













拆掉英偉達護城河,細節曝光!世界最快超算用3072塊AMD GPU訓完超萬億參數LLM
用AMD的軟硬件系統也能訓練GPT-3.5級別的大模型了。
位于美國橡樹嶺國家實驗室(Oak Ridge National Laboratory)的全世界最大的超算Frontier,集合了37888個MI250X GPU和9472個Epyc 7A53 CPU。

最近,研究人員只使用了其中8%左右的GPU,就訓練了一個GPT-3.5規模的模型。
研究人員成功地使用ROCM軟件平臺在AMD硬件上成功地突破了分布式訓練模型的很多難點,建立了使用ROCM平臺在AMD硬件上為大模型實現最先進的分布式訓練算法和框架。
成功地在非英偉達和非CUDA平臺上為高效訓練LLM提供了可行的技術框架。
訓練完成后,研究人員將在Frontier上訓練大模型的經驗的總結成了一篇論文,詳細描述了期間遇到的挑戰以及克服的困難。

論文鏈接:https://arxiv.org/abs/2312.12705
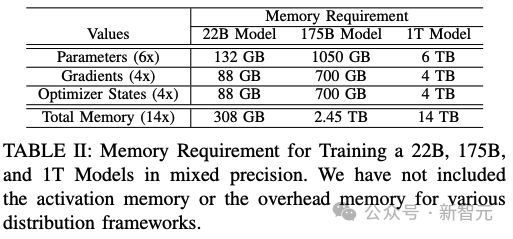
在研究人員看來,訓練一萬億參數規模的LLM最為重大的挑戰是所需的內存量——至少需要14TB的內存。
而單塊GPU最大的內存只有64GB,這意味著需要并行使用多個AMD MI250X GPU才能完成訓練。
而并行更多的GPU,對GPU之間的通信提出非常高的要求。如果不能有效地利用GPU之間的帶寬通信,大部分的GPU計算資源都會被浪費。
具體來說,研究人員將Megatron-DeepSpeed分布式訓練框架移植到Frontier上,以支持在AMD硬件和ROCM軟件平臺上進行高效的分布式訓練。
研究人員將基于CUDA的代碼轉換為HIP代碼,還預構建DeepSpeed ops以避免ROCM平臺上的JIT編譯錯誤,并且修改代碼以接受主節點IP地址為參數進行PyTorch Distributed初始化。
在220億參數模型上,Frontier的訓練峰值吞吐量達到了38.38%,1750億參數模型峰值吞吐量的36.14%,1萬億參數模型峰值吞吐量的31.96%。
訓練一個1000B級別的模型,最終研究團隊將縮放效率(scaling efficiency)做到了87%。同時,作為對比,研究人員還同時訓練了另一個1750億參數的模型,縮放效率也達到了89%。
另一方面,因為現在這樣規模的模型訓練都是在基于英偉達的硬件和CUDA生態中完成的,研究人員表示在AMD的GPU之上想要達到類似的訓練效率和性能,還有很多工作需要做。
訓練細節
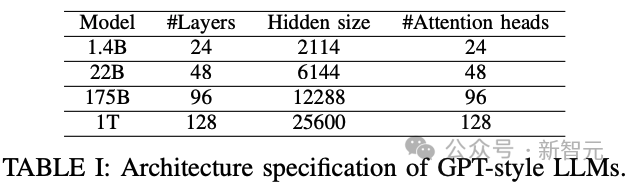
GPT式模型結構和模型尺寸
Transformer模型由兩個不同的部分組成,編碼器塊和解碼器塊。
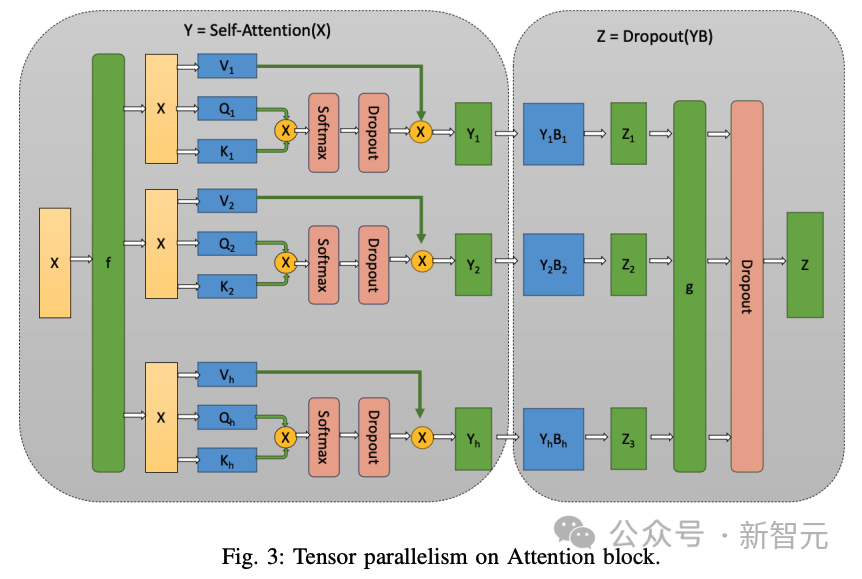
編碼塊有助于捕捉非因果自注意力,即句子中的每個標記都能注意到左右兩邊的token。
另一方面,解碼塊有助于捕捉因果自注意,即一個token只能注意到序列中過去的標記。
最簡單的GPT類模型由一疊類似的層組成。
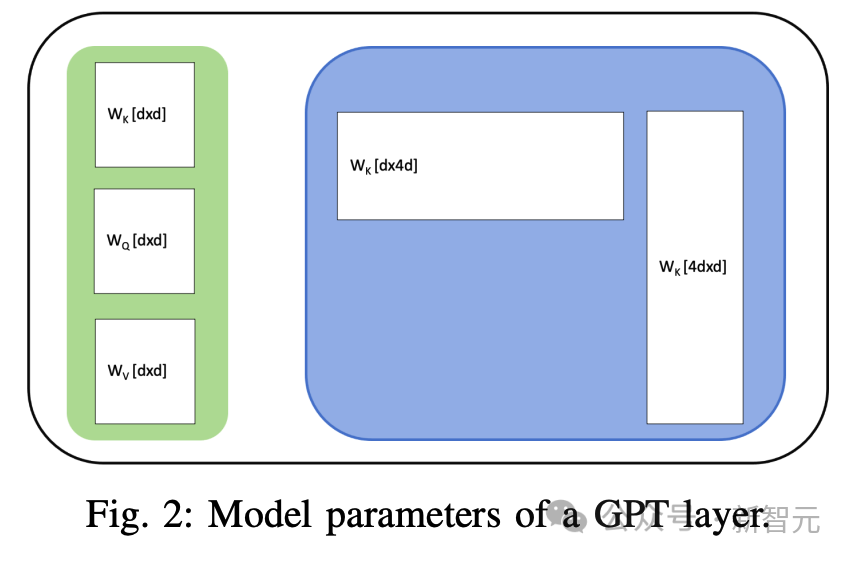
每一層都有一個注意力區塊和一個前饋網絡(FFN)2。注意力區塊有三組參數 ,其中d是模型的隱藏維度。FFN模塊有兩層,分別為權重
,其中d是模型的隱藏維度。FFN模塊有兩層,分別為權重 和
和 所以,每層有11d^2個參數。
所以,每層有11d^2個參數。
由于嵌入層位于模型的起始層,參數數大致為12Ld^2,其中L為層數,d為隱藏維度。
根據這個公式,研究人員可以定義出下表中大小分別為22B、175B和1T的三個模型。
大部分內存需求來自模型權重、優化器狀態和梯度。
在混合精度訓練中,每個模型參數需要6個字節,4個字節用于在fp32中保存模型,2個字節用于在fp16中進行計算。
優化器狀態的每個參數需要4個字節,以將動量保存在fp32中。
研究人員需要為每個參數保存一個fp32梯度值。因此,在使用Adam優化器進行混合精度訓練時,最小內存需求如下表所示。
每個Frontier節點有8個MI250X GPU構成,每個都有64GB的HBM內存。
因此,內存需求表中,可以得出結論:要擬合模型的一個副本,模型并行化是必要的。模型并行可以通過張量和碎片數據并行在隱維度上實現,也可以通過管線并行(pipeline paralism)在層維度上實現。
管線并行
管線并行將模型分成p個階段,每個階段大約有L/p層。然后,將批次分割成微批次,每執行一步,一個微批次通過一個階段。
每個階段都放置在一個GPU上。
最初,只有第一個GPU可以處理第一個微批次。在第二個執行步驟中,第一個微批次進入第二個階段,而第一個微批次現在可以進入第一個階段。
如此反復,直到最后一個微批次到達最后一個階段。
然后,反向傳播開始,整個過程反向繼續。在每個批次之后引入同步點,以保持正確的計算順序,這需要沖洗管線階段。
因此,在一個批次處理的開始和結束時,托管較早和較晚階段的GPU會處于空閑狀態,從而導致計算時間的浪費或管線泡沫。
管線泡沫分數為p-1m,其中m是批次中微批次的數量。
簡單的GPipe調度會產生很大的管線泡沫。有一些額外的方法可以減少管線泡沫。
其中一種方法是PipeDream提出的1F1B調度,在前向傳遞過程中,最初允許微批次向前流動,直到最后一組收到第一個微批次。
但隨后第一個批次開始向后傳播,從那時起,前向傳遞總是伴隨著后向傳遞,因此被稱為1F1B。為了進一步縮小氣泡大小,研究人員提出了一種交錯計劃,即在單個GPU上放置多個較小的管線組,而不是在單個GPU上放置一個管線組。
1F1B計劃的管線泡沫大小大約為p/m,其中p是管線組的數量,m是微批次的數量。
微批次的數量。對于帶交錯功能的1F1B計劃,泡沫大小為m×v p-1,其中v是放置在單個GPU上的交錯組的數量。
分片數據并行(Sharded Data Parallelism)
分片數據并行將模型參數、優化器狀態和梯度按行分片,并在每個GPU上放置一個分區。
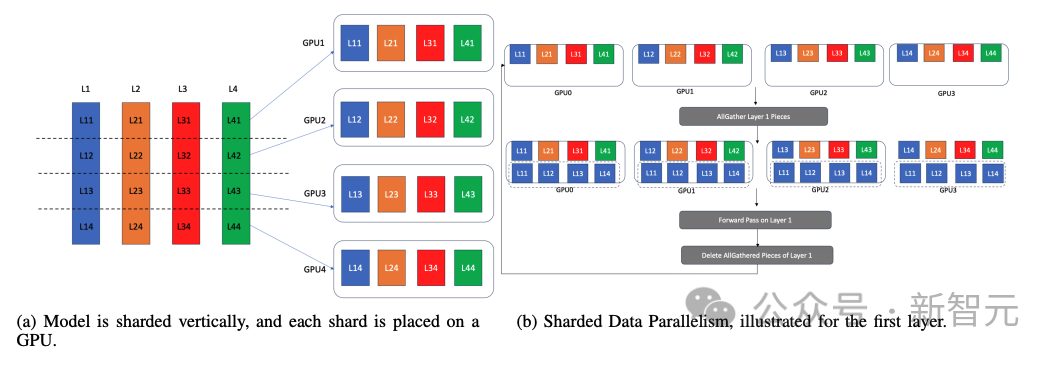
由于訓練一次推進一個層,因此計算設備的內存中只需要一個完整的層和相關值(優化器狀態、梯度和參數)。
分片數據并行性正是利用了這一點;在執行一個層之前,通過在所有GPU上執行該層的所有收集,在所有GPU 上將該層實體化4b。
現在,所有GPU都有相同層的副本。然后,在不同的GPU上對不同的數據批次執行該層。之后,每個GPU會刪除該層的所有收集部分,并通過全收集為下一層的實體化做好準備。
通過這種方式,它模擬了數據并行性,但不是每個GPU都托管了整個模型的完整副本,而只是托管當前活動層的副本。
分片數據并行可以促進大型模型在GPU上的數據并行訓練,即使模型太大,無法容納在單個GPU的內存中。
DeepSpeed的ZeRO優化器在不同程度上支持分片數據并行。ZeRO-1只對優化器狀態進行分片,ZeRO-2對梯度和優化器狀態進行分片,ZeRO-3則對優化器狀態、梯度和模型參數進行分片。
另一方面,PyTorch FSDP(完全分片數據并行)對所有三種數據進行了分片,并通過將分片數據并行與傳統數據并行相結合,支持混合數據并行。
3D并行和Megatron-DeepSpeed
僅使用單一并行策略來實現模型并行可能是一種低效方法。例如,如果研究人員只使用張量并行來對模型進行水平切分,那么張量可能太薄,需要頻繁進行全還原通信,從而減慢訓練速度。
另一方面,如果研究人員將模型劃分為過多的管線階段,每個階段的計算量就會很小,這就需要頻繁的通信。一個已知的問題是,在多個節點上執行張量并行訓練需要緩慢的樹狀allreduce。
以混合方式使用多種并行模式,可以最大限度地減少性能不佳的地方。三維并行結合了張量、管線和數據(傳統和分片)并行技術,以充分利用資源。
通過適當的設置,三維并行技術可將通信與計算重疊,從而減少通信延遲。
人工智能領域使用的三維并行標準代碼庫基于Megatron-LM。MegatronDeepSpeed擴展了Megatron-LM的功能,增加了DeepSpeed功能,如ZeRO-1 sharded數據并行和重疊1F1B的管線并行。
計劃的管線并行。不過,這些標準代碼庫都是針對英偉達GPU和CUDA平臺開發的。
作為最完整的框架,研究人員希望在Frontier上使用Megatron-DeepSpeed,Frontier 是AMD系統,其軟件棧建立在ROCM軟件平臺上。
將Megatron-DeepSpeed移植到Frontier
Megatron-DeepSpeed代碼庫來源自英偉達公司的Megatron-LM代碼庫,然后微軟在其中添加了DeepSpeed ZeRO優化器、管線并行性和MoE。
英偉達負責開發Megatron-LM,因此其代碼庫是以英偉達GPU和CUDA環境為目標平臺開發的。
將該代碼庫移植到AMD平臺上運行會面臨一些挑戰。
1. CUDA代碼:CUDA代碼不能在AMD硬件上運行,但HIP(一種類似CUDA的C/C++擴展語言)可以。
研究人員使用hipify工具將CUDA源代碼轉換為HIP代碼,使用hipcc構建可共享對象(so文件)然后使用pybind從Python代碼訪問這些可共享對象。
2. DeepSpeed操作:大多數DeepSpeed操作都是在執行訓練管線期間通過JIT(及時)編譯構建的。
但是,DeepSpeed操作的JIT編譯在ROCM平臺上不起作用,因此研究人員在安裝DeepSpeed時預先構建了所有操作。
研究人員禁用了Megatron-DeepSpeed代碼庫中的所有JIT功能,以避免任何運行時錯誤。
3. 初始化PyTorch分布式環境:Megatron-DeepSpeed利用PyTorch分布式初始化創建各種數據和模型并行組。
初始化過程需要指定一個計算節點作為「主」節點,所有分布式進程都需要它的IP地址。
研究人員修改了代碼庫,以接受MASTER ADDR作為參數。
研究人員準備了一個啟動腳本,從SLURM節點列表中讀取第一個節點的IP地址,并將其作為參數傳遞給所有使用srun啟動的進程。
然后,初始化代碼會使用這個MASTER ADDR進行PyTorch分布式初始化。
4. 通過ROCM平臺軟件提供的庫/軟件包:研究人員與AMD開發人員合作,獲得了一些基本CUDA軟件包的ROCM版本,如APEX。
APEX是英偉達的混合精度庫,Megatron-DeepSpeed代碼庫大量使用該庫進行混合精度訓練。
他們還改編了支持ROCM的FlashAttention和FlashAttention2庫版本,供Frontier上的編譯器使用。Flash-Attention操作被移植到AMDGPU上,使用的內核來自Composable Kernel庫。
各種分配策略的實證分析
張量并行
張量并行法按行劃分模型層,每層之后都需要通過Allreduce對部分激活值進行聚合。
每層執行后的AllReduce成本很高,這取決于張量并行組中GPU之間的通信帶寬,通信量取決于隱藏大小和微批量大小。
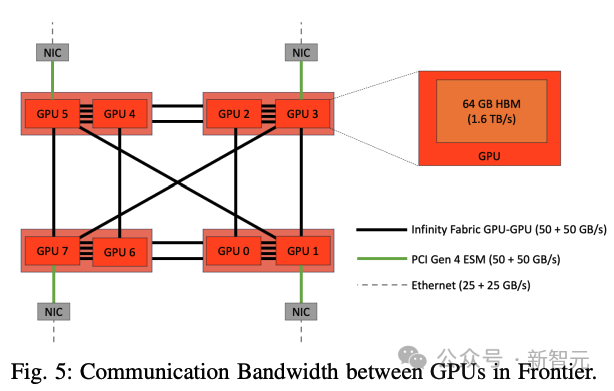
下圖5顯示了前沿GPU之間的通信帶寬。一個節點中有8個GPU,單個芯片中的GPU通過四個(50+50 GB/s)無限結構連接。

跨芯片的GPU之間的帶寬是它的一半。但是,跨節點的GPU之間的帶寬是25+25 GB/s。
因此,從網絡拓撲和配置來看,TP = 2的通信速度最快,TP = 4或8的通信速度次之。
但是,如果TP ? 8,通信將通過較慢的以太網進行,通信速度將大大降低。因此,將TP保持在[2, 4, 8]范圍內應該是最佳策略。
研究人員使用8個GPU訓練一個1.4B的模型,TP值從1到8不等,結果發現TP值越小,吞吐量越高。
觀察結果III.1:TP值越大,訓練效果越差。
B. 管線并行
管線并行化沿著層維度劃分模型,并將連續的層劃分為管線階段。一個微批次的執行從一個階段流向下一個階段。
管線氣泡是使用這種并行方式進行高效訓練的限制因素。
研究人員觀察了大M或大GBS的效果,以了解22B參數和1T參數大小的兩個模型對GPU吞吐量的影響(下圖7)。
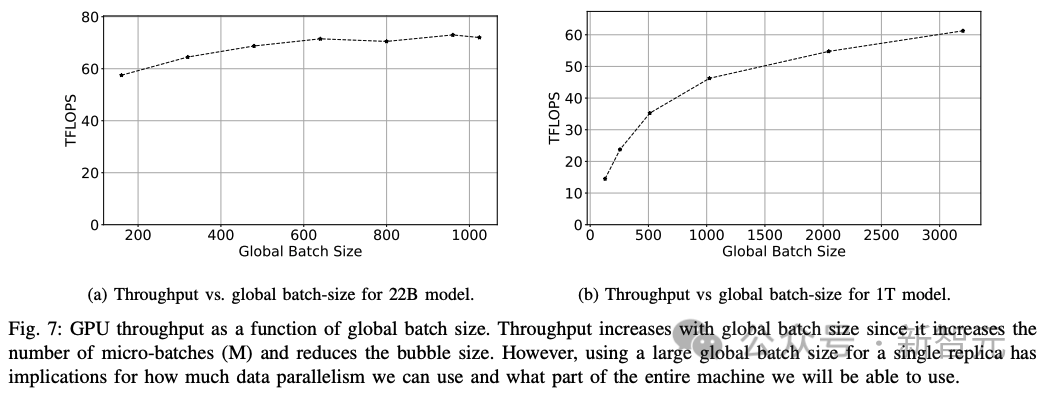
觀察結果III.2:使用大的全局批次大小或許多微批次使管線階段飽和,可將管線氣泡大小降至最低。
管線階段數量的影響:接下來,研究人員研究管線級數對訓練性能的影響。直觀地說,管線階段越多,意味著通信發生前的計算量越少。
在全局批次大小(微批次數量)固定的情況下,管線階段數量越多,計算量越少。
氣泡大小會隨著管線級數的增加而增加。研究人員還嘗試增加管線級數,同時保持PMP固定不變,按比例增加全局批量大小。
觀察結果III.3:在保持全局批量大小不變的情況下,增加管線級數會增加管線氣泡的大小,并降低訓練性能。
觀察結果III.4:如果管線級數與微批次數的比例保持不變,則隨著管線級數的增加,訓練性能也會保持不變。
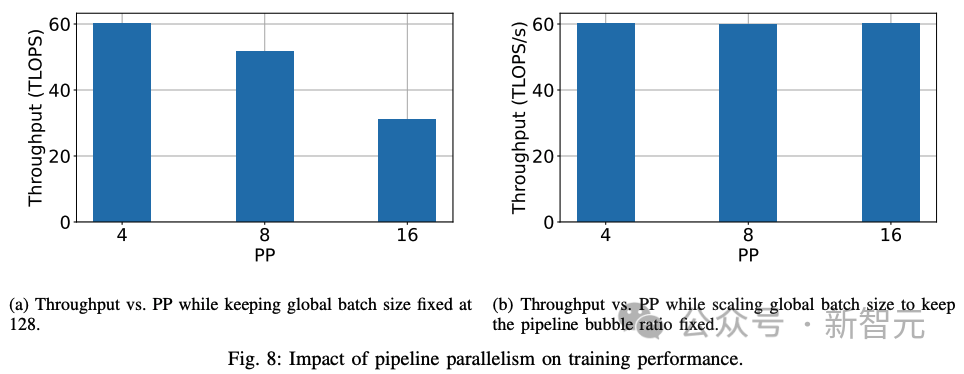
從第一個實驗(上圖8a)來看,隨著管線級數的增加,訓練性能會下降。但是,通過調整全局批次大小來固定氣泡比例,可以保持吞吐量(上圖8b)。
通過實驗、超參數調整和分析,研究人員確定了在Frontier上訓練Trillionparameter模型的高效策略,該策略結合了各種分布策略和軟件優化。
訓練萬億參數模型
訓練萬億參數模型的高效策略
通過增加微批次數量使管線階段飽和:研究人員使用DeepSpeed(來自 DeepSpeed-Megatron,但不是Megatron的版本)提供的管線并行性。這種管線并行算法是PipeDream的算法,其中多個階段相互重疊,并采用1F1B算法來減少氣泡大小。
但是,如果管線級數沒有達到飽和,氣泡大小就會增大。為確保飽和,微批次的數量必須等于或超過管線級數。
將張量并行限制為單個節點/八個GPU:由于AllReduce操作過于頻繁,而且需要對每一層都執行,因此分散在不同節點上的層會導致跨節點GPU之間基于樹狀結構的AllReduce,而通信延遲則會成為一個重要瓶頸。
使用Flash-Attention v2:與普通注意力實現相比,研究人員觀察到使用Flash-attention可將吞吐量提高30%。
使用ZeRO-1優化器實現數據并行:研究人員使用ZeRO-1實現數據并行,以減少內存開銷。
使用AWS的RCCL插件提高通信穩定性:AWS OFI RCCL插件使EC2開發人員能夠在運行基于AMD RCCL的應用程序時將libfabric用作網絡提供商。在Frontier上,該插件的使用顯示了通信的穩定性。
萬億參數模型的訓練性能
根據從超參數調整中吸取的經驗教訓,研究人員確定了一組大小為220億個參數和1750億個參數的模型組合。
在這兩個模型的GPU吞吐量的鼓舞下,研究人員最終使用表V中列出的分布策略組合訓練了一個萬億參數模型,并進行了十次迭代,以觀察其訓練性能。
對于22B參數模型,研究人員可以提取其峰值吞吐量(191.5 TFLOPS)的38.38%(73.5 TFLOPS)。
對于175B模型訓練,研究人員實現了峰值吞吐量的36.14% (69.2 TFLOPs)。
最后,對于1T模型,實現了峰值吞吐量的31.96%(61.2 TFLOPs)。
擴展性能
通過數據并行來維持模型并行訓練的性能,讓系統中的大量GPU參與進來,是一項極具挑戰性的任務。性能最強的GPU通過不同速度的通信鏈路連接,如果對網絡中較大的部分施加壓力,可能會導致性能損失。
因此,研究人員通過數據并行化將175B模型的訓練擴展到1024個GPU,將1T模型的訓練擴展到3072個GPU,以衡量訓練策略的擴展效率。
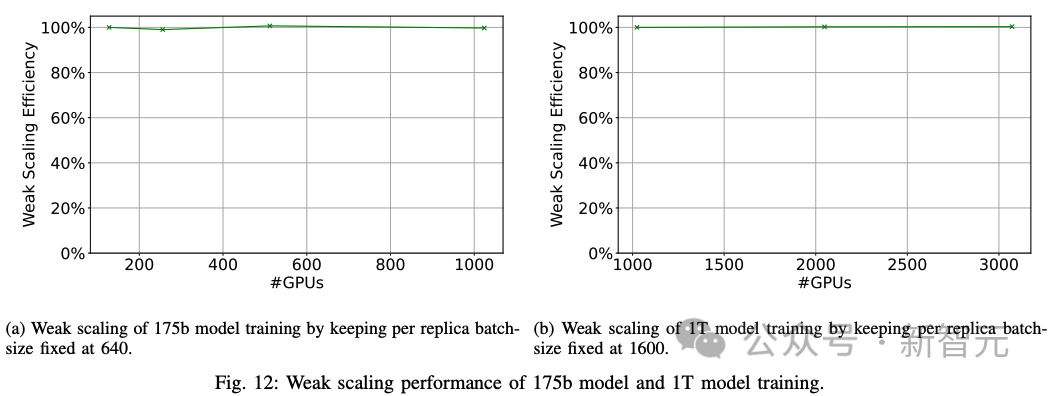
1. 弱擴展:研究人員在1024、2048和3072個GPU上使用全局批量大小3200、6400和9600執行數據并行訓練,對1T模型進行弱擴展實驗。數據并行訓練實現了100%的弱擴展效率(下圖12)。
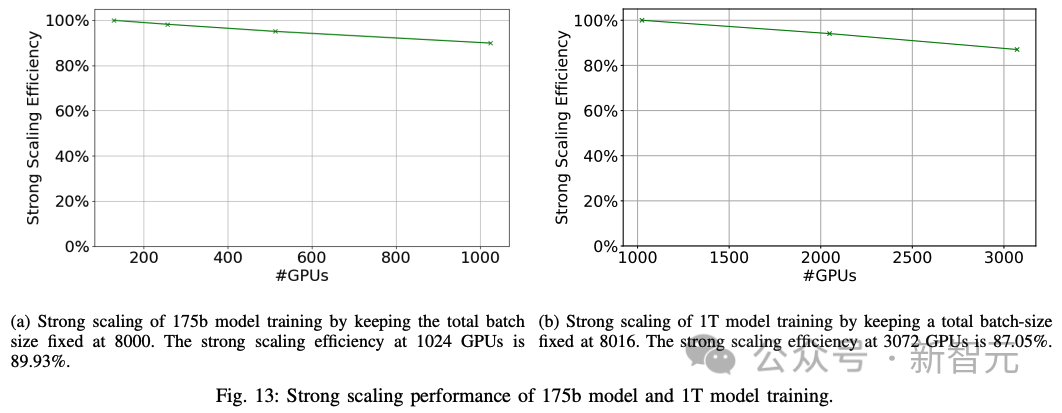
2. 強擴展:研究人員進行了強擴展實驗,將全局批量大小保持在8000,然后改變GPU的數量。研究人員在1024個GPU上對一個175B模型實現了89.93%的強擴展性能(圖13a)。研究人員在3072個GPU上對一個1萬億參數的模型實現了87.05%的強擴展性能(圖13b)。
世界最快超算
AMD加持的Frontier超級計算機現在是世界上第一臺官方認可的百億億次超級計算機,算力高達1.102 ExaFlop/s。
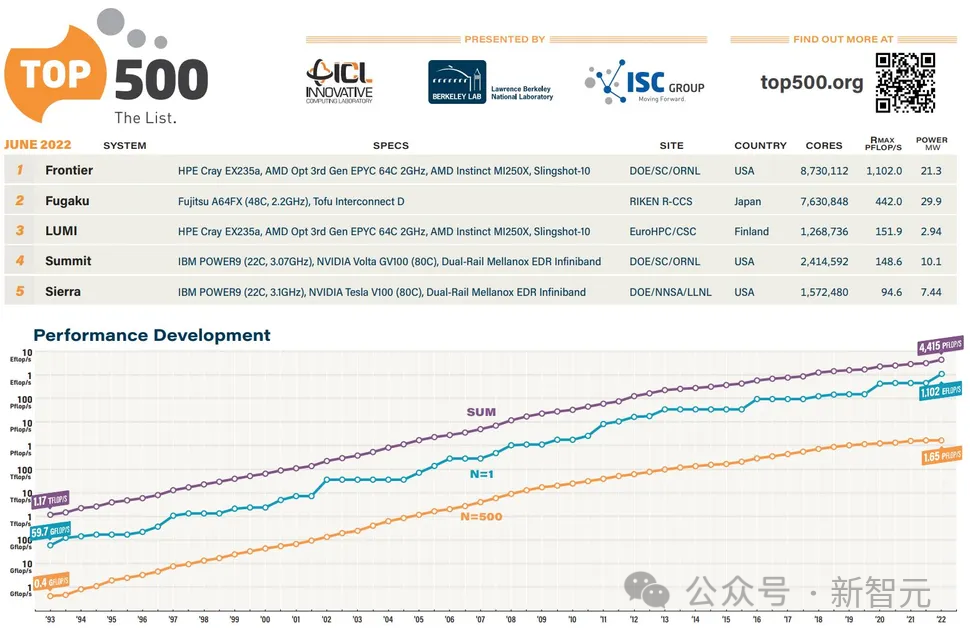
它在新發布的全球最快超級計算機Top500榜單中名列第一。
Frontier的速度比榜單上接下來的七臺超級計算機的總和還要快。
Frontier現在也被列為地球上最快的AI系統,在HPL-AI基準測試中提供6.88 ExaFlops的混合精度性能。
這相當于大腦中860億個神經元中的每一個每秒執行6800萬條指令。
Frontier超級計算機的規模之大令人驚嘆,但這只是AMD在今年Top500榜單中取得的眾多成就之一——全球排名前10的超級計算機中,有5臺采用AMD EPYC系統,而排名前20的超級計算機中,有10臺采用AMD EPYC系統。
Frontier超級計算機由HPE制造,安裝在橡樹嶺國家實驗室 (ORNL)。
該系統擁有9408個計算節點,每個節點配備一個64核AMD「Trento」CPU,搭配512 GB DDR4內存和四個AMD Radeon Instinct MI250X GPU。
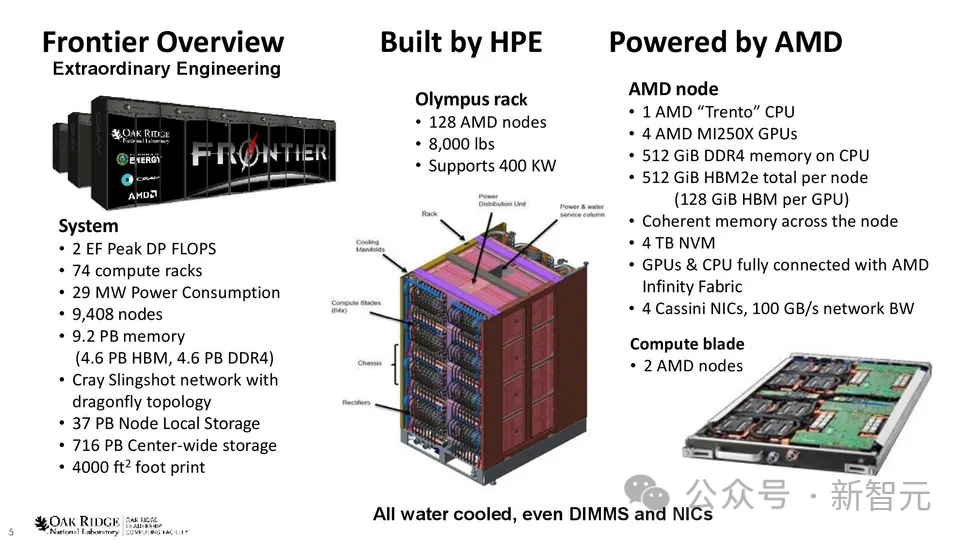
這些節點分布在74個HPE Cray EX機柜中,每個機柜重8000磅。整個系統擁有 602112個CPU核心,4.6 PB DDR4內存。























