對標DALL·E 3!Meta最強文生圖Emu技術報告出爐
前幾天,OpenAI剛剛推出DALL·E 3,文生圖再次上升到一個新階段,甚至有網友紛紛表示R.I.P. Midjourney。
在28號的Meta Connect大會上,小扎也推出了自家的人工智能圖像生成模型——Emu(Expressive Media Universe)。
Emu最大的特點是,只用簡單的文字,5秒即生圖片。
比如:「一只在彩虹森林中的神仙貓咪」。

「徒步旅行者和北極熊」。

「水下的航天員」。

「在花叢中的一位女士」。

「如果恐龍是一只貓咪」。

與其他文生圖模型相比,Emu最有趣的是,可以一鍵生成表情包。
當你正和人聊天時,不用絞盡腦汁去翻找一個合適的表情包了。
比如,和朋友約好了背包旅行,想要發一個生動的準備去旅行的表情包。
「一只快樂的刺猬騎著摩托車」
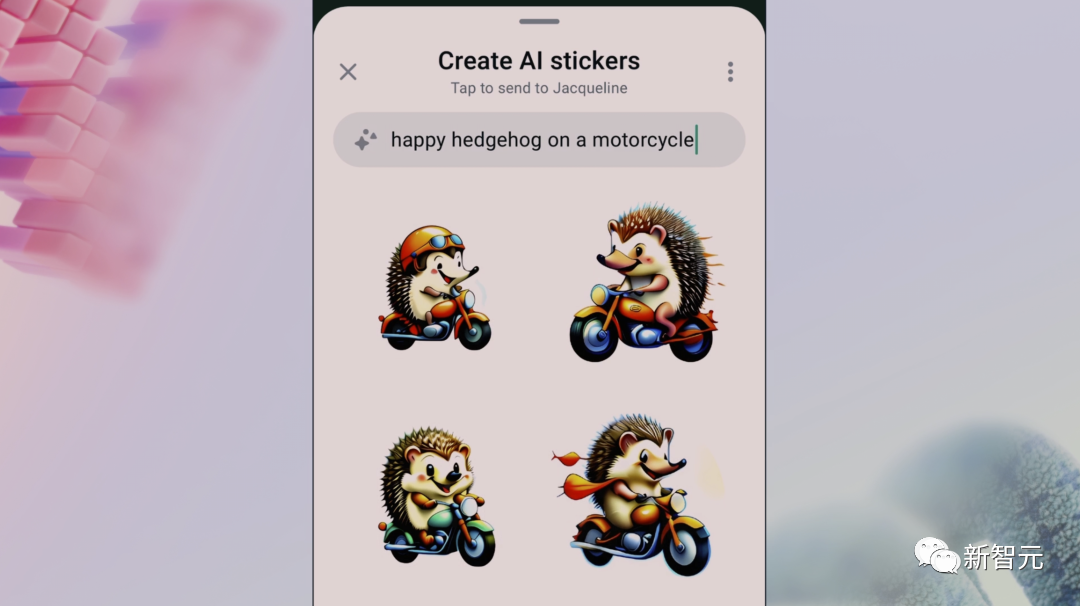
選擇自己喜歡的一個,發送。
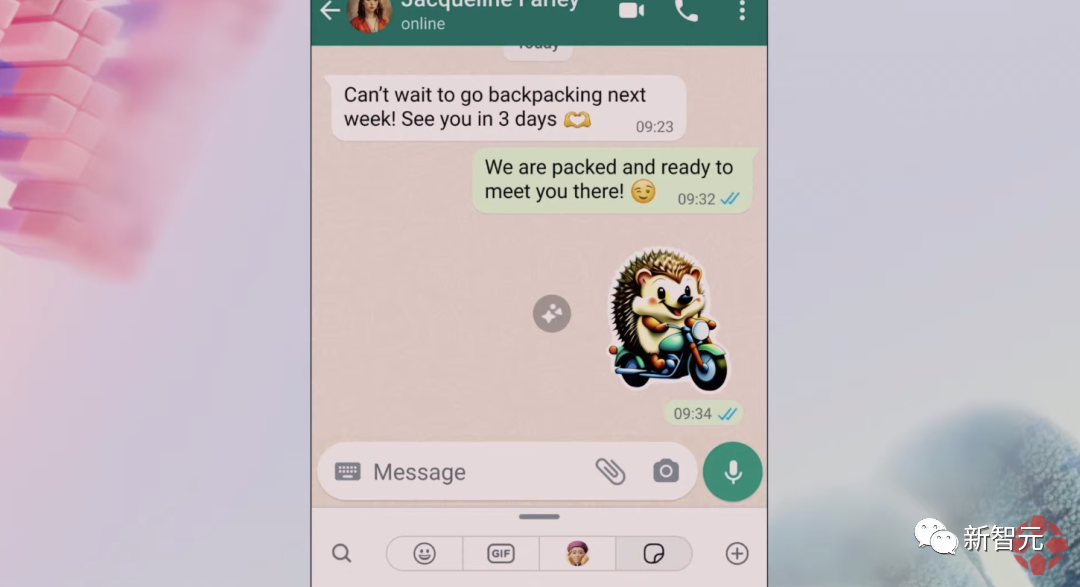
當然了,你可以生成各種各樣的表情包,僅需要簡單幾個詞。
很快,任何人都可以在Ins中進行圖像編輯——重換風格和背景,背后就是由Emu和分割模型SAM加持。
重換風格,可以根據你所描述的風格,重構想像輸出圖片。
如下, 輸入「水彩」,你的照片就立刻變成水彩畫了。

或者,把扎克伯格小時候的照片變成「搖滾朋克風格」。

又或者給金毛換一個「長頭發」,就得到了:
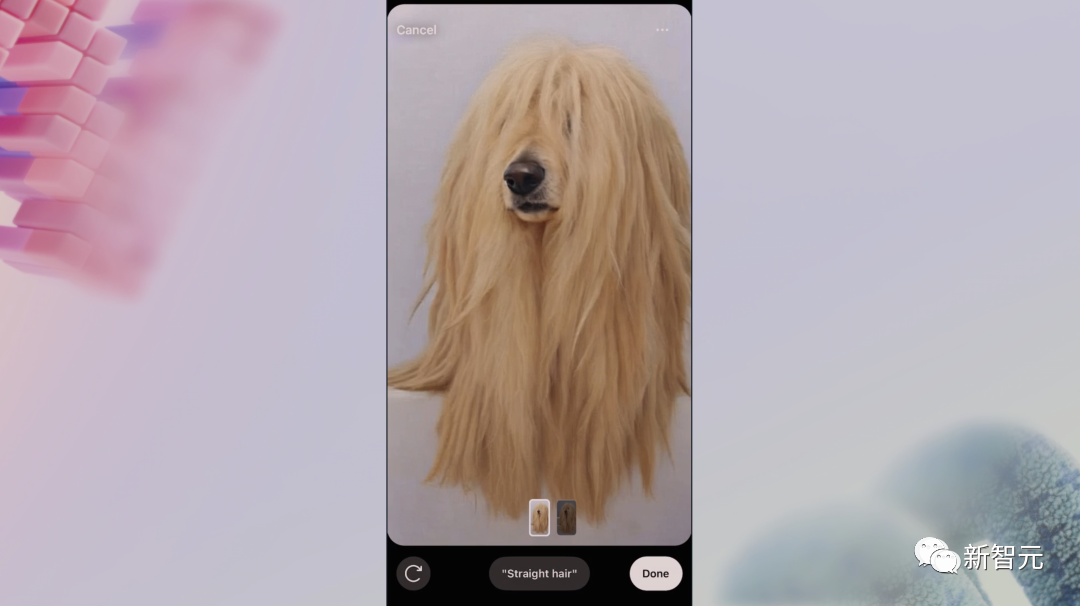
你甚至可以為圖片更換背景。
找到一張自己躺在草坪中的照片,輸入「被小狗包圍」,一群可愛的小狗就伴你左右了。
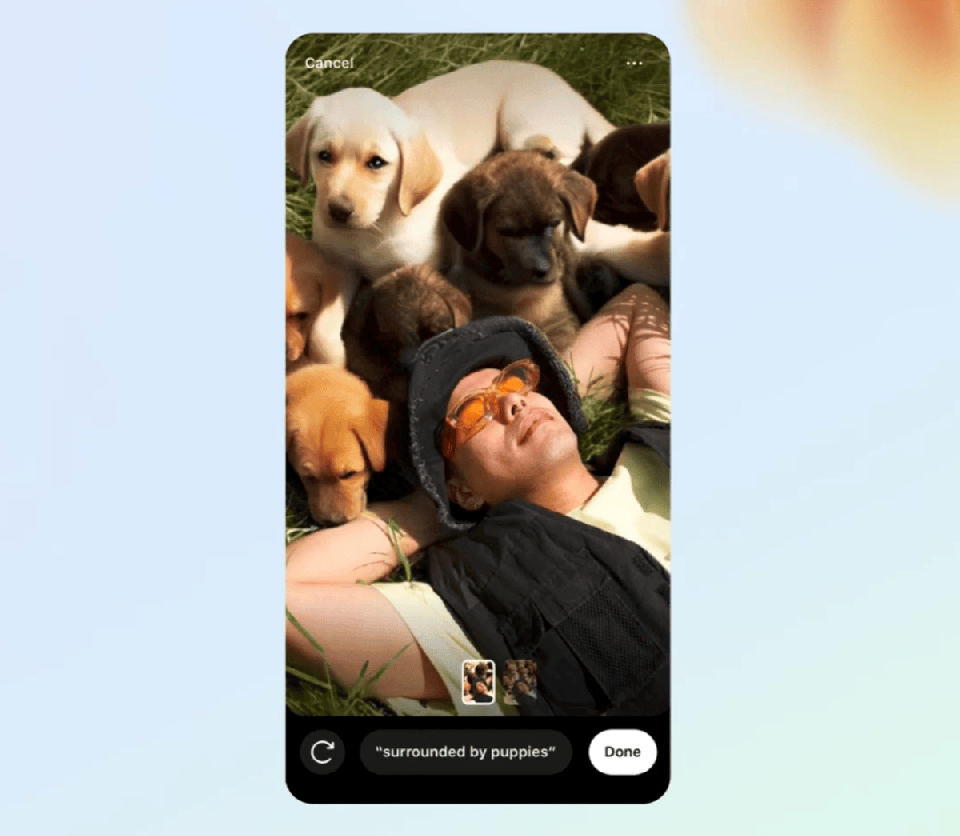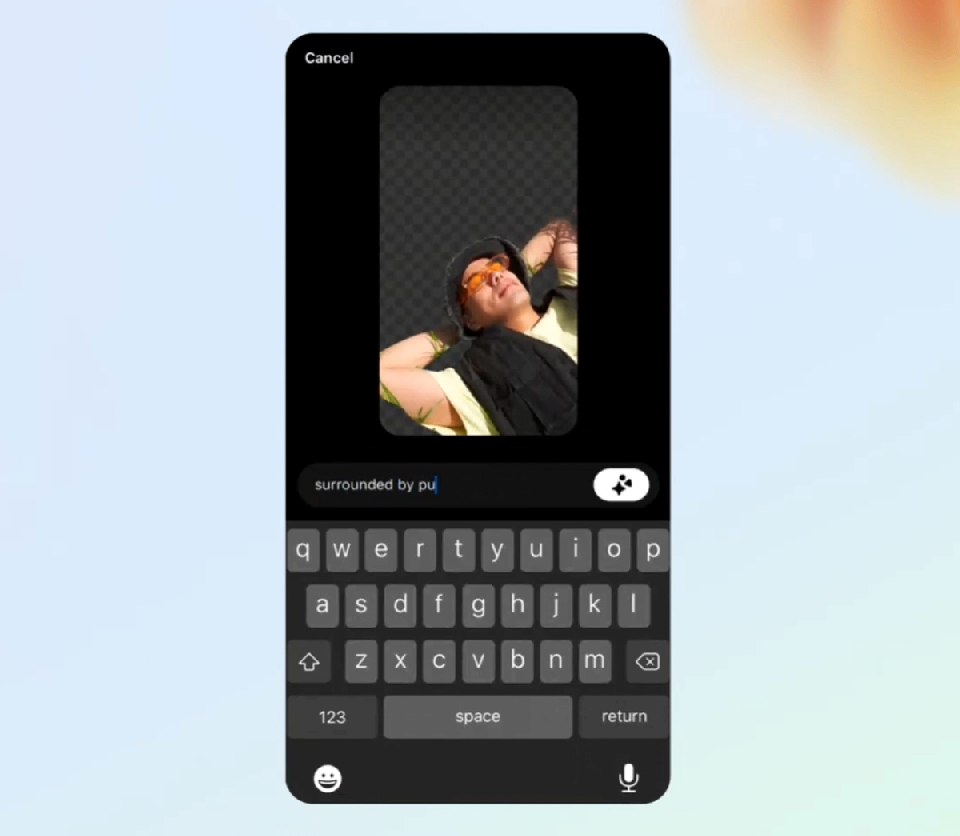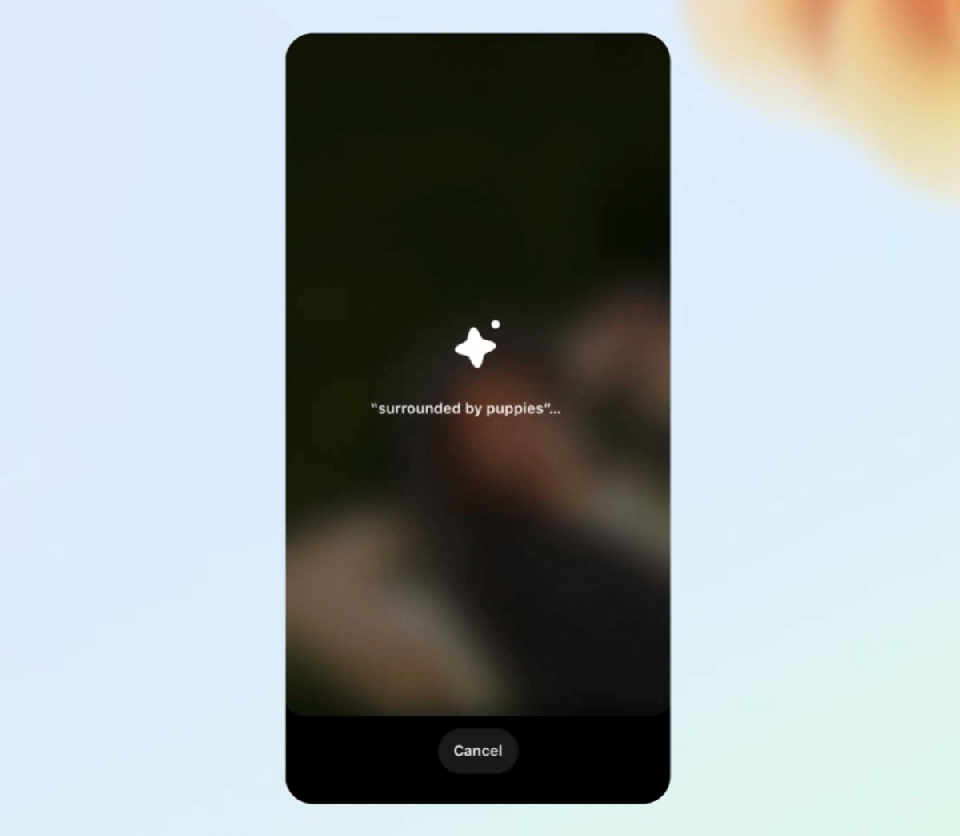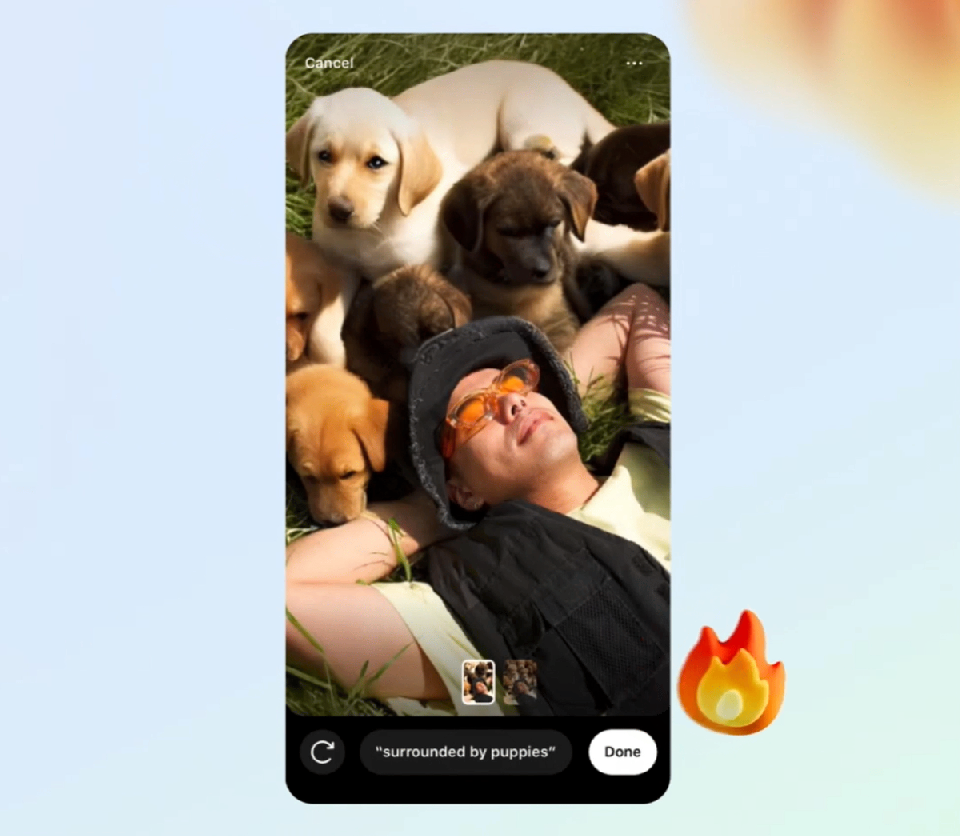
又或者,家庭合照中,背景也可以隨意切換。

Emu在發布會上可算是風光了一把,但其實在現場演示的前一天,Meta就在arXiv更新了Emu模型的論文。

論文地址:https://arxiv.org/abs/2309.15807
在這篇論文中,Meta介紹了Emu的訓練方法:質量調整(quality-tuning),一種有監督的微調。
質量調整解決了在利用網絡規模的圖像-文本訓練文本-圖像模型時,生成高度美觀的圖像面臨的挑戰:美學對齊。
通過質量調整,可以有效指導預訓練模型專門生成具有高度視覺吸引力的圖像,同時保持視覺概念的通用性。
研究人員還將其泛用到其他模型架構中,如pixel diffusion和masked generative transformer,證明了質量調整方法的通用性。
質量調整的方法
生成模型的訓練包括兩個階段:知識學習和質量學習。
在知識學習階段,目標是獲得從文本生成幾乎任何內容的能力,這通常需要在數以億計的圖像-文本對上進行預訓練。
而在質量學習階段,模型將被限制輸出高質量和美觀的圖片。
Meta研究人員將以提高質量和促進審美一致性為目的的微調過程稱為質量調整。

經質量調整的Emu生成的圖像
但質量調整有三個關鍵:
(1)微調數據集可以小得出奇,大約只有幾千張圖片;
(2)數據集的質量非常高,這使得數據整理難以完全自動化,需要人工標注;
(3)即使微調數據集很小,質量調整不僅能顯著提高生成圖片的美觀度,而且不會犧牲通用性,因為通用性是根據輸入提示的忠實度來衡量的。
整個質量調整過程有以下幾個步驟:
潛在擴散架構
研究人員設計了一種可輸出1024 X1024分辨率圖像的潛在擴散模型。遵循標準的潛在擴散架構設計,模型有一個自動編碼器(AE)將圖像編碼為潛在嵌入,并有一個U-Net學習去噪過程。
研究發現,常用的4通道自動編碼器(AE-4)架構由于壓縮率高,往往會導致所構建圖像的細節丟失。
而這一問題在小物體中尤為明顯。
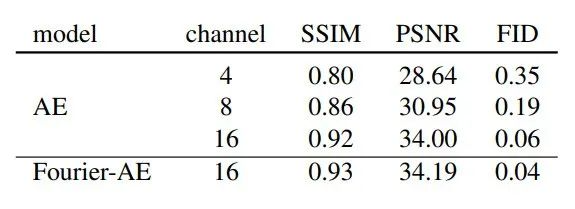
為了進一步提高重建性能,研究人員使用了對抗性損失,并使用傅里葉特征變換對RGB圖像進行了不可學習的預處理,將輸入通道維度從3(RGB)提升到更高維度,以更好地捕捉精細結構。
用于不同通道尺寸的自動編碼器的定性結果見下圖。

此外,研究人員還增加了每個階段的通道大小和堆疊殘差塊數量,以提高模型容量。
并且,此研究使用CLIP ViT-L和T5-XXL的文本嵌入作為文本條件。
預訓練
研究人員策劃了一個由11億張圖像組成的大型內部預訓練數據集來訓練模型,訓練過程中模型的分辨率逐步提高。
在預訓練的最后階段,研究人員還使用了0.02的噪聲偏移,這有利于生成高對比度的圖像,從而提高生成圖像的美感。
構建高質量對齊數據
從最初的數十億張圖片開始,使用一系列自動過濾器將圖片數量減少到幾億張。
這些過濾器包括但不限于去除打擊性內容、美學分數過濾器、光學字符識別(OCR)字數過濾器(用于去除覆蓋過多文字的圖片)以及 CLIP 分數過濾器(用于去除圖片與文字對齊度較差的樣本)。
然后,通過圖像大小和縱橫比進行額外的自動過濾。
并且,為了平衡來自不同領域和類別的圖片,研究人員利用視覺概念分類來獲取特定領域的圖片(如肖像、食物、動物、風景、汽車等)。
最后,通過基于專有信號(如點贊數)的額外質量過濾,這樣可以將數據進一步減少到200K Human Filtering。
接下來,將數據集分兩個階段進行人工過濾,只保留極具美感的圖片。
在第一階段,訓練通用注釋器將圖片庫縮減到20K張。這一階段的主要目標是優化召回率,確保排除通過自動過濾的中低質量圖片。
在第二階段,聘請精通攝影原理的專業注釋員,篩選出高審美質量的圖片,如下圖。

這一階段的重點是優化精確度,即只選擇最好的圖片。數據集遵循高質量攝影的基本原則,在各種風格的圖像中普遍獲得更具美感的圖像,并通過人工評估進行驗證。
質量調整
將視覺效果極佳的圖像視為所有圖像的子集,這些圖像具有一些共同的統計數據。
研究人員使用64個小批量數據集對預訓練模型進行微調。
在此階段使用0.1的噪聲偏移。但需要注意的是,盡早停止微調非常重要,因為在小數據集上微調時間過長會導致明顯的過擬合,降低視覺概念的通用性。
但微調迭代次數不能超過5K,這個總迭代次數是根據經驗確定的。
實驗結果
質量調整的效果
研究人員將經過質量調整的Emu模型與預先訓練的模型進行比較。
質量調整前后的隨機定性測試結果見下圖。

可以看到非寫實圖像也具有很高的美感,這驗證研究提出的假設:在質量調整數據集中遵循某些攝影原則,可以提高各種風格的美感。

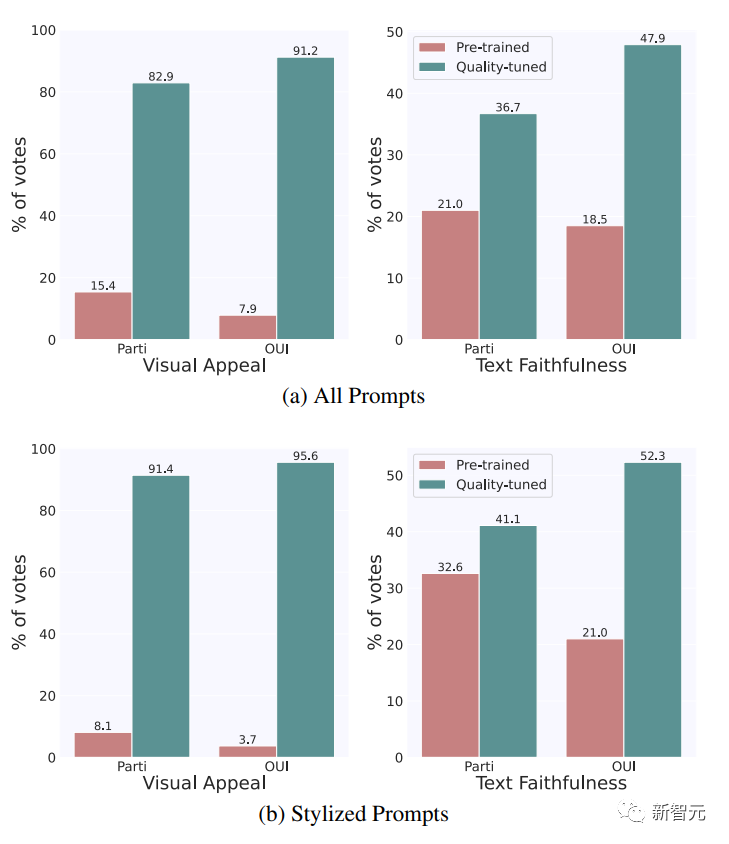
從數量上看,經過質量調整后,Emu在視覺吸引力和文本可信度方面都有顯著優勢。
具體來說,在Par-tiPrompts和OUl Prompts上,分別有 82.9% 和 91.2% 的視覺吸引力以及 36.7% 和 47.9% 的文本忠實度首選Emu。
相比之下,在視覺吸引力方面,預訓練模型分別只有15.4% 和 7.9%的時間受到青睞,而在文字忠實性方面,PartiPrompts和OUl Prompts分別有 21.0% 和 18.5% 的時間受到青睞。
其余案例的結果均為平局。從這兩組涵蓋不同領域和類別的大量評估數據中視覺概念的通用性沒有下降。
相反,這些改進廣泛適用于各種風格。
SoTA 背景下的視覺吸引力
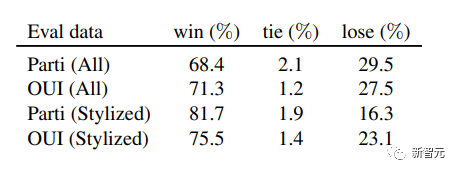
為了將Emu生成的圖像的視覺吸引力與當前最先進的技術進行比較,研究人員將Emu與SDXLV1.0進行了比較。
可以看到,Emu比 SDXLv1.0 的視覺吸引力高出很多,包括在風格化(非寫實)提示上。
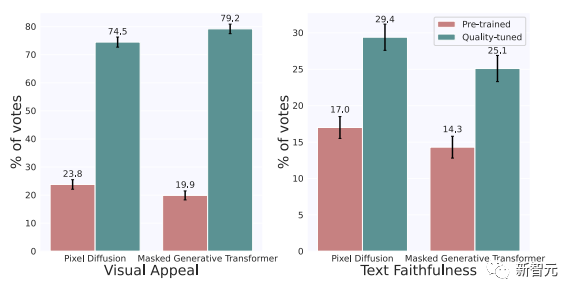
并且,Meta證實了質量調整也可以改進其他流行的架構,如pixel diffusion和masked generative transformer。
研究人員從頭開始重新實現和訓練一個pixel diffusion和masked generative transformer,然后在 2000 張圖像上對它們進行質量調整。
之后,研究人員在1/3隨機抽樣的PartiPrompts上對這兩種經過質量調整的模型進行了評估。
如下圖所示,經過質量調整后,兩種架構在視覺吸引力和文本忠實度指標上都有顯著改善。
消融研究
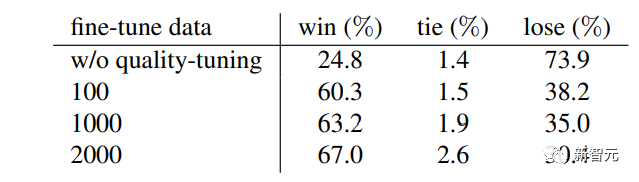
最后,Meta對微調數據集進行了消融研究,重點關注視覺吸引力,主要對數據集大小的影響進行研究。
下表中報告了在不同大小的隨機抽樣子集上進行的質量微調的結果,包括100、1000和2000的大小。
可以看到,即使只有100個微調圖像,模型也能夠被引導生成視覺上吸引人的圖像。
與SDXL相比,微調后的勝率從24.8%躍升至了60%。