DeepMind讓大模型學會歸納和演繹,GPT-4準確率提升13.7%
當前,大型語言模型(LLM)在推理任務上表現出令人驚艷的能力,特別是在給出一些樣例和中間步驟時。然而,prompt 方法往往依賴于 LLM 中的隱性知識,當隱性知識存在錯誤或者與任務不一致時,LLM 就會給出錯誤的回答。

現在,來自谷歌、Mila 研究所等研究機構的研究者聯合探索了一種新方法 —— 讓 LLM 學習推理規則,并提出一種名為假設到理論(Hypotheses-to-Theories,HtT)的新框架。這種新方法不僅改進了多步推理,還具有可解釋、可遷移等優勢。

論文地址:https://arxiv.org/abs/2310.07064
對數值推理和關系推理問題的實驗表明,HtT 改進了現有的 prompt 方法,準確率提升了 11-27%。學到的規則也可以遷移到不同的模型或同一問題的不同形式。
方法簡介
總的來說,HtT 框架包含兩個階段 —— 歸納階段和演繹階段,類似于傳統機器學習中的訓練和測試。
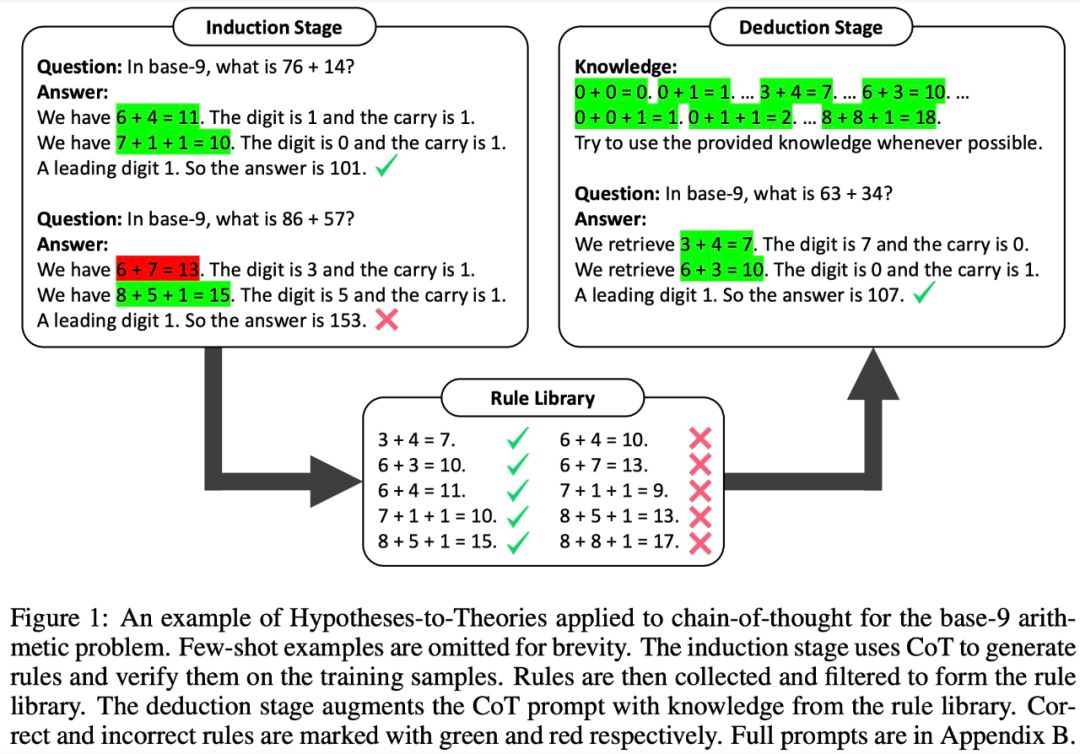
在歸納階段,LLM 首先被要求生成并驗證一組訓練樣例的規則。該研究使用 CoT 來聲明規則并推導答案,判斷規則的出現頻率和準確性,收集經常出現并導致正確答案的規則來形成規則庫。
有了良好的規則庫,下一步該研究如何應用這些規則來解決問題。為此,在演繹階段,該研究在 prompt 中添加規則庫,并要求 LLM 從規則庫中檢索規則來進行演繹,將隱式推理轉換為顯式推理。
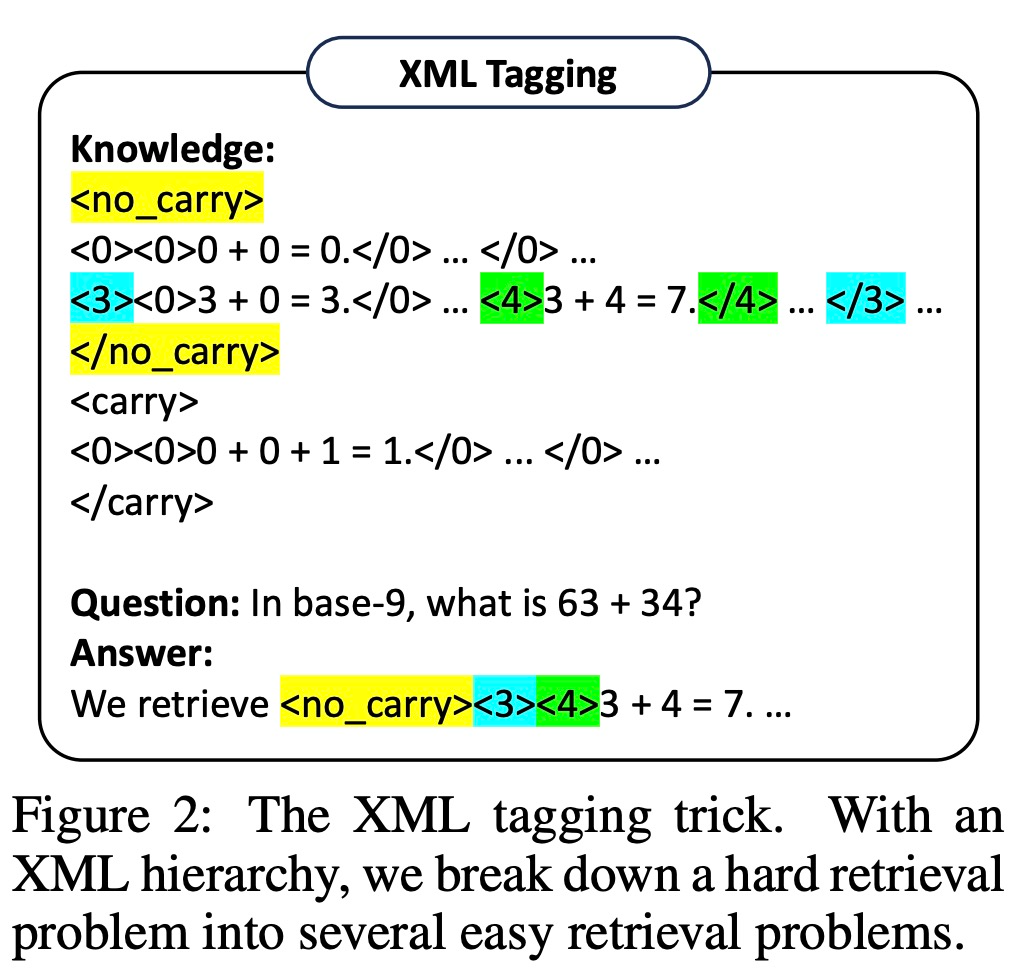
然而,該研究發現,即使是非常強大的 LLM(例如 GPT-4)也很難在每一步都檢索到正確的規則。為此,該研究開發了 XML tagging trick,來增強 LLM 的上下文檢索能力。
實驗結果
為了評估 HtT,該研究針對兩個多步驟推理問題進行了基準測試。實驗結果表明,HtT 改進了少樣本 prompt 方法。作者還進行了廣泛的消融研究,以提供對 HtT 更全面的了解。
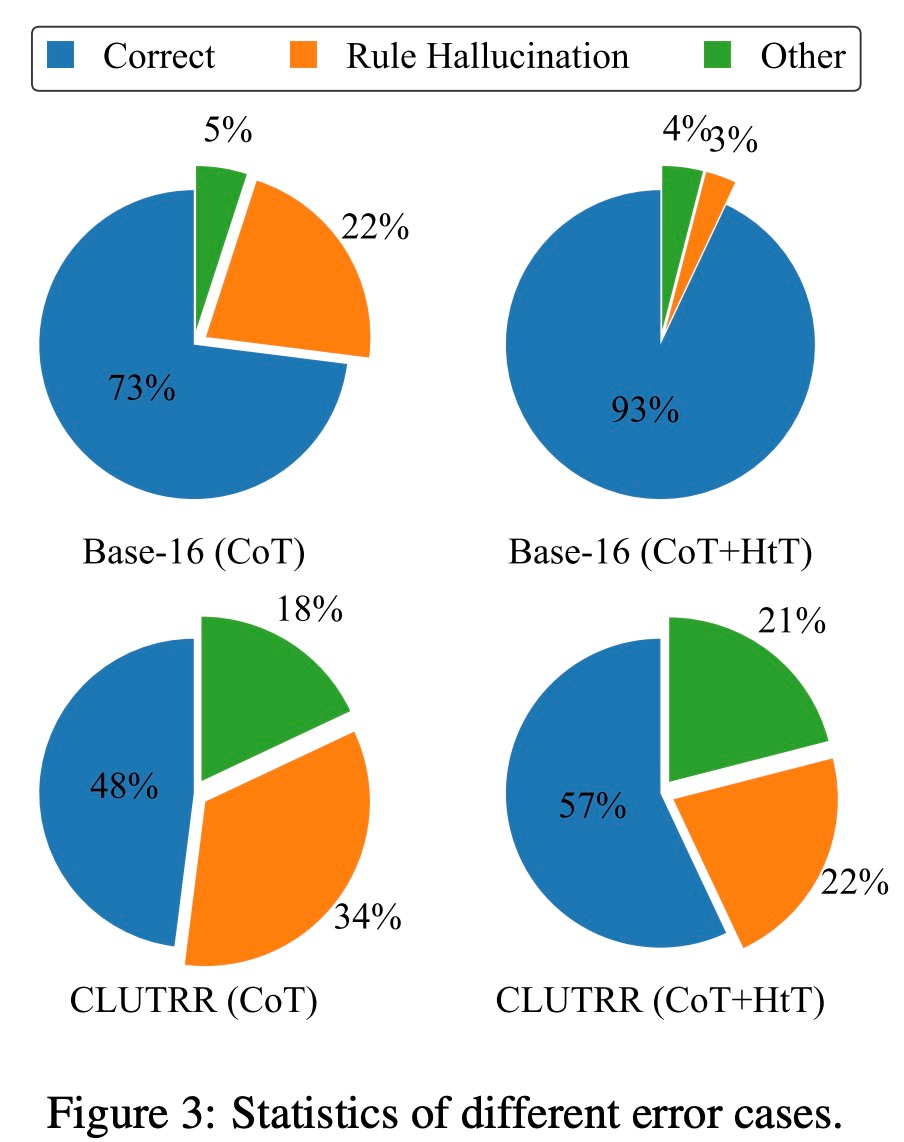
他們在數值推理和關系推理問題上評估新方法。在數值推理中,他們觀察到 GPT-4 的準確率提高了 21.0%。在關系推理中,GPT-4 的準確性提高了 13.7%,GPT-3.5 則獲益更多,性能提高了一倍。性能增益主要來自于規則幻覺的減少。
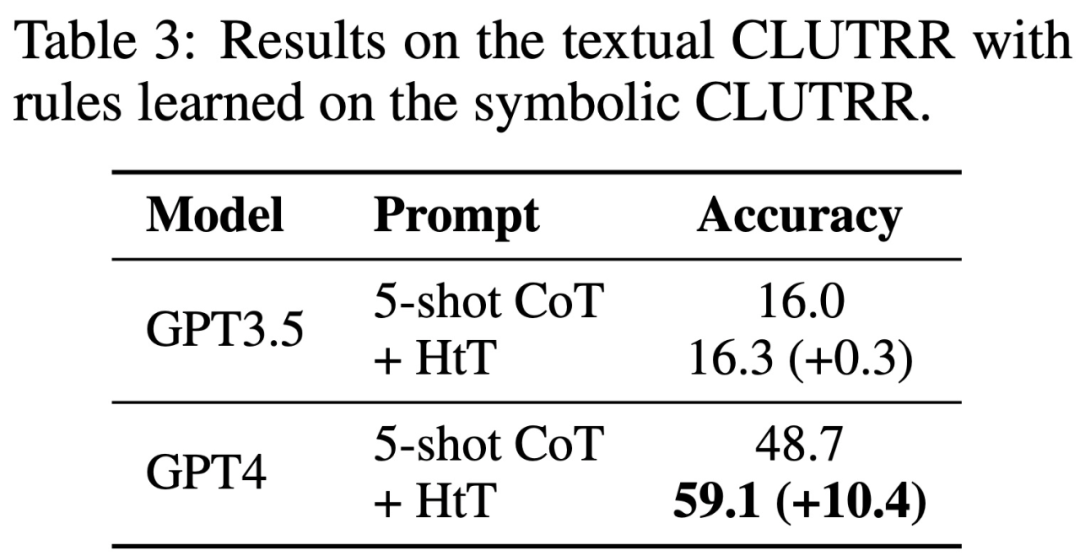
具體來說,下表 1 顯示了在算術的 base-16、base-11 和 base-9 數據集上的結果。在所有 base 系統中,0-shot CoT 在兩個 LLM 中的性能都最差。
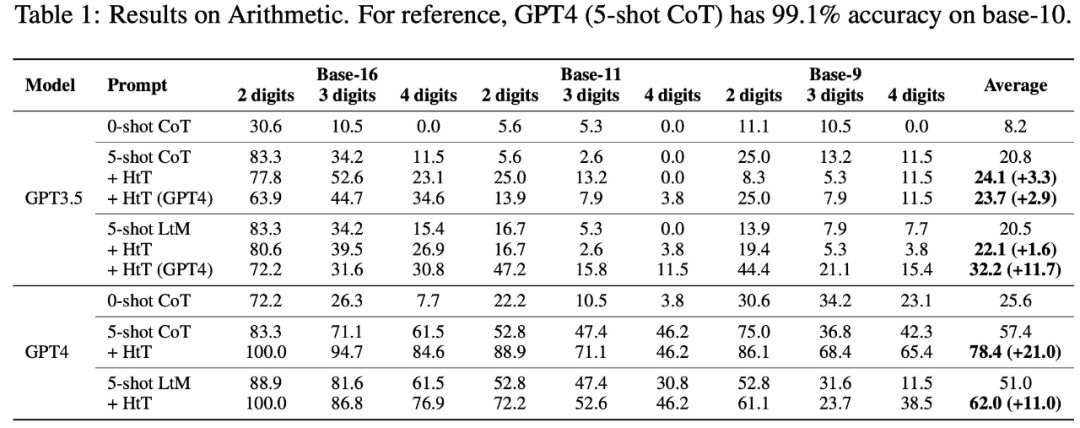
表 2 呈現了在 CLUTRR 上比較不同方法的結果。可以觀察到,在 GPT3.5 和 GPT4 中,0-shot CoT 的性能最差。對于 few-shot 提示方法,CoT 和 LtM 的性能相似。在平均準確率方面,HtT 始終比兩種模型的提示方法高出 11.1-27.2%。值得注意的是,GPT3.5 在檢索 CLUTRR 規則方面并不差,而且比 GPT4 從 HtT 中獲益更多,這可能是因為 CLUTRR 中的規則比算術中的規則少。
值得一提的是,使用 GPT4 的規則,GPT3.5 上的 CoT 性能提高了 27.2%,是 CoT 性能的兩倍多,接近 GPT4 上的 CoT 性能。因此,作者認為 HtT 可以作為從強 LLM 到弱 LLM 的一種新的知識蒸餾形式。
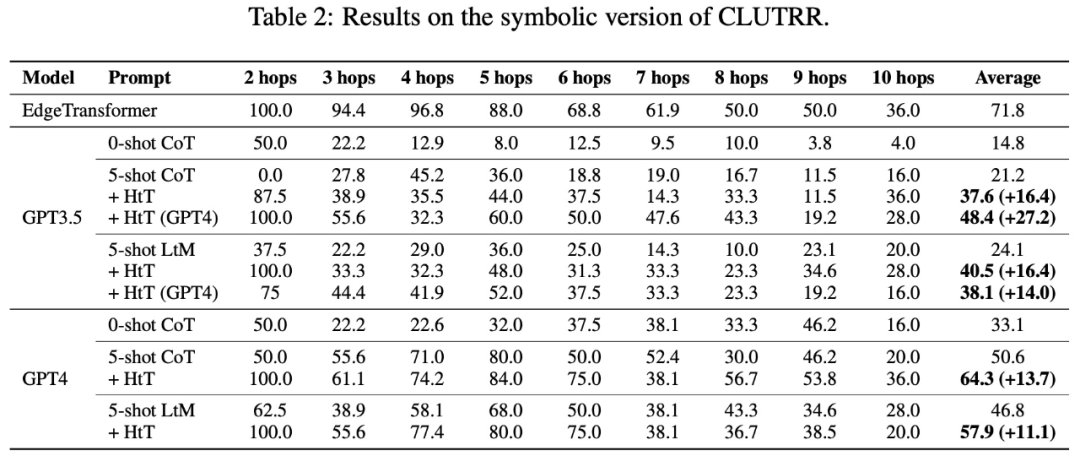
表 3 顯示,HtT 顯著提高了 GPT-4(文本版)的性能。對于 GPT3.5 來說,這種改進并不顯著,因為在處理文本輸入時,它經常產生除規則幻覺以外的錯誤。