













GPT-4正接管人類數據專家!先驗知識讓LLM大膽預測,準確率堪比傳統方式
在數據科學中,AI研究員經常面臨處理不完整數據集的挑戰。
然而,許多已有的算法根本無法處理「不完整」的數據序列。
傳統上,數據科學家會求助于專家,利用他們的專業知識來填補空白,然而這一過程既耗時,卻又不實用。
如果AI可以接管專家的角色,又會如何呢?
近日,來自德國人工智能中心、大阪公立大學等團隊的研究人員,調查了LLM能否足以充當數字專家。
畢竟,當前大模型都在大量文本的基礎上進行了訓練,可能對醫學數據、社會科學等不同主題的問題有著深刻的理解。

論文地址:https://arxiv.org/pdf/2402.07770.pdf
研究人員通過將LLM的答案與實際數據進行比較,并建立了處理數據差距的統計方法。
結果表明,在許多情況下,LLM可以在不依賴人類專家的情況下,提供與傳統方法類似的準確估計。
用LLM進行「數據插補」
在分析數據時,無論是醫學、經濟學還是環境研究,經常會遇到信息不完整的問題。
這就需要用到兩種關鍵技術:先驗啟發(確定先驗知識)和數據插補(補充缺失數據)。
先驗啟發是指,系統地收集現有的專家知識,以對模型中的某些參數做出假設。
另一方面,當我們的數據集中缺少信息時,數據插補就開始發揮作用。
科學家們不會因為一些缺失而放棄有價值的數據集,而是使用統計方法用看似合理的值來填補。
研究中,主要采用的數據集為OpenML-CC18 Curated Classification Benchmark,其中包括72個分類數據集,涵蓋從信用評級到醫藥和營銷等各個領域。
這種多樣性確保了實驗涵蓋了廣泛的現實世界場景,并為LLM在不同環境下的性能提供了相關見解。
值得一提的是,最新方法中最關鍵的一個步驟便是——人為在數據集中生成缺失值,以模擬數據點不完整的情況。
研究人員用隨機缺失(MAR)模式從完整條目中生成這種缺失數據,以便與基本事實進行比較。
他們首先從OpenML描述中,為每個數據集生成一個適當的專家角色,然后使用它來初始化LLM,以便可以查詢它是否缺少值。
使用LLM進行插值,包括LLaMA 2 13B Chat、LLaMA 2 70B Chat、Mistral 7B Instruct,以及Mixtral 8x7B Instruct,每一種都進行了單獨的評估。
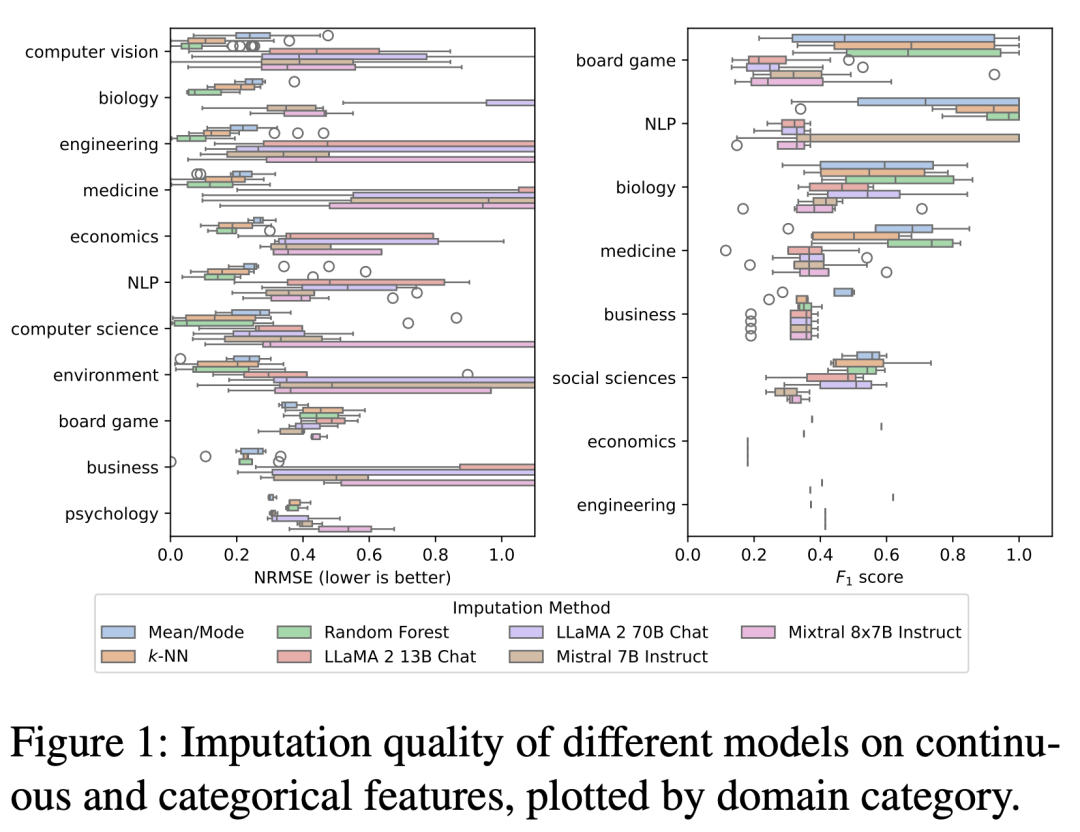
將這些模型與這類分析中常用的3種經驗方法進行了比較:分別用于連續特征和分類特征的平均值和模式估算、k-近鄰(k-NN)估算和隨機森林估算。
歸因質量的評估基于,連續特征和分類特征的歸一化均方根誤差(NRMSE)和F1分數。
通過這一方法,能夠讓研究人員可以調查LLM作為數據推算專家的能力,而且還可以將其表現與傳統方法進行比較。
這種創新的方法在處理不完整的數據集方面開辟了新的視角,并突出了LLM在數據科學中的潛力。
與傳統方法比較
與預期相反,分析結果表明,LLM的估算質量一般不會超過三種經驗方法。
然而,基于LLM的插補對于某些數據集是有用的,特別是在工程和計算機視覺領域。
一些數據集,如這些領域的「PC1」、「PC3」和「Satimage」,表現出NRMSE約為0.1的歸因質量,在生物學和NLP領域也觀察到了類似的結果。
有趣的是,基于LLM歸因的下游表現因領域而異。
雖然社會科學和心理學等領域表現較差,但醫學、經濟學、商業和生物學表現較好。值得注意的是,基于LLM的插補在商業領域表現最好。
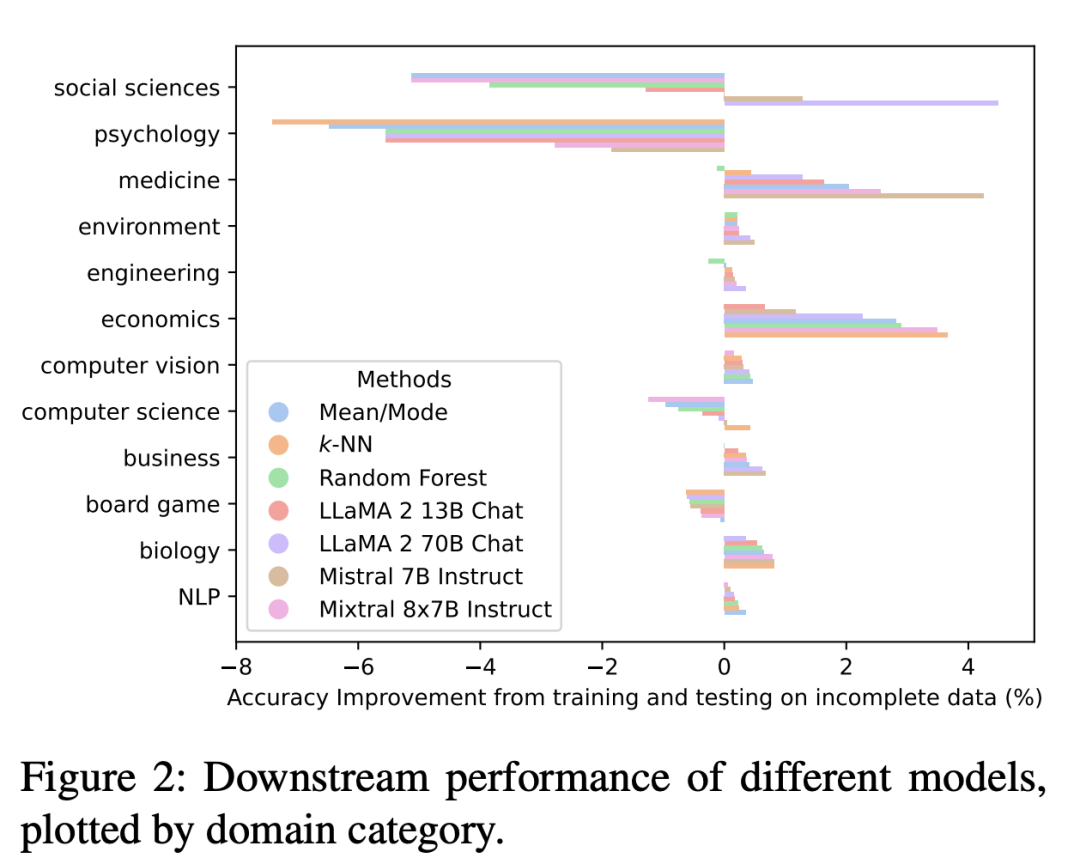
此外,研究還表明,至少在某些領域,LLM可以基于其豐富的訓練數據提供準確和相關的估計,這些數據可以與真實世界的數據相匹配。
使用LLM進行數據插補是有前景的,但它需要仔細考慮領域和特定用例。
因此,這項研究結果有助于更好地理解LLM在數據科學中的潛力和局限性。
用LLM先驗啟發
此外,研究人員還利用LLM研究了先驗啟發,旨在評估LLM能否提供有關特征分布的信息,以及這對數據收集和后續數據分析有何影響。
特別是,進一步了解LLM所獲得的先驗分布的影響和有效性,并比較它們與傳統方法和模型的性能如何。
作者將LLM的估計值與Stefan等人的實驗結果進行了比較。
在該實驗中,6位心理學研究人員被問及各自領域中典型的中小效應量和皮爾遜相關性。
使用類似的問題,要求LLM模擬一個專家、一組專家或一個非專家,然后查詢優先級分布。
在進行這項工作時,可以參考或不參考對比實驗中使用的訪談方案。
這里研究人員提出一種全新的提示策略,要求模型為貝葉斯數據分析提供專家知情的先驗分布。

在此過程中,ChatGPT 3.5展示了其對學術啟發框架的熟悉程度,比如謝菲爾德啟發框架與直方圖方法相結合。
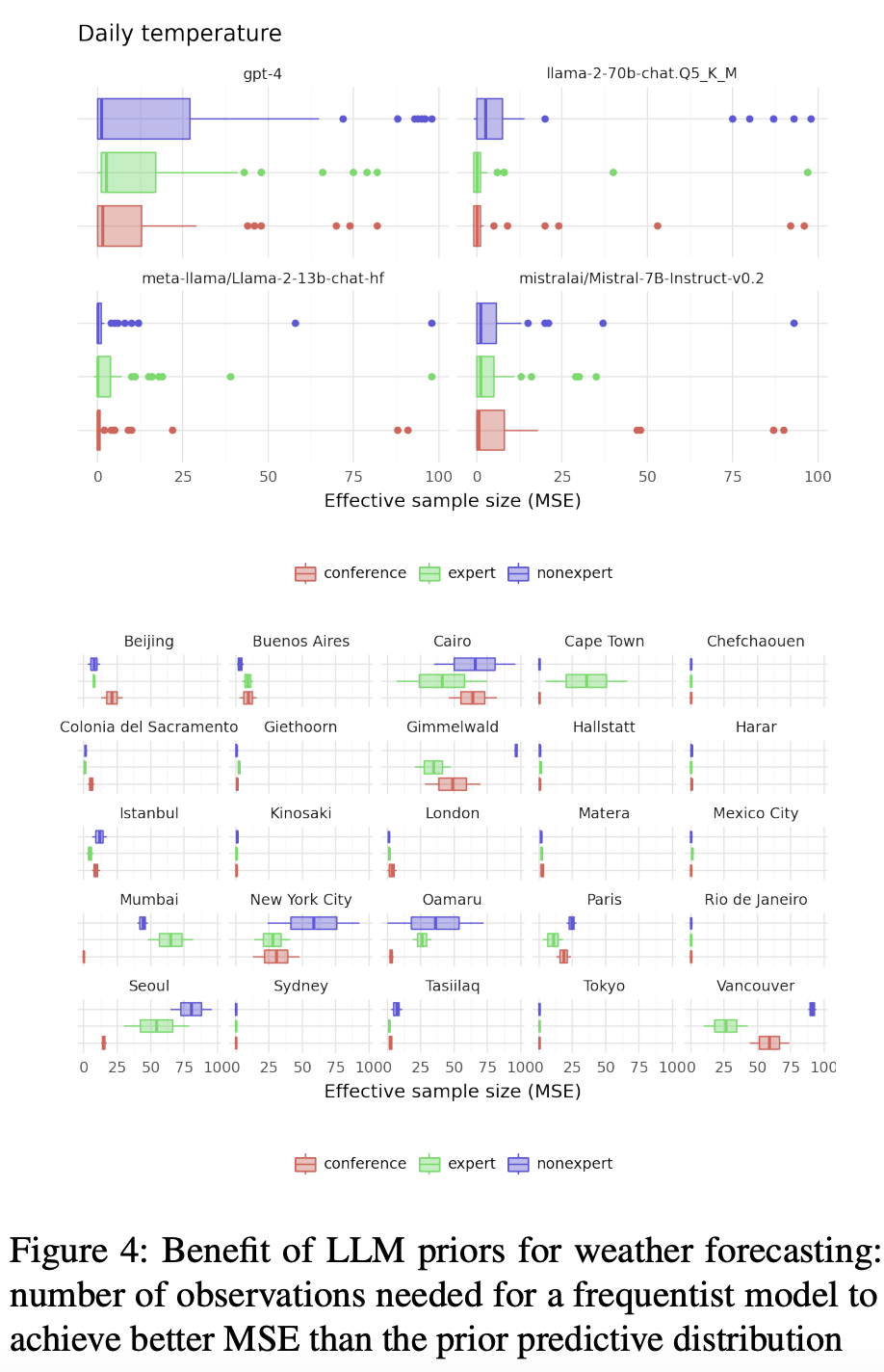
研究人員使用該框架生成了全球25個大小城市12月份典型日氣溫和降水量的先驗分布。
ChatGPT使用從訓練數據中獲得的知識進行模擬專家討論,并構建參數概率分布。
實驗結果
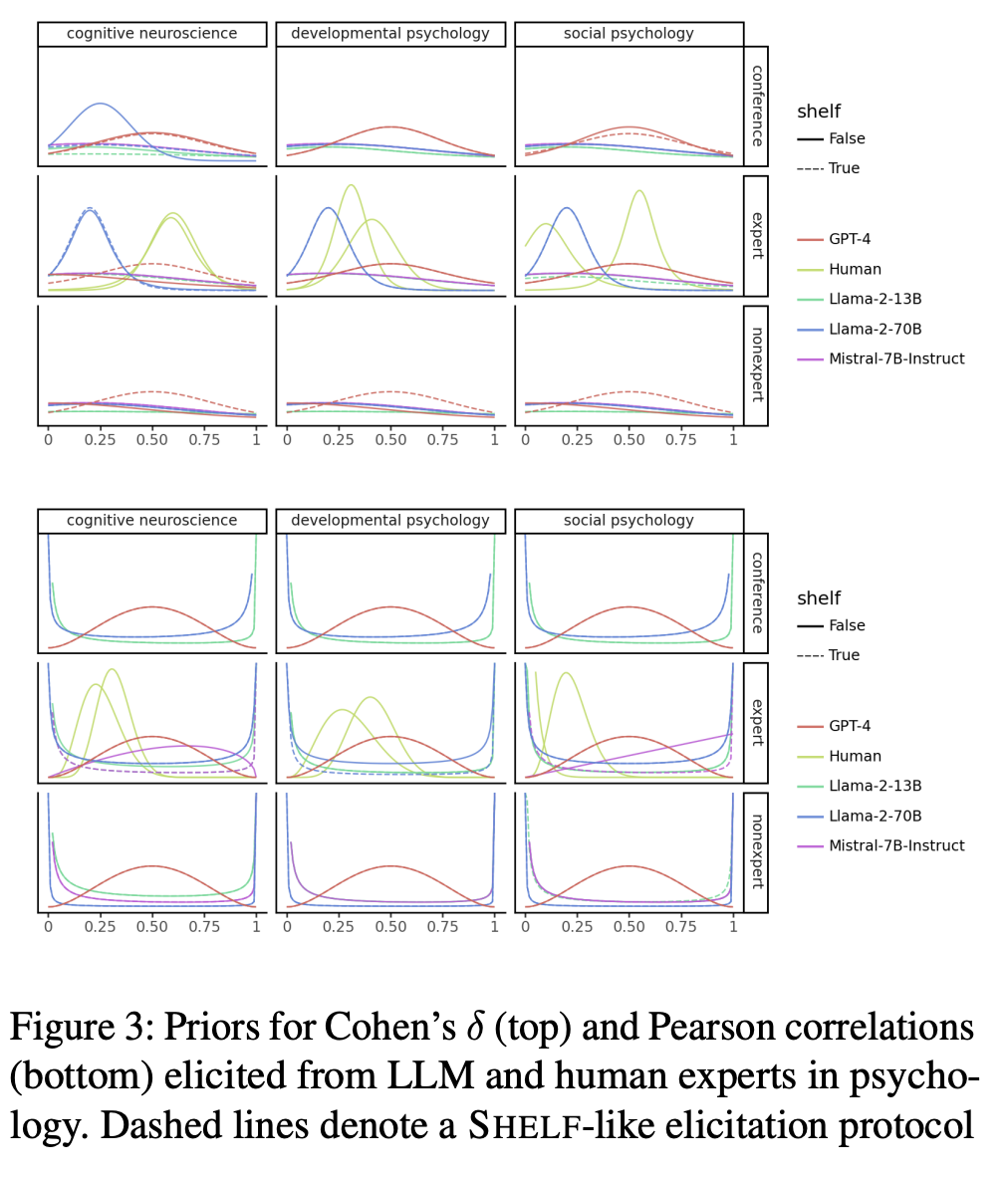
令人驚訝的是,不同子領域的專家角色對LLM產生的先驗沒有顯著影響。
在實驗中,無論他們扮演什么角色,他們的判斷都非常相似:
大多數人工專家都傾向于謹慎預測,認為影響較小。只有GPT-4專家比較大膽,認為影響中等偏大。
當涉及到兩個事物之間的關系時,比如天氣對我們購物行為的影響,數字助理們與真人的觀點有所不同。
有些數字助理呈現出一條中間低、邊緣高的「浴缸」曲線,而GPT-4則向我們展示了一條更平滑的鐘形曲線。
然后,作者還觀察了這些數字專家對他們的預測的信心。一些人相當謹慎,提供了保守的估計,除了Mistral 7B Instruct——對其估計的質量非常有信心。
綜上所述,這些結果還表明,LLM在某些方面能夠產生與人類專家判斷競爭的先驗,但在其他方面卻顯著不同。
結論
這項研究表明,在醫學、經濟和生物等領域,LLM已經可以基于傳統的數據插補的方法,提供有價值的見解。
LLM能夠綜合來自各種來源的知識,并將其應用于特定的應用環境,為數據分析開辟了新的視野。
特別是在專家難覓,或時間寶貴的情況下,LLM可以成為寶貴的資源。





























