













將LLaMA2上下文擴展至100k,MIT、港中文有了LongLoRA方法
一般來說,大模型預訓練時文本長度是固定的,如果想要支持更長文本,就需要對模型進行微調。但是訓練具有長上下文的 LLM 計算成本很高,需要大量的訓練時間和 GPU 資源。
比如,訓練一個具有 8192 長度上下文的模型,相比于 2048 長度上下文,需要 16 倍的計算資源。就算如此,上下文長度對模型性能至關重要,因為它代表了 LLM 回應時對整個上下文清晰理解的能力。
近日,MIT 與香港中文大學聯合研究,提出了 LongLoRA。它是一種有效的微調方法,以有限的計算成本擴展了預訓練大型語言模型上下文大小。

論文地址:https://arxiv.org/pdf/2309.12307.pdf
項目地址:https://github.com/dvlab-research/LongLoRA
本文從兩個方面加快了 LLM 的上下文擴展。
一方面,盡管在推理過程中需要密集的全局注意力,但通過稀疏的局部注意力可以有效且高效地對模型進行微調。本文提出的 shift short attention 有效地實現了上下文擴展,節省了大量的計算,與使用 vanilla attention 進行微調的性能相似。
另一方面,用于上下文擴展的 LoRA 在可訓練嵌入和歸一化的前提下工作得很好。LongLoRA 在 LLaMA2 模型從 7B/13B 到 70B 的各種任務上都展現了很好的結果。在單臺 8x A100 設備上,LongLoRA 將 LLaMA2 7B 從 4k 上下文擴展到 100k, LLaMA2 70B 擴展到 32k。LongLoRA 擴展了模型的上下文,同時保留了其原始架構,并與大多數現有技術兼容,如 FlashAttention-2。為使 LongLoRA 實用,研究者收集了一個數據集 LongQA,用于監督微調。該數據集包含超過 3k 個長上下文問題 - 答案對。
LongLoRA 的能夠在注意力水平和權重水平上加速預訓練大型語言模型的上下文擴展。亮點如下:
- Shift short attention 易于實現,與 Flash-Attention 兼容,且在推理過程中不需要使用。
- 發布了所有模型,包括從 7B 到 70B 的模型,上下文長度從 8k 到 100k,包括 LLaMA2-LongLoRA-7B-100k、LLaMA2-LongLoRA-13B-64k 和 LLaMA2-LongLoRA-70B-32k。
- 建立了一個長上下文 QA 數據集 LongQA,用于監督微調。研究者已經發布了 13B 和 70B 32k 型號的 SFT、Llama-2-13b-chat-longlora-32k-sft 和 Llama-2-70b-chat-longlora-32k-sft,并將在下個月發布數據集。
LongLoRA 技術細節
Shift short attention
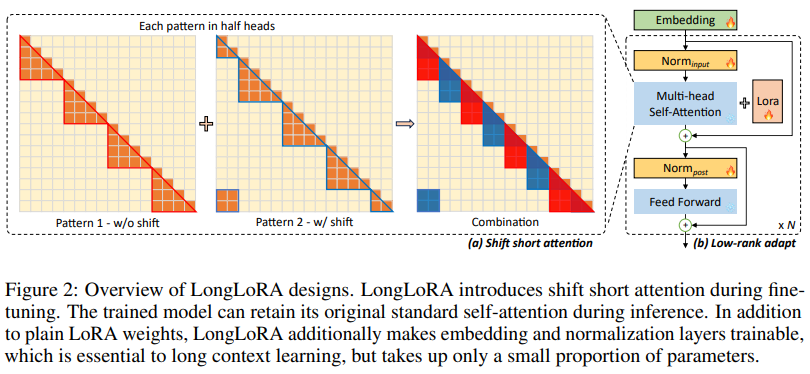
標準自注意力模式的計算開銷為 O (n^2 ),使得長序列上的 LLM 內存開銷高且速度慢。為了在訓練中避免這個問題,本文提出了 shift short attention(S^2 -Attn),如下圖 2 所示。
研究者驗證了微調的重要性,如下表 1 所示。如果沒有微調,隨著上下文長度的增長,即使配備了適當的位置嵌入,模型的表現也會變差。

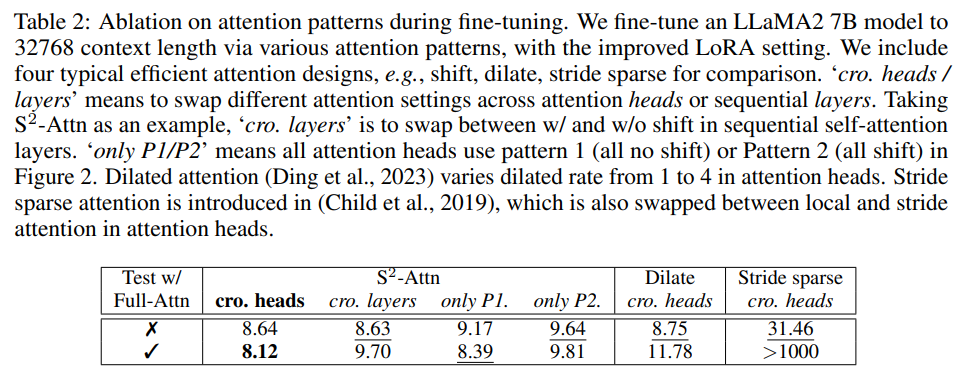
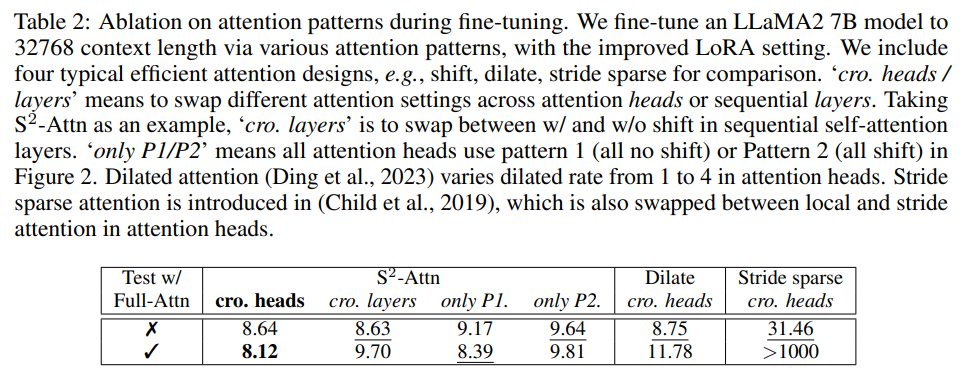
現有的 efficient attention 設計也可以提高長上下文語言模型的效率。在下表 2 中,研究者將 S^2 -Attn 與幾種典型的 efficient attention 進行了比較,可以發現,前者不僅能夠實現高效的微調,還支持 full attention 測試。
此外,S^2 -Attn 容易實現,它只涉及兩個步驟:(1) 轉換半注意力頭中的 token (2) 將 token 維度的特征移至批次維度。這個過程使用幾行代碼就夠了。
改進長上下文 LoRA
LoRA 是一種有效且流行的方法,可使 LLM 適應其他數據集。與完全微調相比,它節省了很多可訓練參數和內存成本。然而,將 LLM 從短上下文長度調整為長上下文長度并不容易。研究者觀察到 LoRA 和完全微調之間存在明顯的差距。如下表 3 所示,隨著目標上下文長度的增大,LoRA 和完全微調之間的差距也會增大。
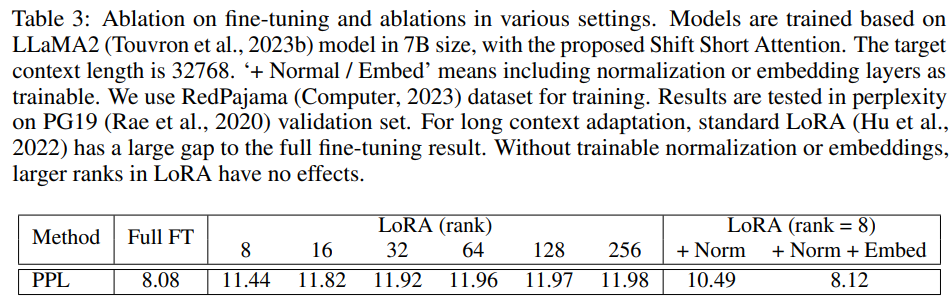
為了彌補這一差距,研究者打開嵌入層和歸一化層進行訓練。如表 3 所示,它們占用的參數有限,但對長上下文適應有影響。特別是歸一化層,在整個 LLaMA2 7B 的參數占比僅為 0.004%。在實驗中,研究者將這種改進的 LoRA 表示為 LoRA+。
實驗及結果
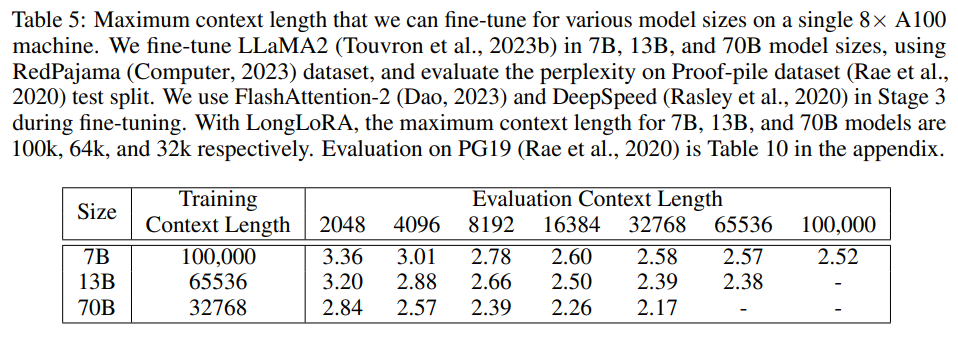
研究者擴展了預訓練的 7B、13B 和 70B LLaMA2 模型。7B 模型的最大擴展上下文窗口大小為 100k,13B 模型的最大擴展上下文窗口大小為 65536,70B 模型的最大擴展上下文窗口大小為 32768。
研究者沿用了 Position Interpolation 中的大部分訓練超參數,不過批大小更小,因為只是在某些情況下使用單臺 8×A100 GPU 設備。所有模型都通過下一個 token 預測目標進行微調。研究者使用 AdamW,其中 β_1 = 0.9,β_2 = 0.95。7B 和 13B 模型的學習率設定為 2 × 10^?5,70B 模型的學習率設定為 10^?5。
他們還使用了線性學習率預熱。權重衰減為零。每臺設備的批大小設為 1,梯度累積步驟設為 8,這意味著使用 8 個 GPU,全局批大小等于 64。模型進行了 1000 步的訓練。
研究者使用 Redpajama 數據集進行訓練,并構建了一個長上下文 QA 數據集 LongQA,用于監督微調。Redpajama 微調的模型呈現了良好的困惑度,但它們的聊天能力是有限的。研究者收集了超過 3k 個問題 - 答案對,它們都是與技術論文、科幻小說和其他書籍等材料有關的。設計的問題包括總結、關系、人物等。
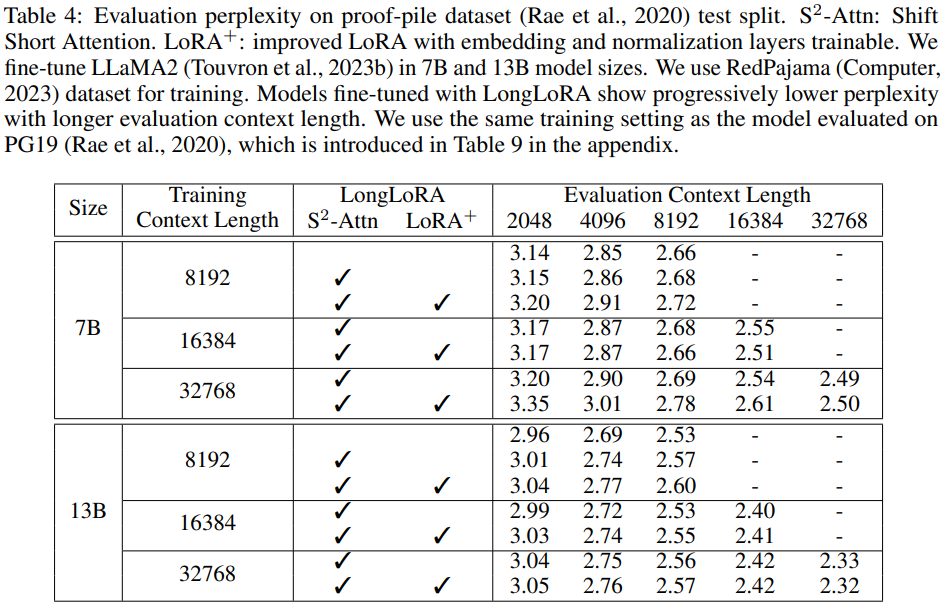
從下表 4 中可以發現,在相同的訓練和評估上下文長度的情況下,困惑度隨著上下文大小的增加而降低。
在下表 5 中,研究者進一步考察了在單臺 8×A100 設備上可微調的最大上下文長度。他們分別將 LLaMA2 7B、13B 和 70B 擴展到 100k、65536 和 32768 上下文長度。LongLoRA 在這些超大設置上取得了令人滿意的結果。此外,實驗還發現擴展模型在較小的上下文長度上會出現一些困惑度下降。
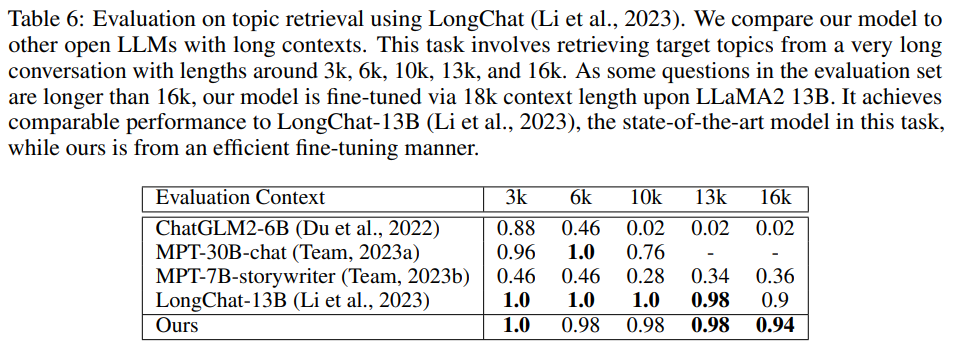
在下表 6 中,研究者將模型與其他開放式 LLM 在 LongChat 中引入的主題檢索任務上進行比較。這個任務是從很長的對話中檢索目標話題,對話長度從 3k、6k、10k、13k 到 16k 不等。
消融實驗
在下表 7 中,研究者將 LLaMA2 7B 細分為各種類型的層。他們分析了 FLOPs:對于 full attention,隨著上下文長度的增加,Attn 的比例也急劇增加。例如,在上下文長度為 8192 時,Attn 占總 FLOP 的 24.5%,而在上下文長度為 65536 時,則增至 72.2%。當使用 S^2 -Attn 時,則下降到 39.4%。

下表 8 展示了在 PG19 驗證集上擴展到 8192 上下文長度時, LLaMA2 7B 模型的復雜度與微調步驟之間的關系。可以發現,如果不進行微調,在第 0 步時,模型的長上下文能力有限。完全微調比低階訓練收斂得更快。兩者在 200 步后逐漸接近,最后沒有出現大的差距。

下表 2 顯示了微調過程中不同注意力模式的效果。
效果展示
模型在閱讀《哈利?波特》的內容后,能夠告訴你斯內普為什么看起來不喜歡哈利,甚至還能總結人物之間的關系。

不僅如此,給它一篇論文,還能幫助你立刻了解相關信息。

更多詳細內容,請參閱原文。




























