













港科大譚平團隊突破3D生成領域關鍵性問題,讓多頭怪不再出現
生成模型在圖像生成領域取得了巨大的成功,但將這一技術擴展到 3D 領域一直面臨著重重挑戰。典型的多頭怪問題,即文本生成3D中多視角一致性問題,一直得不到很好的解決。譚平團隊最新的研究論文都致力于解決這一基礎問題,為這一領域帶來了突破和創新。
譚平博士是香港科技大學電子與計算機工程系教授。他曾經擔任阿里巴巴達摩院XR實驗室負責人,人工智能實驗室計算機視覺首席科學家。于近期創立公司光影煥像,依然專注在3D領域,將自己多年的研究成果進行轉化。
論文 "SweetDreamer" 采用3D數據對2D擴散模型進行Alignment,成功實現文本生成高質量3D模型的任務,解決幾何不一致問題。通過賦予 2D 模型視角感知能力和引入規范坐標映射(CCM),它有效地對齊了 3D 幾何結構,保留了多樣化高質量物體的生成能力,并在人類評估中取得了 85% 以上的一致性,遠超以往方法(僅 30% 左右),為文本到 3D 生成領域帶來了新的技術突破。

- 論文地址:https://arxiv.org/pdf/2310.02596.pdf
- 論文網站:https://sweetdreamer3d.github.io/
論文 "Ctrl-Room" 采用了兩階段生成方式,即 "布局生成階段" 和 "外觀生成階段",解決了文本生成 3D 室內場景的多視角不一致性問題。在布局生成階段,該方法生成了合理的室內布局,考慮到了家具類型和位置,以及墻壁、門窗等因素。而在外觀生成階段,它生成了全景圖像,確保了不同視角圖像之間的一致性,從而保證了 3D 房間結構和家具排列的合理性。"Ctrl-Room" 甚至允許用戶對生成的 3D 房間進行靈活編輯,包括調整家具大小、位置和語義類別等操作,以及替換或修改家具。

論文地址:https://arxiv.org/abs/2310.03602v1
論文網址:https://fangchuan.github.io/ctrl-room.github.io/
接下來,我們一起來看看這兩篇論文的關鍵內容。
SweetDreamer
譚平團隊和騰訊、華南理工共同合作的 SweetDreamer 重點解決文本生成 3D 物體中的多視角不一致性問題,通過改進 2D 擴散模型,成功將文本轉化為高質量的 3D 對象,實現了文本到 3D 生成的重大突破。
“SweetDreamer” 的核心貢獻在于解決了文本到 3D 生成中的多視圖不一致性問題。團隊指出,現有方法中的主要問題來自幾何不一致性,即在將 2D 結果提升到 3D 世界時,由于 2D 模型僅學習視角無關的先驗知識,導致多視圖不一致性問題。這種問題主要表現為幾何結構的錯位,而解決這些錯位結構可以顯著減輕生成結果中的問題。因此,研究團隊通過使 2D 擴散模型具備視角感知能力,并生成規范坐標映射(CCM),從而在提升過程中與 3D 幾何結構對齊,解決了這一問題。
論文中的方法只使用了粗略的 3D 信息,只需要少量的 3D 數據。這種方式不僅解決了幾何不一致性問題,還保留了 2D 擴散模型生成從未見過的多樣化高質量物體的能力。
最終,他們的方法在人類評估中取得了 85% 以上的一致性,遠超過以往的方法 30% 左右的結果,這意味著他們的方法在文本到 3D 生成領域實現了新的技術突破。這一研究不僅對于 3D 生成具有重要意義,還對于虛擬現實、游戲開發、影視制作領域等有著廣泛的應用前景,為實現更高質量、更多樣化的 3D 生成打開了新的可能性。
方法介紹
“SweetDreamer” 的核心目標是解決多視角不一致性的問題。這個問題主要可以從兩個角度來看:幾何不一致性問題,以及外觀不一致性問題。團隊通過研究發現,大多數 3D 不一致性問題的主要原因是幾何結構的錯位,因此這項技術的主要目標是通過改進 2D 先驗模型,使其能夠生成 3D 一致的幾何結構,同時保持模型的通用性。
為了實現這一目標,團隊提出了一種方法,即通過與 3D 數據集中的規范坐標映射(CCM)對齊的方式,確保 2D 擴散模型中的幾何先驗能夠正確生成 3D 一致的幾何結構。這項技術依賴 3D 數據集,并假設數據集中的模型都具有規范的方向和標準化的尺寸。然后,從隨機角度渲染深度圖,并將其轉換為規范坐標。需要注意的是,這個過程的目標是對齊幾何先驗,而不是生成幾何細節。
最后,通過對 2D 擴散模型進行微調,就能夠在指定的視角下生成規范坐標圖,從而對齊 2D 擴散模型中的幾何先驗。這些對齊的幾何先驗(AGP)可以輕松集成到各種文本到 3D 生成管道中,從而顯著減輕了不一致性問題,最終產生高質量和多樣化的 3D 內容。

“SweetDreamer” 的關鍵步驟如下:
- 規范坐標映射(CCM)。首先,為了簡化建模過程,研究人員假設在訓練數據中,同一類別的所有物體都遵循規范的方向。然后,他們將物體的大小歸一化,使得其包圍框的最大范圍長度為 1,并且位于原點的中心。此外,他們還對從物體渲染的坐標映射進行了各向異性縮放,以增強不同視角下薄結構的空間坐標差異,從而改善了對 3D 結構的感知。
- 相機信息注入。雖然規范坐標映射包含粗略的視角信息,但研究人員發現擴散模型難以有效利用它。因此,他們將相機信息注入模型以提高視角感知。這個步驟的目的是生成粗略的幾何結構,而不是準確的 3D 模型。
- 微調 2D 擴散模型。在獲得規范坐標映射和相應的相機參數之后,研究人員微調 2D 擴散模型,以在特定視角條件下生成規范坐標映射,最終對齊 2D 擴散模型中的幾何先驗。
這一技術不僅解決了多視角 3D 結構一致,并且保持了 2D 擴散模型的靈活性和豐富性,可以被集成到不同的渲染管線中。團隊在文中展示了兩種不同的渲染管線,分別是基于神經輻射場(NeRF)的 DreamFusion 和基于傳統三角網格的 Fantasia3D。

基于神經輻射場的管線:團隊對 3D 對象進行體素渲染,以獲取 RGB 圖像,并將其輸入到擴散模型以計算 SDS 損失。在優化期間,團隊渲染規范坐標映射(CCM),并將其輸入到對齊幾何先驗(AGP),以計算幾何 SDS 損失來更新 NeRF 的幾何分支。
基于傳統三角網格的管線:這里只需要添加一個額外的并行分支,將對齊幾何先驗(AGP)納入原始流程的幾何建模監督中。在優化的時候,團隊將對齊幾何先驗(AGP)在粗略和精細幾何建模階段都作為額外的監督引入,就可以輕松獲得高質量和視角一致的結果。
實驗結果呈現
通過將 AGP 集成到文本生成 3D 的網絡中,結果得到了顯著改善。原始的方法容易受到多視角不一致性的干擾,而生成多頭、多手等幾何結構錯亂的結果。團隊發現新的方法對結果有明顯的提升,生成的結果明顯具有高度的 3D 一致性。
團隊的定量評估著重于評估 3D 結果的多視角一致性。具體而言,團隊隨機選擇了 80 個文本提示,執行文本到 3D 合成,生成了每種方法的 80 個結果。然后手動檢查和統計 3D 不一致性(例如,多個頭、手或腿)的出現次數,并報告成功率,即 3D 一致對象的數量除以生成結果的總數。結果表明,SweetDreamer 在兩種渲染管線中的成功率都超過了 85%,而之前的方法只有大約 30%。

團隊認為,盡管同時期的工作 MVDream 也可以解決多視角不一致性問題,但它容易過擬合有限的 3D 數據,擴散模型的泛化性能受到影響。例如使用提示詞 “一張豬背著背包的圖像”,MVDream 會漏掉 “背包” 的存在。相比而言,AGP 的結果有更豐富的外觀,這是因為 AGP 僅對幾何建模產生影響,而不會影響由擴散模型從數十億真實圖像中學到的強大的外觀先驗。
Ctrl-Room
譚平團隊和南開大學共同合作的 Ctrl-Room 重點解決文本生成 3D 室內場景中的多視角不一致性問題,通過解耦布局和外觀,可以用文字提示實現逼真的 3D 室內場景生成,而且還可以對室內物品進行靈活編輯,包括調整大小和移動位置等操作。
"Ctrl-Room" 的核心貢獻在于方法采用了一種創新的兩階段生成方式,分別是 "布局生成階段" 和 "外觀生成階段"。在布局生成階段,該方法可以生成合理的室內布局,包括各種家具類型和位置,甚至考慮到了有門窗的墻壁。這一階段的關鍵是采用了一種全面的場景代碼參數化方法,將房間表示為一組對象,每個對象由一個向量表示,其中包括其位置、大小、語義類別和方向。
在外觀生成階段,該方法生成了室內場景的外觀,將其呈現為全景圖像。與以往的文本生成全景圖方法不同,這一方法明確遵循了室內布局約束,能夠確保各個不同視角圖像之間的一致性,確保了 3D 房間結構和家具排列的合理性。
最重要的是,由于布局與外觀分離的設計,"Ctrl-Room" 允許對生成的 3D 房間進行靈活編輯。用戶可以輕松地調整家具物品的大小、語義類別和位置。這一方法甚至允許用戶通過指令或鼠標點擊來替換或修改家具,而無需昂貴的特定于編輯的訓練。
方法介紹
這項技術分為兩個關鍵階段:布局生成階段和外觀生成階段。在布局生成階段,團隊通過一種全面的場景代碼來描述室內場景,并利用擴散模型學習其分布。這樣就可以從文字輸入中生成房間的整體結構,包括墻壁和各種物品的位置和大小。用戶可以隨心所欲地編輯這些物品,拖拽它們、調整它們的類型、位置或大小,以滿足用戶的個性化需求。
在外觀生成階段,團隊通過一個經過預訓練的擴散模型生成室內場景的紋理,將室內布局轉化為全景圖。為了確保圖像的左右連貫,團隊提出了一種新的循環一致性采樣方法,使室內場景看起來更加真實。最終,通過估算生成的全景圖的深度圖來獲得帶紋理貼圖的 3D 場景。

“Ctrl-Room” 的關鍵步驟如下:
1. 布局生成階段
這個階段的主要目標是從文本輸入中創建室內三維場景的布局。與以往方法不同,團隊不僅僅考慮了家具,還包括了墻壁、門和窗戶等要素,以更全面地定義室內場景的布局。
團隊將室內場景中的各個元素編碼成一種統一的格式,并將其稱為 “場景代碼”。這個代碼包含了室內場景中所有元素的信息,包括它們的位置、尺寸、朝向和類別。然后團隊利用這個場景代碼來構建一個擴散模型,用于學習場景布局的分布。
這個模型通過逐漸向場景代碼添加高斯噪聲來創建一個離散時間的馬爾可夫鏈。噪聲逐漸增加,直到最終的分布呈現高斯分布。然后,通過訓練神經網絡來反向這個過程,從添加了噪聲的場景代碼中還原出干凈的場景代碼。這個過程能夠將文本輸入轉化為具體的場景布局,為后續的場景生成和編輯提供了基礎。
在布局生成階段的末尾,場景代碼被表示為一組不同語義類型的包圍盒,這些包圍盒將用于后續的交互式編輯,允許用戶根據自己的需求自定義 3D 場景。
2. 外觀生成階段
這個階段旨在根據室內場景的布局信息生成合適的全景圖像,以表現其外觀。過去有的方法采用增量式的方式,逐步生成不同視角的圖像來合成全景圖,但容易受到多視角不一致性的影響,導致最終的全景圖不能保持合理的房間結構。這里團隊利用了 ControlNet 技術,根據布局的結果一次性生成整個全景圖,可以更好保持房間結構。
為了實現這一點,團隊將包圍盒表示的布局轉換成了語義分割全景圖。然后,研究團隊對 ControlNet 進行了微調,使用了結構化 3D 數據集來增強訓練數據。團隊還引入了 "循環一致采樣" 的概念,以確保生成的全景圖在左右兩側無縫連接。
3.交互編輯
這個模塊允許用戶通過更改物體包圍盒的位置、語義類別和大小來修改生成的三維室內場景。這一編輯過程需要實現兩個目標,即根據用戶的輸入改變內容,并保持未編輯部分的外觀一致性。
這個編輯過程分為兩個步驟,填充步驟和優化步驟。填充步驟是為了將物體移動后露出部分進行填充。而優化步驟是為了保持被移動過的家具、物品的外觀一致性。
實驗結果呈現
研究人員使用了包含 3,500 個由專業藝術家設計的房屋的 3D 室內場景數據集 Structured3D 對模型進行評估。為了評估方法,研究人員選取了 4,961 個臥室和 3,039 個客廳,其中 80% 用于訓練,其余用于測試。
相比以往的算法,例如 Text2Room 和 MVDiffusion,Ctrl-Room 能夠更好保持房間結構。而 Text2Room 和 MVDiffusion 往往在不同視角的圖像中反復生成同一個物體,例如在客廳中多次重復壁爐、電視機,在臥室中多次重復床等顯著性高的物體。因此這些方法生成的場景往往從全局結構上看非常混亂。而 Ctrl-Room 通過顯示的引入房間布局的生成,并用布局引導最終室內場景的生成,可以非常好的解決這個問題。

為了衡量生成的全景圖像的質量,團隊使用了 Frechet Inception Distance (FID)、CLIP Score (CS) 和 Inception Score (IS) 等指標。此外,研究人員還比較了生成 RGB 全景圖像的時間成本,以及生成的 3D 室內場景的質量,包括 CLIP Score (CS) 和 Inception Score (IS)。
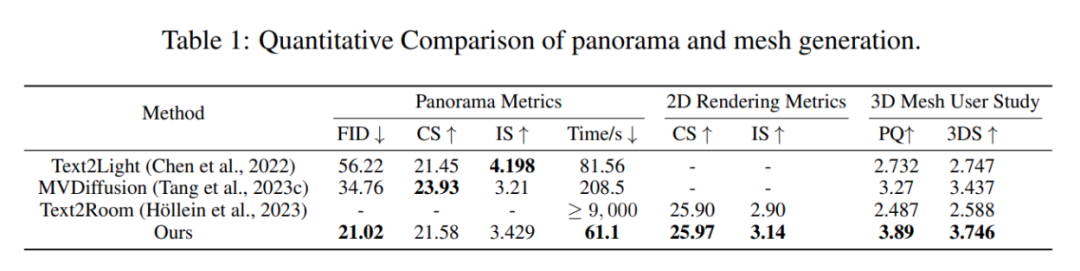
Ctrl-Room 在生成全景圖像方面表現出色。它在 FID 指標上取得了最佳成績,并大幅領先其他對比方法,這意味著它能更好地捕捉房間的外觀,因為它能忠實地恢復房間布局。而 CS 指標對房間內物體的數目并不敏感,即便一個臥室中生成了 3-4 張床 CS 指標也可以很高,因此不能準確評價場景生成。與此同時,Ctrl-Room 在生成時間方面表現出色,相對于其他方法,它需要更短的時間。
團隊還進行了用戶研究,詢問了 61 名用戶對最終室內場景的感知質量和 3D 結構完整性進行評分。Ctrl-Room 技術也被用戶認為在房間布局結構和家具排列方面具有更清晰的優勢。

























