













GPT-4最強平替更新!UC伯克利發(fā)布Vicuna v1.5,支持4K和16K上下文,刷新SOTA,LeCun轉贊
GPT-4最強平替更新了!
這次,基于全新的Llama 2,UC伯克利發(fā)布了更新版Vicuna v1.5。
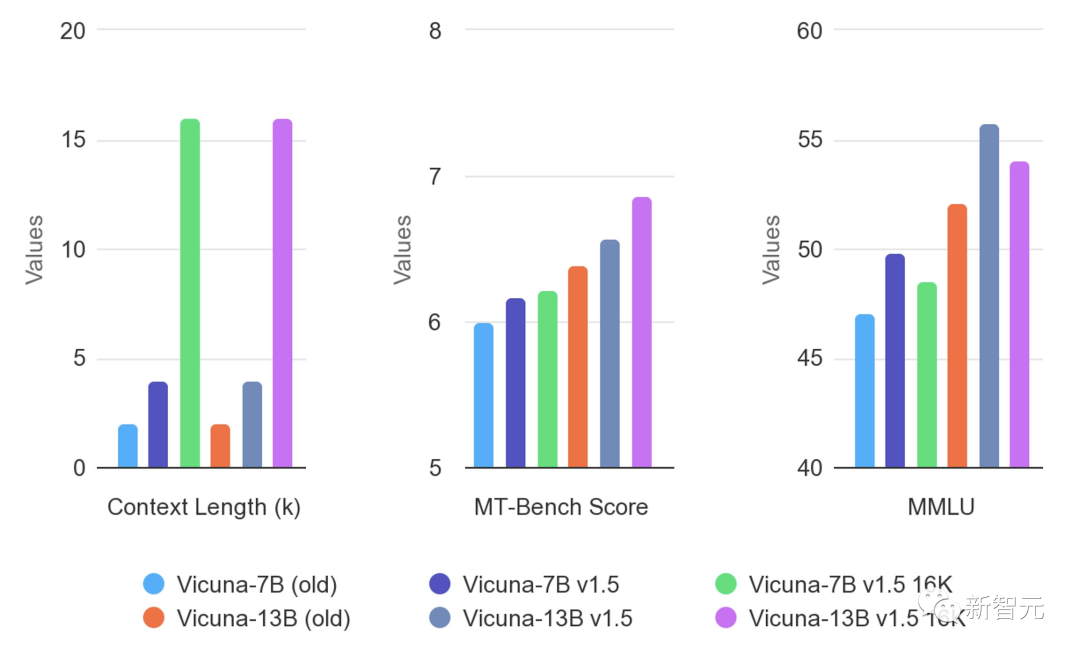
不僅支持4K和16K上下文,并且在幾乎所有基準測試中取得了SOTA。

自3月發(fā)布以來,Vicuna已成為最受歡迎的聊天LLM之一。它在多模態(tài)、AI安全和評估方面的研究具有開創(chuàng)性。
上個月,Vicuna模型在Hugging Face上的下載量超過了200萬次。
LeCun也轉發(fā)了基于自家模型搭建的新版Vicuna。
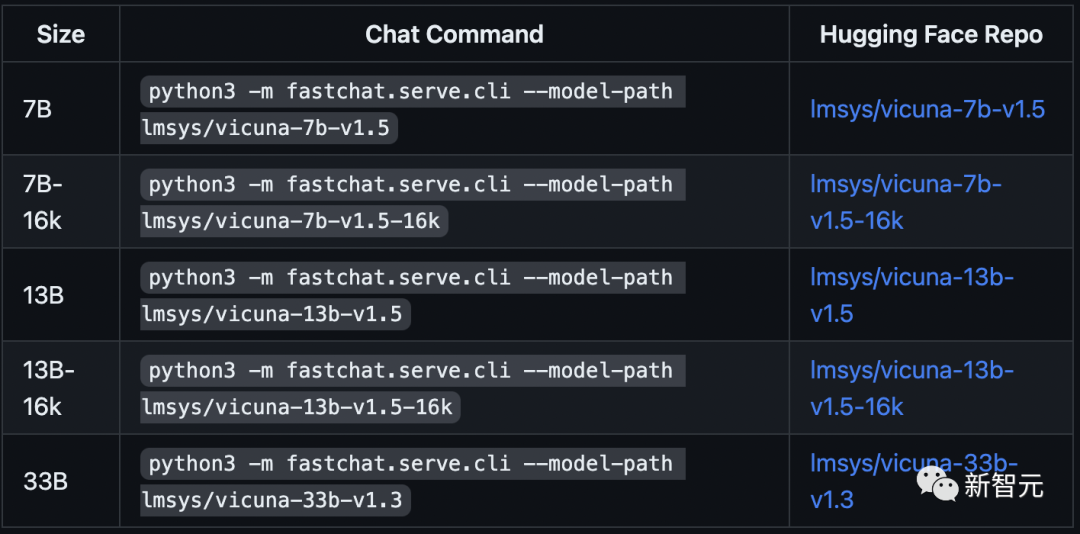
最新模型權重
Vicuna基于LLaMA,應在LLaMA的模型許可下使用。
你可以使用下面的命令開始聊天。
它會自動從Hugging Face存儲庫下載權重。在下面的「使用命令行界面進行推理」部分中查看更多命令選項以及如何處理內存不足。

注意:transformers>=4.31 是16K版本所必需的。
目前,有可試用的demo。
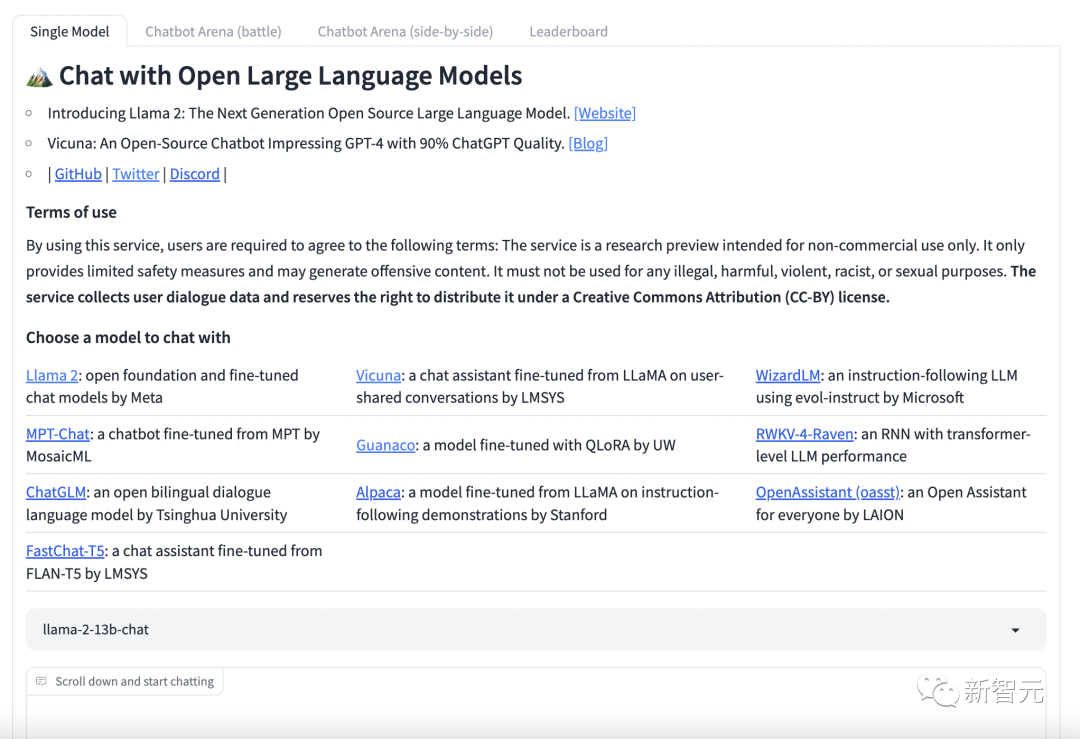
https://chat.lmsys.org/
Vicuna的優(yōu)秀項目
MiniGPT4
地址:https://minigpt-4.github.io
MiniGPT-4的新模型,使用先進的大型語言模型Vicuna進行調優(yōu)。
它在文本預言方面可以達到ChatGPT的90%。在視覺感知方面,研究人員還使用了與BLIP-2相同的預訓練視覺組件。
其中組件由EVA-CLIP的ViT-G/14和Q-Former組成。
MiniGPT-4 只添加了一個映射層,將編碼的視覺特征與Vicuna語言模型對齊,凍結了所有視覺和語言組件參數(shù)。

LLaVA
地址:https://llava-vl.github.io
LLaVA是一個由威斯康星大學麥迪遜分校、微軟和哥大研究人員共同發(fā)布的多模態(tài)大模型。
該模型結合了視覺編碼器和Vicuna對于通用的視覺和語言理解。
其能力接近GPT-4的圖文理解能力,相對于GPT-4獲得了85.1%的相對得分,并在科學QA上實現(xiàn)了當前最先進的準確性。

LLM-Attacks
地址:https://llm-attacks.org
CMU和人工智能安全中心的研究人員發(fā)現(xiàn),只要通過附加一系列特定的無意義token,就能生成一個神秘的prompt后綴。
由此,任何人都可以輕松破解LLM的安全措施,生成無限量的有害內容。
有趣的是,這種「對抗性攻擊」方法不僅突破開源系統(tǒng)的護欄,而且也可以繞過閉源系統(tǒng),包括ChatGPT、Bard、Claude等。
Gorilla
地址:https://github.com/ShishirPatil/gorilla
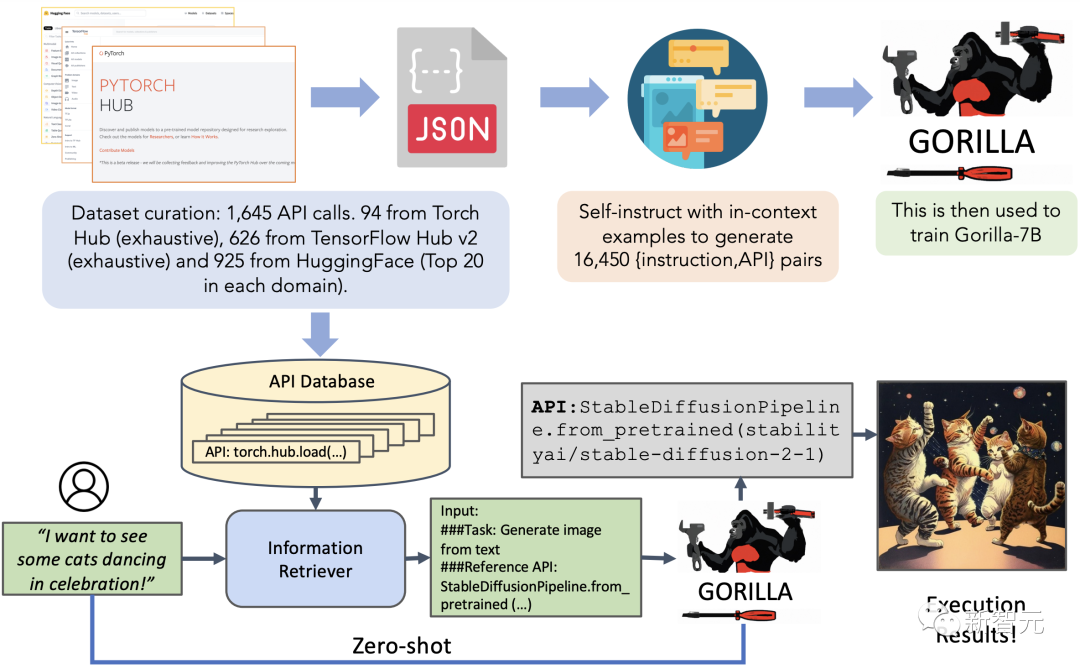
Gorilla是一種基于LLaMA架構的大型語言模型,它可以生成合適的API調用。
它在Torch Hub、TensorFlow Hub和HuggingFace等三個大型機器學習庫的數(shù)據(jù)集上進行了訓練。
Gorilla還可以快速添加新的領域知識,包括Kubernetes、GCP、AWS、OpenAPI等。
在零樣本的情況下,Gorilla的表現(xiàn)優(yōu)于GPT-4、ChatGPT和Claude等模型。
QLoRA
地址:https://github.com/artidoro/qlora
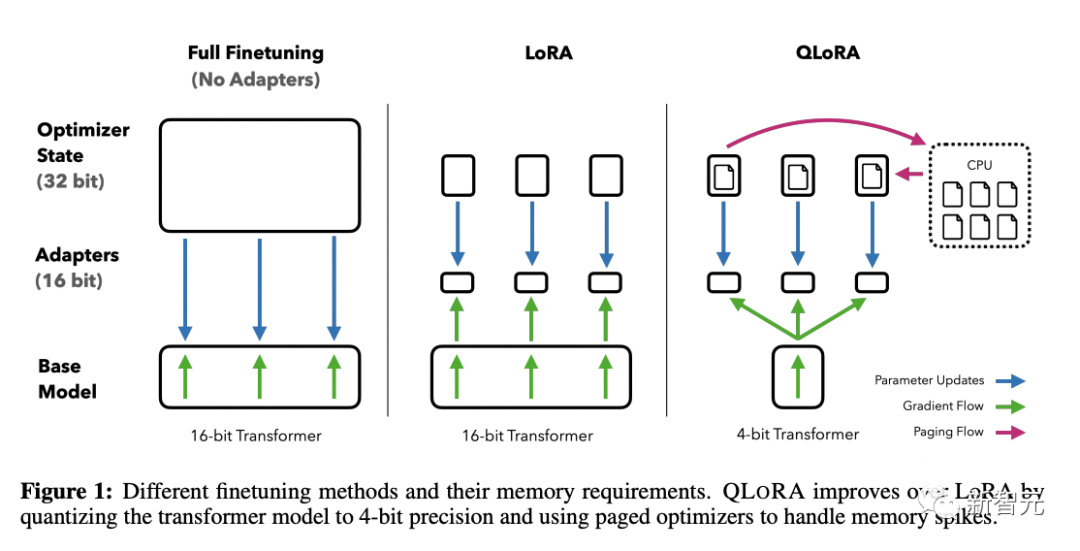
華盛頓大學的研究人員首次證明,在不損失模型性能的前提下,也可以微調量化的4位模型。
他們提出的新方法QLoRA,使用一種新的高精度技術將預訓練模型量化為4位,然后添加一小部分可學習的低秩適配器權重。
這些適配器權重通過量化權重的反向傳播梯度進行調整。
QLoRA方法證明了4位量化模型也可以進行有效的微調,達到與全精度模型相當?shù)男阅堋?/span>
ToolLLaMA
地址:https://github.com/OpenBMB/ToolBench
ToolLLM這個項目,是為了構建開源、大規(guī)模、高質量的指令調優(yōu)SFT數(shù)據(jù)集,以促進構建具有通用工具使用能力的強大語言模型。
研究人員表示,開源LLM能夠掌握數(shù)千種不同的現(xiàn)實世界API,并通過收集高質量的指令調優(yōu)數(shù)據(jù)集來實現(xiàn)這一點。































