lái)幾年,兩家公司討論續(xù)簽合作關(guān)系時(shí)贏得更多談判籌碼。

微軟AI研究主管Peter Lee
目前,兩者交易對(duì)雙方都有利。
此外,微軟還將獲得OpenAI 75%的理論運(yùn)營(yíng)收益,直到其初始投資償還為止,并且將獲得利潤(rùn)的49%,直到達(dá)到一定上限為止。

現(xiàn)在,微軟希望通過(guò)與OpenAI,以及其他AI企業(yè)的現(xiàn)有聯(lián)盟,在一個(gè)不確定的時(shí)期內(nèi)增加至少100億美元的新收入。
O?ce 365全家桶在得到GPT-4能力加持,已經(jīng)出現(xiàn)了早期的收入增長(zhǎng)跡象。
微軟還在7月份表示,已有超過(guò)2.7萬(wàn)家公司為代碼編寫工具GitHub Copilot付費(fèi)了。
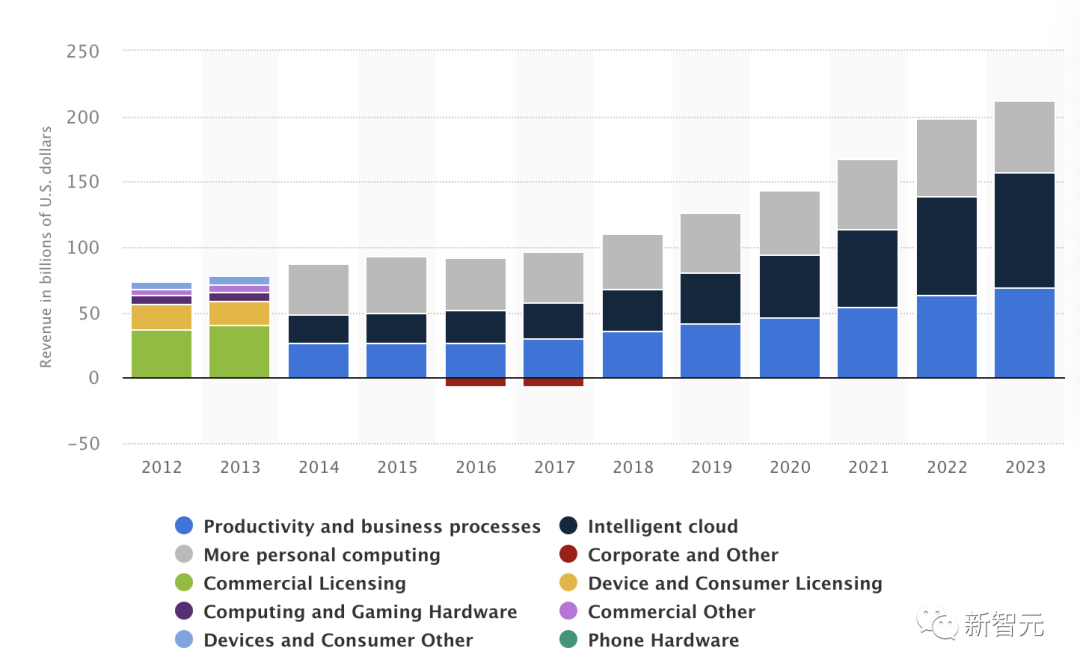
Statista統(tǒng)計(jì),2023年除了微軟云服務(wù)比例最大,加速生產(chǎn)力商業(yè)流程的軟件產(chǎn)品收入占比也在逐漸增加。
然鵝,諷刺的是,微軟與OpenAI的交易條款,也間接地幫助微軟努力擺脫對(duì)OpenAI的依賴。
當(dāng)用戶使用必應(yīng)時(shí),微軟可以訪問(wèn)OpenAI模型輸出的結(jié)果。
目前,微軟正在利用這些數(shù)據(jù),創(chuàng)建更加「精煉」的模型。內(nèi)部研究人員的研究結(jié)果表明,這些模型可以用更少的計(jì)算資源產(chǎn)生類似的結(jié)果。
「小模型」的探索
在OpenAI的陰影下度過(guò)一年后,微軟的一些研究人員找到了全新的目標(biāo)——制造一個(gè)模仿GPT-4的「蒸餾」模型。
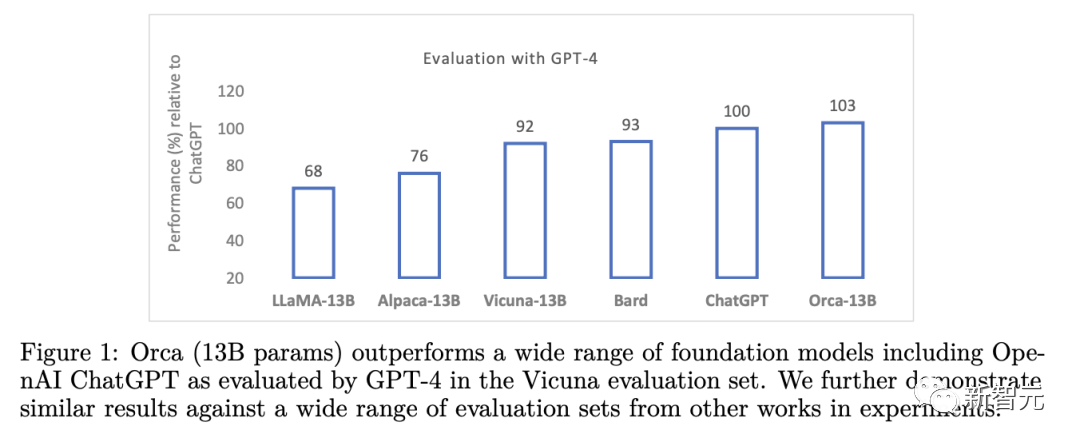
今年6月,微軟訓(xùn)練了一個(gè)算力消耗只有GPT-4十分之一的模型——Orca。
為了創(chuàng)建這個(gè)Orca,微軟將GPT-4生成的數(shù)百萬(wàn)個(gè)答案輸入到了一個(gè)更為基本的開(kāi)源模型之中,并以此教它模仿GPT-4。

論文地址:https://arxiv.org/abs/2306.02707
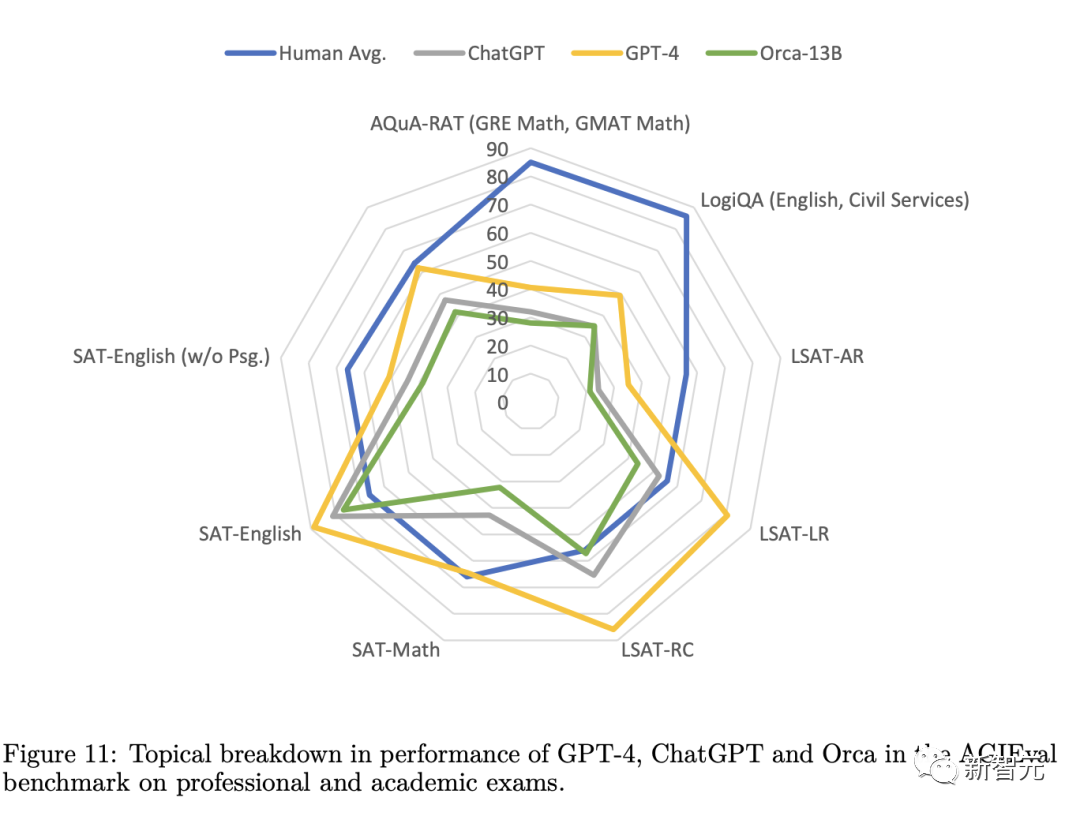
結(jié)果顯示,Orca不僅超過(guò)了其他的SOTA指令微調(diào)模型,而且在BigBench Hard(BBH)等復(fù)雜的零樣本推理基準(zhǔn)中,實(shí)現(xiàn)了比Vicuna-13B翻倍的性能表現(xiàn)。
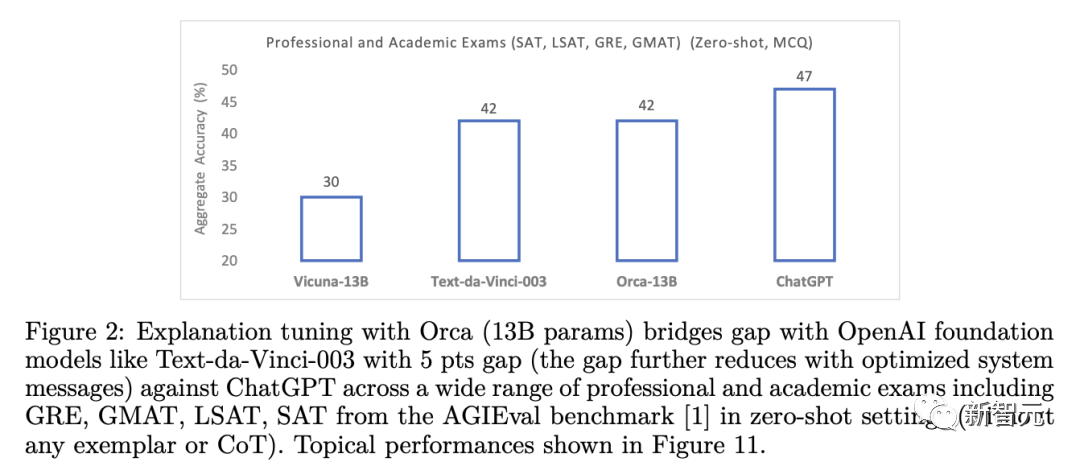
此外,Orca在BBH基準(zhǔn)上還實(shí)現(xiàn)了與ChatGPT持平的性能,在SAT、LSAT、GRE和GMAT等專業(yè)和學(xué)術(shù)考試中只有4%的性能差距,并且都是在沒(méi)有思維鏈的零樣本設(shè)置下測(cè)量的。
類似的,微軟還公布了一款參數(shù)量不到GPT-4千分之一的模型——phi-1。
由于采用了「教科書(shū)級(jí)」的高質(zhì)量訓(xùn)練數(shù)據(jù),phi-1在數(shù)學(xué)和邏輯問(wèn)題上的熟練程度,完全不亞于5倍于它的開(kāi)源模型。

論文地址:https://arxiv.org/abs/2306.11644
隨后,微軟在研究「一個(gè)LLM有多小,才能達(dá)到一定的能力」上更進(jìn)了一步,推出了只有13億參數(shù)的模型phi-1.5。

論文地址:https://arxiv.org/abs/2309.05463
phi-1.5展現(xiàn)出了許多大模型具備的能力,能夠進(jìn)行「一步一步地思考」,或者進(jìn)行一些基本上下文學(xué)習(xí)。

結(jié)果顯示,phi-1.5在常識(shí)推理和語(yǔ)言技能上的表現(xiàn),與規(guī)模10倍于它的模型旗鼓相當(dāng)。
同時(shí),在多步推理上,還遠(yuǎn)遠(yuǎn)超過(guò)了其他大模型。

雖然目前還不清楚,像Orca和Phi這樣的「小模型」是否真的能與更大的SOTA模型(如GPT-4)相媲美。但它們巨大的成本優(yōu)勢(shì),加強(qiáng)了微軟繼續(xù)推動(dòng)相關(guān)研究的動(dòng)力。
據(jù)一位知情人士透露,團(tuán)隊(duì)在發(fā)布Phi之后,首要任務(wù)就是驗(yàn)證此類模型的質(zhì)量。
在即將要發(fā)表的論文中,研究人員又提出了一種基于對(duì)比學(xué)習(xí)的方法,讓工程師們可以教模型區(qū)分高質(zhì)量和低質(zhì)量的響應(yīng),從而改進(jìn)Orca。
同時(shí),微軟其他的團(tuán)隊(duì)也正在緊鑼密鼓地開(kāi)發(fā)全新的多模態(tài)大模型,也就是一種既能解釋又能生成文本和圖像的LLM。

GPT-4V
顯然,像Orca和Phi這樣的模型,可以幫助微軟降低為客戶提供AI功能時(shí)所需的計(jì)算成本。
據(jù)一位在職員工透露,微軟的產(chǎn)品經(jīng)理已經(jīng)在測(cè)試如何使用Orca和Phi而不是OpenAI的模型,來(lái)處理必應(yīng)聊天機(jī)器人的查詢了。比如,總結(jié)小段文本、回答是或者否,這種相對(duì)簡(jiǎn)單的問(wèn)題。
此外,微軟還在權(quán)衡是否向Azure云客戶提供Orca模型。
據(jù)知情人士透露,Orca論文一經(jīng)發(fā)表,就有客戶來(lái)詢問(wèn)何時(shí)能用上了。
但問(wèn)題在于,如果真要這樣操作的話,微軟是不是還需要找Meta拿個(gè)許可。畢竟后者對(duì)哪些公司可以將其開(kāi)源LLM進(jìn)行商業(yè)化,還是有所限制的。






























