













LLM吞吐量提高2-4倍,模型越大效果越好!UC伯克利、斯坦福等開源高效內存管理機制PagedAttention
雖然大型語言模型(LLM)的性能表現足夠驚艷,但每次接收用戶請求時都需要耗費大量顯存和計算資源,一旦請求數量超出預期,就極有可能面臨ChatGPT剛發布時的宕機、排隊、高延遲等窘境。

想要打造一個高吞吐量的LLM服務,就需要模型在一個批次內處理盡可能多的請求,不過現有的系統大多在每次處理請求時申請大量的key-value(KV)緩存,如果管理效率不高,大量內存都會在碎片和冗余復制中被浪費掉,限制了batch size的增長。

最近,來自加州大學伯克利分校、斯坦福大學、加州大學圣迭戈分校的研究人員基于操作系統中經典的虛擬內存和分頁技術,提出了一個新的注意力算法PagedAttention,并打造了一個LLM服務系統vLLM

論文鏈接:https://arxiv.org/pdf/2309.06180.pdf
開源鏈接:https://github.com/vllm-project/vllm
vLLM在KV緩存上實現了幾乎零浪費,并且可以在「請求內部」和「請求之間」靈活共享KV高速緩存,進一步減少了內存的使用量。

評估結果表明,vLLM可以將常用的LLM吞吐量提高了2-4倍 ,在延遲水平上與最先進的系統(如FasterTransformer和Orca)相當,并且在更長序列、更大模型和更復雜的解碼算法時,提升更明顯。
PagedAttention
為了解決注意力機制的內存管理問題,研究人員開發了一種全新的注意力算法PagedAttention,并構建了一個LLM服務引擎vLLM,采用集中式調度器來協調分布式GPU工作線程的執行。

1. 算法
受操作系統中分頁(paging)算法啟發,PagedAttention將序列中KV緩存劃分為KV塊,其中每個塊包含固定數量tokens的鍵(K)和值(V)向量,從而將注意力計算轉換為塊級運算:
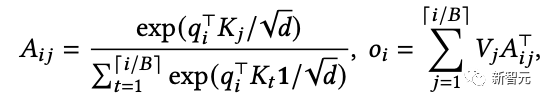
在注意力計算期間,PagedAttention內核分別識別和獲取不同的KV塊,比如下面的例子中,鍵和值向量分布在三個塊上,并且三個塊在物理內存上是不連續的,然后將查詢向量與塊中的鍵向量相乘得到部分注意力得分,再乘以塊中的值向量得到最終注意力輸出。

這種設計使得KV塊存儲在非連續物理內存中,從而讓vLLM中的分頁內存管理更加靈活。
2. KV緩存管理器
操作系統會將內存劃分為多個固定大小的頁,并將用戶程序的邏輯頁映射到物理頁,連續的邏輯頁可以對應于非連續的物理內存頁,所以用戶在訪問內存時看起來就像連續的一樣。
此外,物理內存空間不需要提前完全預留,使操作系統能夠根據需求動態分配物理頁。
通過PageAttention劃分出的KV塊,vLLM利用虛擬內存機制將KV緩存表示為一系列邏輯KV塊,并在生成新token及KV緩存時,從左到右進行填充;最后一個KV塊的未填充位置預留給后續生成操作。
KV塊管理器還負責維護塊表(block table),即每個請求的邏輯和物理KV塊之間的映射。
將邏輯和物理KV塊分離使得vLLM能夠動態地增長KV高速緩存存儲器,而無需預先將其保留給所有位置,消除了現有系統中的大多數內存浪費。
3. 解碼
從下面的例子中可以看出vLLM如何在單個輸入序列的解碼過程中執行PagedAttention并管理內存。
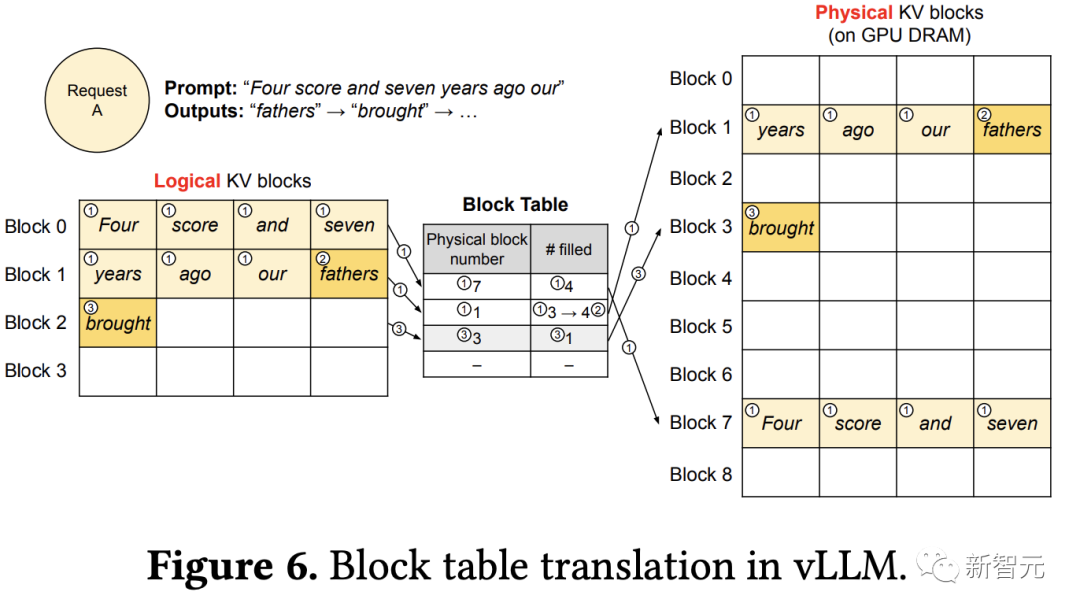
① 與操作系統的虛擬內存一樣,vLLM最初不需要為最大可能生成的序列長度保留內存,只保留必要的KV塊,以容納在即時計算期間生成的KV緩存。
提示詞中包含7個tokens,所以vLLM將前兩個邏輯KV塊(0和1)映射到2個物理KV塊(7和1);在預填充(prefill)步驟中,vLLM使用自注意算法生成提示和首個輸出token的KV緩存;然后將前4個token的KV緩存存儲在邏輯塊0中,后面3個token存儲在邏輯塊1中;剩余的slot被保留用于后續自回歸生成。
② 在首個自回歸解碼步驟中,vLLM在物理塊7和1上使用PagedAttention算法生成新token
由于最后一個邏輯塊中仍有一個slot可用,所以將新生成的KV緩存存儲在該slot,更新塊表的#filled記錄。
③ 在第二次解碼步驟中,當最后一個邏輯塊已滿時,vLLM將新生成的KV緩存存儲在新的邏輯塊中,為其分配一個新的物理塊(物理塊3),并映射存儲在塊表中。
在LLM的計算過程中,vLLM使用PagedAttention內核訪問以前以邏輯KV塊形式存儲的KV緩存,并將新生成的KV緩存保存到物理KV塊中。
在一個KV塊(塊大小>1)中存儲多個token使PagedAttention內核能夠跨更多位置并行處理KV緩存,從而提高硬件利用率并減少延遲,但較大的塊大小也會增加內存碎片。
隨著生成越來越多的token及其KV緩存,vLLM會動態地將新的物理塊分配給邏輯塊,從左到右地填充所有塊,并且只有當所有先前的塊都滿時才分配新的物理塊,即請求的所有內存浪費限制在一個塊內,可以有效地利用所有內存,從而允許更多的請求放入內存進行批處理,提高了吞吐量;一旦請求完成生成,就可以釋放其KV塊來存儲其他請求的KV緩存。
4. 通用解碼
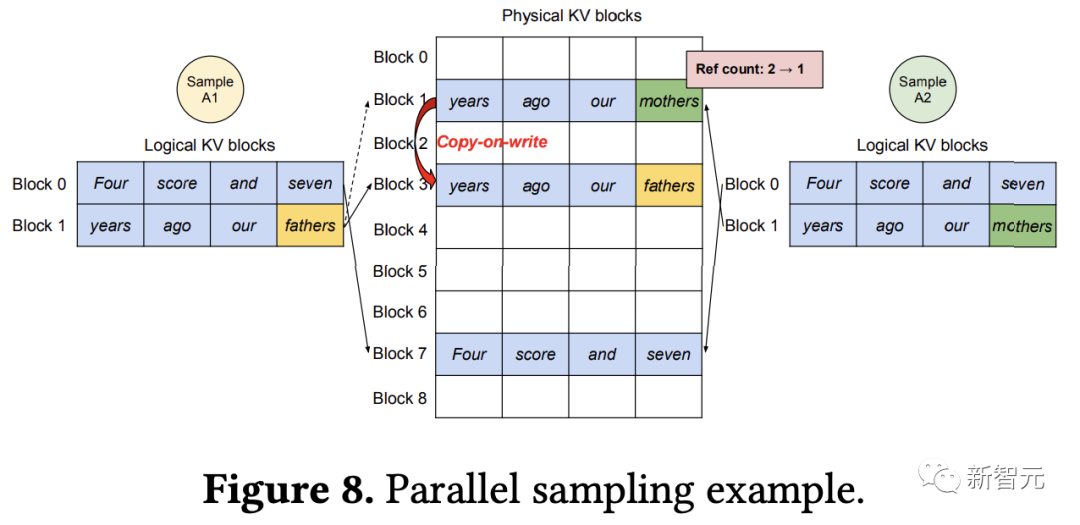
除了貪婪解碼和采樣,支持單個用戶提示輸入生成單個輸出序列等基本場景外,該算法還可以支持更復雜的解碼場景,如并行采樣(Parallel sampling)、集束搜索(Beam Search)、共享前綴等。
5. 調度和搶占(Scheduling and Preemption)
當請求流量超過系統容量時,vLLM必須對請求子集進行優先級排序,具體采用「先來先服務」(FCFS)的調度策略,可以確保公平性并防止饑餓。
不過LLM的輸入提示在長度上可能變化很大,并且輸出長度是先驗未知的,具體取決于輸入提示和模型;隨著請求及其輸出數量的增長,vLLM可能會耗盡GPU的物理塊來存儲新生成的KV緩存。
交換(Swapping)是大多數虛擬內存算法使用的經典技術,將被釋放的頁復制到磁盤上的交換空間。
除了GPU塊分配器之外,vLLM還包括CPU塊分配器,以管理交換到CPU RAM的物理塊;當vLLM耗盡新令牌的空閑物理塊時,會選擇一組序列來釋放KV緩存并將其傳輸到CPU。
在這種設計中,交換到CPU RAM的塊數永遠不會超過GPU RAM中的物理塊總數,因此CPU RAM上的交換空間受到分配給KV緩存的GPU內存的限制。
重新計算(Recomputation),當被搶占的序列被重新調度時,可以簡單地重新計算KV緩存,其延遲可以顯著低于原始延遲,因為解碼時生成的token可以與原始用戶提示連接起來作為新的提示,所有位置的KV緩存可以在一次提示階段迭代中生成。
交換和重計算的性能取決于CPU、RAM和GPU內存之間的帶寬以及GPU的計算能力。
6. 分布式執行(Distributed Execution)
vLLM支持Megatron-LM風格的張量模型并行策略,遵循SPMD(單程序多數據)執行調度,其中線性層被劃分以執行逐塊矩陣乘法,并且GPU通過allreduce操作不斷同步中間結果。
具體來說,注意算子在注意頭維度上被分割,每個SPMD過程負責多頭注意中的注意頭子集,不過每個模型分片仍然處理相同的輸入token集合,即在同一位置需要KV緩存。

不同的GPU worker共享管理器,以及從邏輯塊到物理塊的映射,使用調度程序為每個輸入請求提供的物理塊來執行模型;盡管每個GPU工作線程具有相同的物理塊id,但是一個工作線程僅為其相應的注意頭存儲KV緩存的一部分。
在每一步中,調度程序首先為批處理中的每個請求準備帶有輸入token id的消息,以及每個請求的塊表;
然后調度程序將該控制消息廣播給GPU worker,使用輸入token id執行模型;在注意力層,根據控制消息中的塊表讀取KV緩存;在執行過程中,將中間結果與all-reduce通信原語同步,而無需調度程序的協調。
最后,GPU worker將該迭代的采樣token發送回調度器。
評估結果
基礎采樣
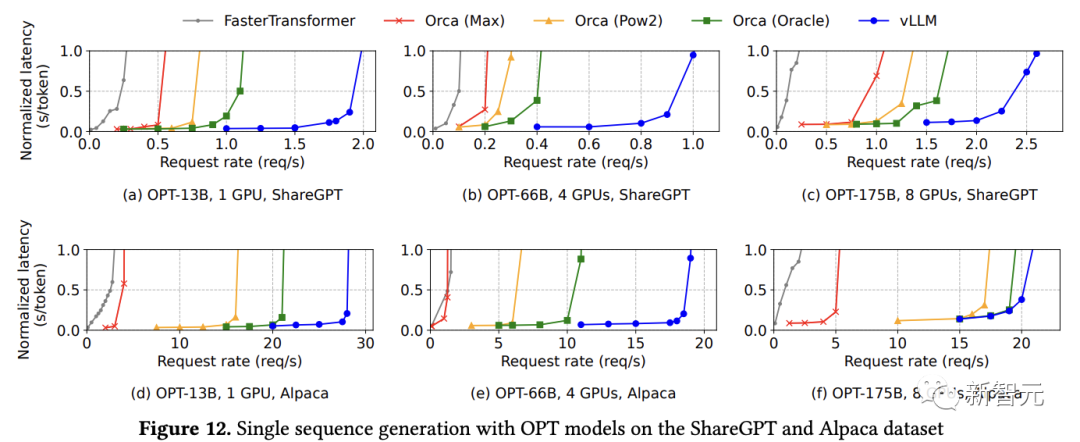
在ShareGPT數據集上,隨著請求速率的增加,延遲最初緩慢增加,之后會突然激增,可能是因為當請求速率超過服務系統的容量時,導致隊列長度無限增長。
vLLM可以承受比Orca高1.7倍-2.7倍的請求速率,比Orca(Max)高2.7倍-8倍的請求速率,同時保持相似的延遲,因為PagedAttention可以有效地管理內存使用,從而能夠比Orca在一個批次內處理更多的請求。
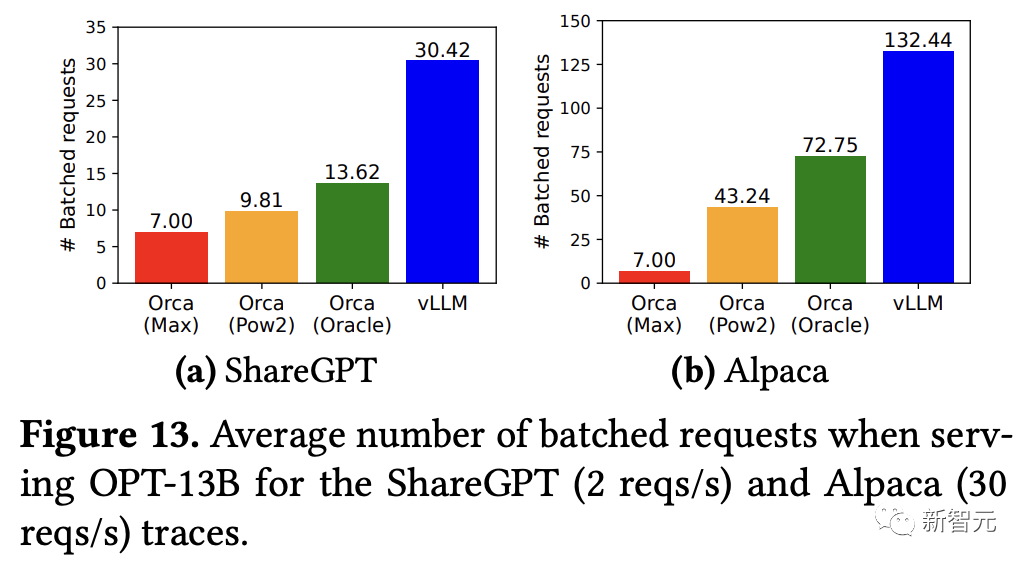
對于OPT-13B模型,vLLM同時處理的請求比Orca多2.2倍,比Orca(Max)多4.3倍。
與FasterTransformer相比,vLLM實現高達22倍的請求速率,可能是因為沒有利用細粒度的調度機制,并且與Orca(Max)一樣在內存管理方面很低效。
多序列
在并行采樣中,請求中的所有并行序列可以共享提示符的KV緩存,隨著采樣序列數量的增加,vLLM實現了比Orca基線更大的提升。
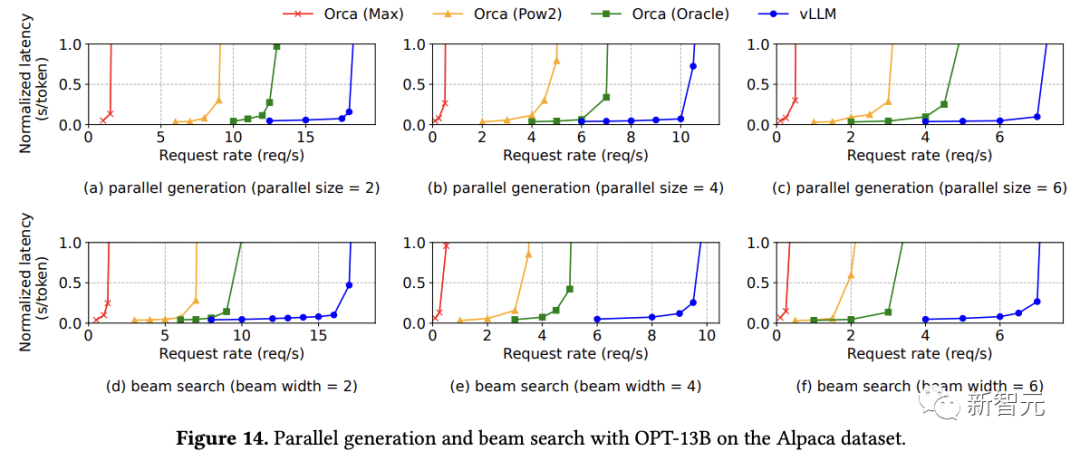
由于集束搜索中共享內容更多,vLLM展示出了更大的性能優勢。
在OPT-13B和Alpaca數據集上,vLLM相對于Orca(Oracle)的改進從基本采樣的1.3倍增加到寬度為6的集束搜索的2.3倍。
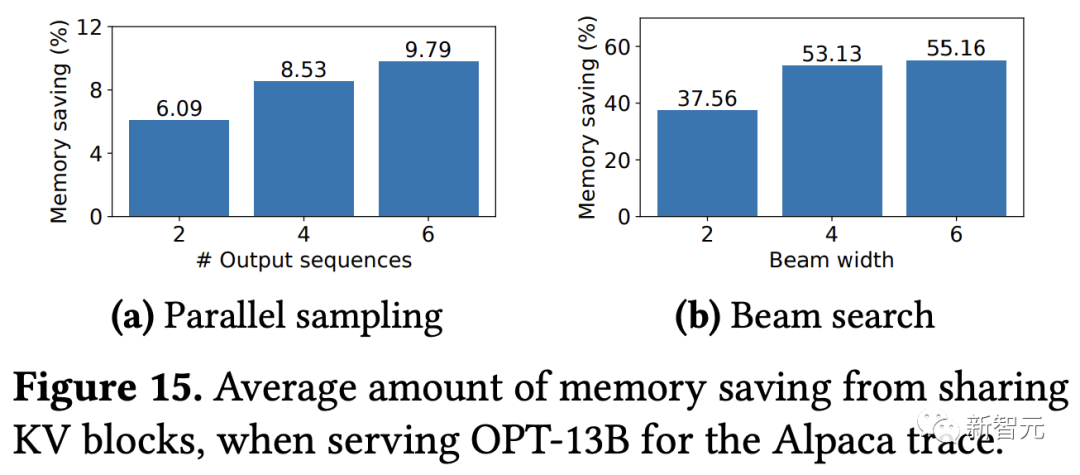
通過計算共享保存的塊數除以未共享的總塊數計算的存儲器節省量,結果顯示并行采樣節省了6.1%-9.8%的內存,集束搜索節省了37.6%-55.2%的內存。
在使用ShareGPT數據集的相同實驗中,可以看到并行采樣節省了16.2%-30.5%的內存,集束搜索節省了44.3%-66.3%的內存。






























