













OpenAI科學(xué)家最新大語(yǔ)言模型演講火了,洞見LLM成功的關(guān)鍵
近日,OpenAI 研究科學(xué)家 Hyung Won Chung 在首爾國(guó)立大學(xué)做了題為「Large Language Models (in 2023)」的演講。他在自己的 YouTube 頻道上寫到:「這是一次雄心勃勃的嘗試,旨在總結(jié)我們這個(gè)爆炸性的領(lǐng)域。」
視頻地址:https://www.youtube.com/watch?v=dbo3kNKPaUA
在這次演講中,他談到了大型語(yǔ)言模型的涌現(xiàn)現(xiàn)象以及大模型的訓(xùn)練和學(xué)習(xí)過(guò)程,其中包括預(yù)訓(xùn)練和后訓(xùn)練階段,最后他還展望了一下未來(lái),認(rèn)為下一次范式轉(zhuǎn)變是實(shí)現(xiàn)可學(xué)習(xí)的損失函數(shù)。
在深入這次演講的具體內(nèi)容之前,我們先簡(jiǎn)單認(rèn)識(shí)一下這位演講者。

Hyung Won Chung 是一位專攻大型語(yǔ)言模型的研究者,博士畢業(yè)于麻省理工學(xué)院,之后曾在谷歌大腦工作過(guò)三年多時(shí)間,于今年二月份加入 OpenAI。
他曾參與過(guò)一些重要項(xiàng)目的研究工作,比如 5400 億參數(shù)的大型語(yǔ)言模型 PaLM 和 1760 億參數(shù)的開放式多語(yǔ)言語(yǔ)言模型 BLOOM(arXiv:2211.05100)。機(jī)器之心也曾介紹過(guò)他為一作的論文《Scaling Instruction-Finetuned Language Models》。
下面進(jìn)入演講內(nèi)容。
演講開篇,Chung 便指出,現(xiàn)在所謂的大型語(yǔ)言模型(LLM)在幾年后就會(huì)被認(rèn)為是小模型。隨著人們對(duì)模型規(guī)模(scale)的認(rèn)知的變化,目前有關(guān) LLM 的許多見解、觀察和結(jié)論都會(huì)變得過(guò)時(shí)甚至可能被證明是錯(cuò)誤的。
但他也指出,幸運(yùn)的是,那些基于第一性原理(First Principle)的見解卻會(huì)有相對(duì)更長(zhǎng)的生命力,因?yàn)樗鼈儽饶切┛此平k麗多彩的先進(jìn)思想更為基礎(chǔ)。
Chung 的這次演講聚焦的正是這些更為基礎(chǔ)的思想,他希望這些內(nèi)容在未來(lái)幾年內(nèi)依然具有參考價(jià)值。
大模型的涌現(xiàn)現(xiàn)象

大型語(yǔ)言模型有一個(gè)有趣的現(xiàn)象:只有當(dāng)模型達(dá)到一定規(guī)模時(shí),某些能力才會(huì)顯現(xiàn)。
如下圖所示,很多模型在規(guī)模達(dá)到一定程度時(shí),在準(zhǔn)確度等某些性能指標(biāo)上會(huì)出現(xiàn)急劇的變化,甚至模型會(huì)突然有能力解決在規(guī)模較小時(shí)完全無(wú)法解決的問(wèn)題。這種現(xiàn)象被稱為涌現(xiàn)(emergence)。
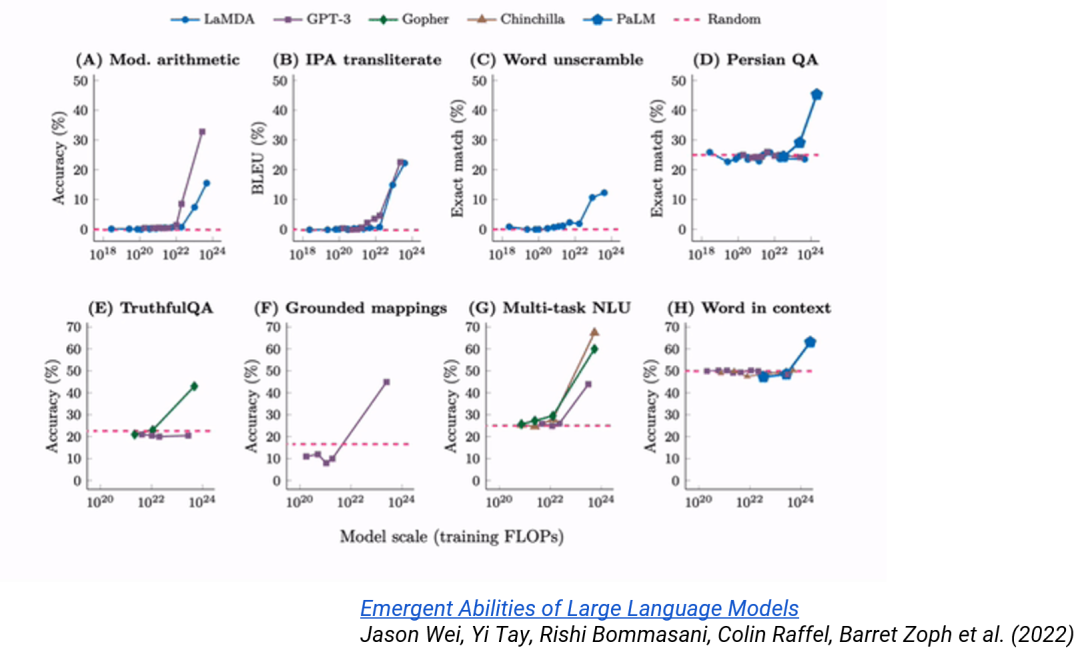
這個(gè)有趣現(xiàn)象給 AI 研究帶來(lái)了很多重要的新視角。
Chung 首先提到的視角是「yet」,也就是說(shuō)就算某個(gè)想法或能力目前無(wú)法實(shí)現(xiàn),但隨著規(guī)模擴(kuò)展,也許后面會(huì)突然能夠?qū)崿F(xiàn)。

這一視角轉(zhuǎn)變可能看似簡(jiǎn)單,卻涉及到我們對(duì)語(yǔ)言模型的根本看法。一項(xiàng)對(duì)當(dāng)前模型無(wú)用的技術(shù)也許三五年后就能變得有用,因此我們不應(yīng)對(duì)當(dāng)前的各種事物抱有永恒不變的觀念。
他指出,「yet」視角之所以并不是顯而易見的,是因?yàn)槲覀兞?xí)慣了在一個(gè)基礎(chǔ)公理不變的環(huán)境中工作。就像在進(jìn)行自然科學(xué)實(shí)驗(yàn)時(shí),如果你已經(jīng)通過(guò)實(shí)驗(yàn)發(fā)現(xiàn)某個(gè)科學(xué)思想不對(duì),那么你必定相信如果三年后再實(shí)驗(yàn)一次,這個(gè)思想還是不可能變正確;而且就算再過(guò)三十年,結(jié)果依然如此。

那么語(yǔ)言模型領(lǐng)域是否也存在類似于這類公理的概念呢?
Chung 認(rèn)為可以把一定時(shí)段內(nèi)最強(qiáng)大的模型視為這種「公理」,因?yàn)樵谶@段時(shí)間里,很多研究實(shí)驗(yàn)都是基于該模型進(jìn)行的。但有趣的地方在于:最強(qiáng)大的模型會(huì)變化。
舉個(gè)例子,在 GPT-4 誕生時(shí),它是最強(qiáng)大的,研究者基于其進(jìn)行了大量實(shí)驗(yàn),得到了許多研究成果和見解。但當(dāng)新的更強(qiáng)大模型出現(xiàn)時(shí),之前發(fā)現(xiàn)的一些見解和想法就過(guò)時(shí)了,甚至出現(xiàn)了許多新舊實(shí)驗(yàn)結(jié)果相矛盾的情況。
這就需要我們持續(xù)刷新已知的知識(shí)和觀念,Chung 使用了「unlearn」一詞,也就是說(shuō)要刻意地去忘記已經(jīng)不可行的思路。

Chung 表示目前還很少有人這樣實(shí)踐。而在競(jìng)爭(zhēng)激烈的 AI 領(lǐng)域,很多只有一兩年經(jīng)驗(yàn)的新人卻能提出有重大意義的思想,Chung 認(rèn)為其中一部分原因就是這些新人會(huì)去嘗試之前有經(jīng)驗(yàn)的人嘗試過(guò)的無(wú)效想法 —— 但這些想法卻能有效地用于當(dāng)前的模型。
因此,Chung 呼吁研究者要走在規(guī)模擴(kuò)展曲線之前。

他分享說(shuō)自己在進(jìn)行文檔實(shí)驗(yàn)時(shí)發(fā)現(xiàn)有些實(shí)驗(yàn)會(huì)因?yàn)槟P汀钢橇Σ蛔恪苟。簿褪钦f(shuō)模型沒(méi)有足夠的推理能力來(lái)解決一些困難的數(shù)學(xué)或編程問(wèn)題。他會(huì)將這些失敗實(shí)驗(yàn)記錄下來(lái),但并不會(huì)斷言這些實(shí)驗(yàn)就徹底失敗了,而是會(huì)進(jìn)行一些處理,使得未來(lái)能輕松地重新運(yùn)行這些實(shí)驗(yàn)。每當(dāng)有更好的新模型出現(xiàn)時(shí),他就會(huì)重新運(yùn)行這些實(shí)驗(yàn),觀察其中哪些實(shí)驗(yàn)會(huì)成功,哪些會(huì)繼續(xù)失敗。通過(guò)這種方式,他可以 unlearn 一些東西,不斷更新自己的認(rèn)知和理解,讓自己適應(yīng)模型隨規(guī)模擴(kuò)展的涌現(xiàn)現(xiàn)象。
接下來(lái),Chung 以一種簡(jiǎn)單直觀的方式對(duì)涌現(xiàn)現(xiàn)象進(jìn)行了說(shuō)明。
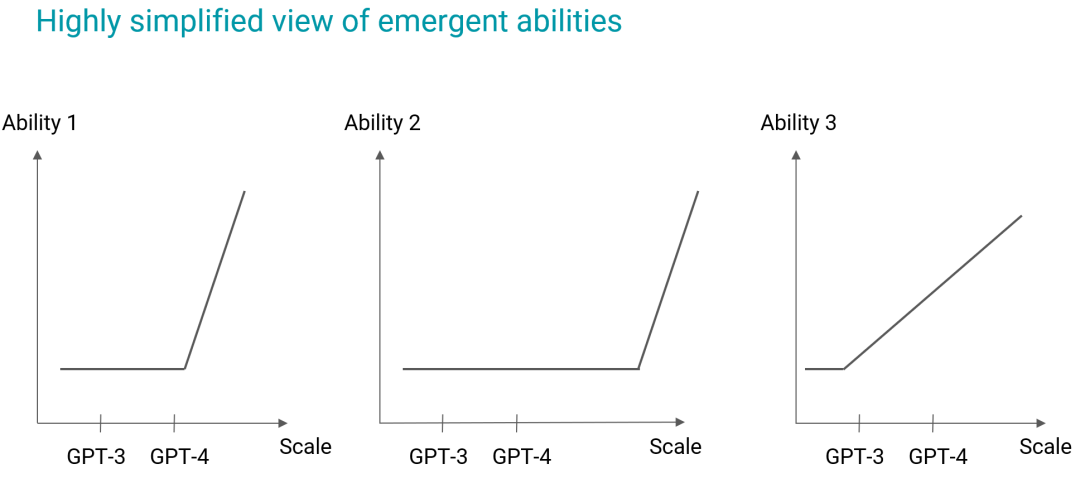
如左圖所示,能力 1 是 GPT-4 尚不具備但卻非常接近獲得的能力,稍強(qiáng)一點(diǎn)的模型可能就能獲得這一能力,實(shí)現(xiàn)突然的能力躍升。對(duì)于中圖的能力 2,即使強(qiáng)大的 GPT-4 也遙不可及,在短期內(nèi)可能無(wú)論如何也不可能觸及。至于右圖的能力 3,GPT-3 就已經(jīng)具備,之后改進(jìn)只會(huì)給這項(xiàng)能力帶來(lái)增量式的提升。
但在現(xiàn)實(shí)中,研究者可能很難確定自己正在解決的問(wèn)題是屬于哪一類。而 Chung 認(rèn)為,只要有前面所說(shuō)的思維框架 —— 不斷更新自己的認(rèn)知和理解,就能更輕松地識(shí)別自己正在解決的問(wèn)題。
規(guī)模擴(kuò)展何以有效?
Chung 說(shuō):「總結(jié)起來(lái),我們做的一切都與規(guī)模相關(guān),采用規(guī)模優(yōu)先(scale first)的視角是至關(guān)重要的。」但規(guī)模擴(kuò)展何以有效呢?
首先我們要從 Transformer 談起。

目前所有的 LLM 都使用了 Transformer 架構(gòu)。但這里不關(guān)心其架構(gòu)細(xì)節(jié),而是著眼其基本思想。
下面我們就從功能的角度來(lái)看看 Transformer。
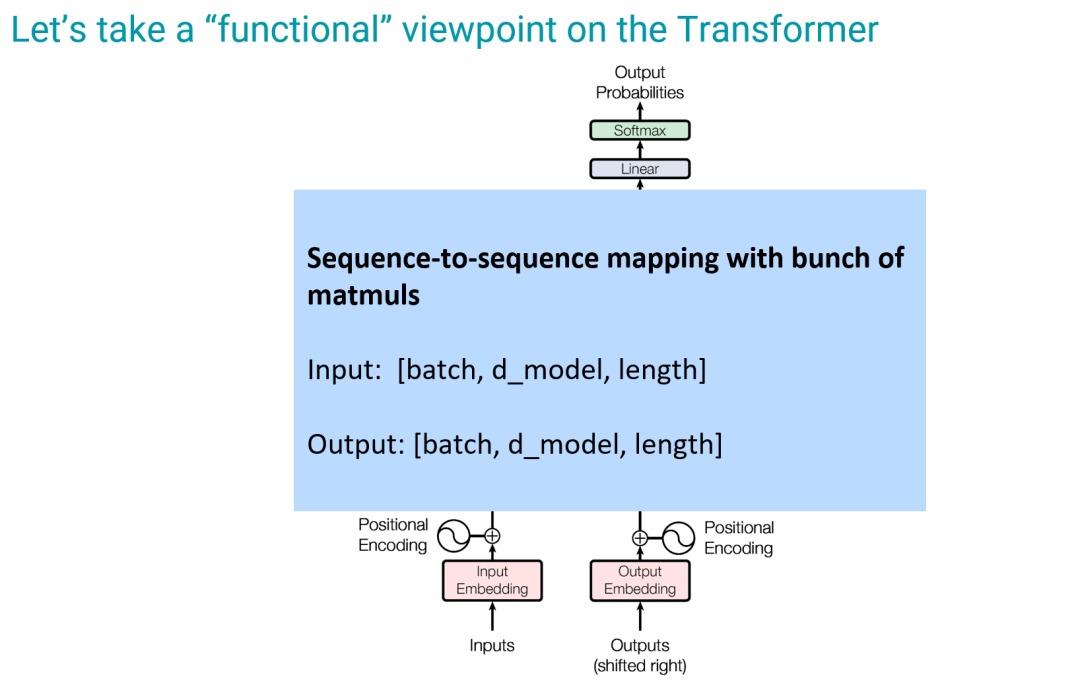
概括地看,Transformer 就是使用了大量矩陣乘法的序列到序列的映射,之后再進(jìn)行一些數(shù)組變換。
其輸入是一個(gè)由 [batch, d_model, length] 構(gòu)成的數(shù)組,其中 d_bacth 差不多就是該 Transformer 的寬度,length 是序列長(zhǎng)度。
在訓(xùn)練階段,輸出是一個(gè)與輸入大小相同的數(shù)組。當(dāng)然,在推理階段的情況不一樣,不過(guò)由于規(guī)模擴(kuò)展發(fā)生在預(yù)訓(xùn)練階段,所以輸出和輸入的長(zhǎng)度一樣。
這就是 Transformer 的核心思想,非常簡(jiǎn)單的序列到序列映射。
下面將從功能角度描述從輸入到輸出的過(guò)程。

通常一開始有一個(gè)句子,比如「Many words don't map to one token: indivisible.」這是一個(gè)字符串,其形狀為 []。
首先,將這個(gè)句子 token 化。token 化通常是通過(guò)一個(gè)外部模型來(lái)完成的,比如 BPE 或 SentencePiece,其目標(biāo)是盡可能地壓縮文本。這里經(jīng)過(guò) token 化后得到了一個(gè)整數(shù)列表,其形狀就為 [length]。
然后,將這些整數(shù)嵌入到一個(gè)隱藏空間中,這通常被稱為詞嵌入(word embedding)。現(xiàn)在,每個(gè) token 都被表示成了一個(gè)寬為 d_model 的向量,其長(zhǎng)度為 length,那么其形狀就為 d_model×length。
接下來(lái)就是計(jì)算量最大的地方 ——n 層 Transformer。簡(jiǎn)單來(lái)說(shuō),這個(gè)過(guò)程就是一個(gè)序列到序列的映射。這里的目標(biāo)是讓每個(gè)序列 token 與該序列中的其它 token 交互。這里我們不對(duì)其交互細(xì)節(jié)做任何假設(shè),只是讓它們交互。在 Transformer 中,讓它們交互的方式就是讓它們可以執(zhí)行點(diǎn)積運(yùn)算。模型要學(xué)習(xí)的就是如何執(zhí)行這個(gè)點(diǎn)積運(yùn)算。
之所以主要的計(jì)算量都在這里,是因?yàn)檫@里的計(jì)算涉及到高維數(shù)組,需要執(zhí)行大量矩陣乘法和數(shù)組運(yùn)算。
經(jīng)過(guò) n 層 Transformer 后,可以得到一個(gè)序列,之后再使用一個(gè)損失函數(shù)運(yùn)算一番,基于預(yù)測(cè)的下一 token 得到一個(gè)最大似然。最后得到一個(gè)數(shù)值。
之后,使用結(jié)果執(zhí)行反向傳播,更新所有參數(shù)。
在實(shí)際操作中,這個(gè)訓(xùn)練過(guò)程是批量進(jìn)行的,這就需要在數(shù)據(jù)結(jié)構(gòu)的維度中增添一個(gè) batch 維度。在這些數(shù)據(jù)批之間,唯一的依賴關(guān)系就是在最后計(jì)算損失時(shí)是計(jì)算它們的平均損失。

當(dāng)我們談?wù)摂U(kuò)展 Transformer 時(shí),我們通常說(shuō)的就是擴(kuò)展其中計(jì)算量最大的那部分。
依照第一性原理,擴(kuò)展 Transformer 就意味著要使用大量計(jì)算機(jī)高效地執(zhí)行上面的矩陣乘法運(yùn)算。

這個(gè)過(guò)程需要將 Transformer 層中涉及的所有矩陣(數(shù)組)分配到各臺(tái)計(jì)算機(jī)中。這個(gè)分配過(guò)程至關(guān)重要,必須要在盡可能降低機(jī)器之間通信量的同時(shí)來(lái)實(shí)現(xiàn)它。這是從非常底層的視角來(lái)理解規(guī)模擴(kuò)展。
矩陣乘法
為了更好地理解這一點(diǎn),我們首先需要了解矩陣乘法,尤其是在多臺(tái)機(jī)器上執(zhí)行矩陣乘法。如下圖所示,現(xiàn)在假設(shè)我們有 8 臺(tái)機(jī)器 —— 它們可能是 CUP 或 GPU。

現(xiàn)在我們要執(zhí)行一個(gè) 16×16 大小的矩陣乘法:A×B=C。
首先我們以一種抽象的方式來(lái)思考硬件:定義一個(gè) 2×4 的 mesh 網(wǎng)格。注意這個(gè)布局是虛擬的,與這些機(jī)器的實(shí)際物理位置無(wú)關(guān)。

然后為該網(wǎng)格定義 x 和 y 軸(硬件軸),之后每個(gè)參與計(jì)算的數(shù)組都將按照這個(gè)坐標(biāo)軸進(jìn)行映射 —— 將每個(gè)數(shù)組軸映射到硬件軸。我們可以從下圖的顏色對(duì)應(yīng)中看到這種映射。

現(xiàn)在我們來(lái)看輸出矩陣 C。我們希望在矩陣乘法運(yùn)算完成之后,C 矩陣左上角的 1 部分能位于機(jī)器 1 中。

這時(shí)候機(jī)器 1 要做的就是對(duì)矩陣 A 的第 1 行和矩陣 B 的第 1 列執(zhí)行 all-gather 操作(這是 MPI 的操作之一),之后再執(zhí)行計(jì)算得到 C 的 1 部分。
以矩陣 A 的第 1 行為例,all-gather 需要四臺(tái)機(jī)器之間進(jìn)行通信。機(jī)器 1 在與 2、3、4 通信之后會(huì)獲取其本地?cái)?shù)據(jù)的副本;機(jī)器 2、3、4 也會(huì)執(zhí)行類似的操作。故而該操作有 all-gather(全收集)之名。

all-gather 之后,機(jī)器 1 就有了計(jì)算所需的所有數(shù)據(jù)副本。

這個(gè)過(guò)程的關(guān)鍵之處在于其可以在全部 8 臺(tái)機(jī)器上并行地執(zhí)行。因此這個(gè)過(guò)程可以通過(guò)并行的方式得到加速,而其一大成本來(lái)源就是機(jī)器之間的通信。因此,在速度和通信成本存在一個(gè)權(quán)衡。
einsum
現(xiàn)在可以將矩陣乘法泛化成愛因斯坦求和方法(einsum),這是一種更高層面的看待數(shù)組計(jì)算的視角。

它的有兩個(gè)規(guī)則:1. 如果一個(gè)字母在兩個(gè)輸入中都出現(xiàn)了,那么就執(zhí)行逐分量的乘法;2. 如果輸出中不包含一個(gè)字母,則在該維度上執(zhí)行求和。
對(duì)于規(guī)則 1,以上圖中的第一行運(yùn)算為例,np.einsum ("i,i->i",a,b) 中的兩個(gè)輸入中都有 i(見引號(hào)內(nèi)部),這就意味著要直接執(zhí)行逐分量乘法來(lái)得到 i;這在 Numpy 中就等價(jià)于 a*b。
對(duì)于規(guī)則 2,則可見第二行運(yùn)算,其中有 "i,i→",這時(shí)候就需要先執(zhí)行逐分量乘法,然后求和。
而在第三行中,則有 "ij,j->i",這時(shí)候就需要在 j 上執(zhí)行點(diǎn)積,這也可被視為矩陣向量乘法。
當(dāng)然,上面只給出了一兩維的示例,einsum 也可以支持更多維度。
從 einsum 的角度看,矩陣乘法可以寫成如下形式:

現(xiàn)在回到前面在 8 臺(tái)機(jī)器上的矩陣乘法。

現(xiàn)在我們已經(jīng)為數(shù)組軸定義了 m、n、p 這樣的標(biāo)簽,就可以將它們映射到硬件軸,比如將 m 映射到 y,將 n 映射到 x。現(xiàn)在我們希望通過(guò)一個(gè)神奇的裝飾器函數(shù) parallelize 來(lái)做到這一點(diǎn)(后面會(huì)更具體說(shuō)明),它所做的就是在這兩個(gè)維度上以并行方式執(zhí)行 all-gather。

現(xiàn)在我們了解了矩陣乘法,接下來(lái)看 Transformer。
在 Transformer 中,最復(fù)雜的運(yùn)算操作是自注意力層,其中除了 softmax 之外的一切都可以使用 einsum 表示。

然后將其對(duì)應(yīng)到之前設(shè)定的 8 臺(tái)機(jī)器,這時(shí)候我們不再使用 x 和 y 來(lái)標(biāo)記硬件軸,而是使用研究者更習(xí)慣的「model」和「data」,分別對(duì)應(yīng)于模型并行維度和數(shù)據(jù)并行維度。
現(xiàn)在稍微修改一下上面的代碼,添加并行化,將 b 映射到 data,n 是序列長(zhǎng)度(Transformer 不對(duì)序列長(zhǎng)度做并行化處理),h 是注意力頭的數(shù)量(代表模型)—— 對(duì)注意力機(jī)制的并行化就是通過(guò)多頭來(lái)實(shí)現(xiàn)。

如此,接下來(lái)只需使用相同的代碼,就能實(shí)現(xiàn)并行化;下面是使用 8 臺(tái)機(jī)器的示例,但這一框架在任何機(jī)器數(shù)量下都適用。

一個(gè) TPU v4 pod 有 3072 塊 TPU chip。Chung 表示在訓(xùn)練 PaLM 模型時(shí),他們使用了 2 個(gè) pod,也就是 6144 塊 TPU chip,其中每一塊都與最高端的 GPU 一樣強(qiáng)大。
現(xiàn)在有了這么多機(jī)器,可以和之前一樣定義一個(gè)網(wǎng)格:模型并行維度為 48、數(shù)據(jù)并行維度為 64。
最后還有一個(gè)細(xì)節(jié):數(shù)據(jù)中心網(wǎng)絡(luò)(DCN)數(shù)據(jù)并行維度。這是因?yàn)檫@兩個(gè) pod 并不是直接連接在一起的,而是通過(guò)數(shù)據(jù)中心網(wǎng)絡(luò)連接的,其速度大概是 25 Gbps。這比 pod 內(nèi)部的通信慢多了。因此不應(yīng)在這個(gè)層面上執(zhí)行模型并行化。實(shí)際上,他們的做法是在梯度計(jì)算之后在這個(gè)數(shù)據(jù)中心網(wǎng)絡(luò)上對(duì)梯度求和。這只需要做一次,耗時(shí)很短。(在訓(xùn)練 5400 億參數(shù)的 PaLM 模型時(shí),每個(gè)訓(xùn)練步驟耗時(shí)大概 17 秒,因此這點(diǎn)耗時(shí)對(duì)整體影響不大。)
并行化裝飾器
前面我們是假設(shè)并行化裝飾器有效,但它究竟是如何工作的呢?一種方法是 GSPMD(arXiv:2105.04663)。

GSPMD 是一種基于編譯器的方法。使用該方法,你在寫神經(jīng)網(wǎng)絡(luò)時(shí)可以假設(shè)你的機(jī)器擁有無(wú)限內(nèi)存而不考慮并行化。然后將神經(jīng)網(wǎng)絡(luò)的核心部分表示成計(jì)算圖,再將該圖的輸入和輸出映射到硬件軸。最后將該圖交給 XLA;它會(huì)自動(dòng)插入必要的通信操作(如 all-gather),從而充分利用機(jī)器的全部能力。
Chung 表示這個(gè)過(guò)程很神奇,就像是魔法,但該方法并不總是有效,一些人在使用時(shí)會(huì)遇到困難。但整體來(lái)說(shuō)還是有用的,畢竟 T5、PaLM、Switch Transformer 等來(lái)自谷歌的大模型的后端都使用了 GSPMD。
當(dāng)然,也還存在其它一些方法,但它們都涉及到將數(shù)組軸映射到硬件。
對(duì)大多數(shù)研究者來(lái)說(shuō),GSPMD 可能很復(fù)雜,但 JAX 提供了一個(gè)前端 pjit,其使用方法如下:

大模型的規(guī)模擴(kuò)展問(wèn)題
對(duì)于大模型來(lái)說(shuō),預(yù)訓(xùn)練的成本很高。下圖是 Llama-2 模型預(yù)訓(xùn)練過(guò)程的困惑度變化情況,可以看到最后每個(gè)模型都處理了 2 萬(wàn)億個(gè) token!這可需要不少的時(shí)間。

但在實(shí)踐中,我們不會(huì)等到訓(xùn)練完成才觀察結(jié)果,也許一開始我們會(huì)訓(xùn)練 500 億個(gè) token,然后得到這樣的圖表:

這個(gè)時(shí)候我們就能斷言其中的 70B 模型表現(xiàn)最好嗎?并不能,因?yàn)樗鼈兊谋憩F(xiàn)還很接近。這時(shí)候要考慮如何投入資源是很困難的。
這就涉及到了預(yù)訓(xùn)練的一大根本課題:擴(kuò)展律(scaling laws)。
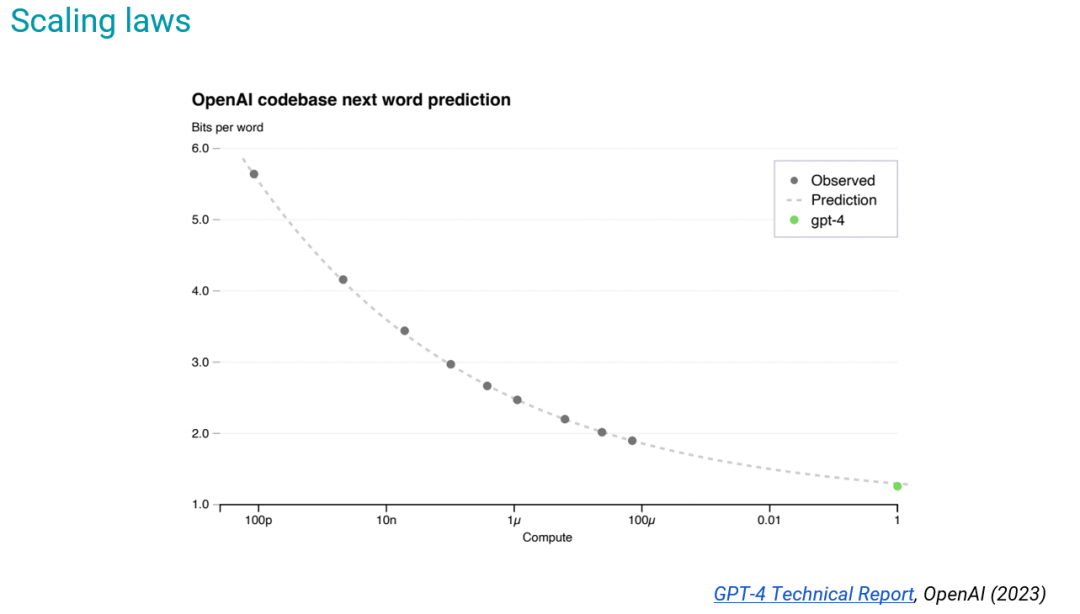
如圖所示的擴(kuò)展律來(lái)自《GPT-4 技術(shù)報(bào)告》(其中 x 軸是以 GPT-4 為標(biāo)準(zhǔn)歸一化之后的訓(xùn)練計(jì)算成本),其中的規(guī)律是根據(jù)更小的模型得出的,但其能準(zhǔn)確預(yù)測(cè) GPT-4 的最終損失。
現(xiàn)在進(jìn)行規(guī)模擴(kuò)展是比幾年前容易多了,但整體依然很困難,并不是說(shuō)改一些參數(shù)就能實(shí)現(xiàn)。

舉個(gè)例子,在 PaLM 的訓(xùn)練過(guò)程中,出現(xiàn)了損失突刺(loss spike)現(xiàn)象(比如損失從 2 突然變成了 6),這讓很多人都感到不安。

他們使用同樣的數(shù)據(jù)訓(xùn)練了三個(gè)不同規(guī)模的模型,但只有最大的一個(gè)出現(xiàn)了損失突刺現(xiàn)象。這讓研究者很難進(jìn)行調(diào)試,因?yàn)闊o(wú)法在更小的模型上復(fù)現(xiàn)出來(lái)。而且這也不是由數(shù)據(jù)質(zhì)量差導(dǎo)致的。而當(dāng)出現(xiàn)這種情況,讓人無(wú)法決定該怎么辦時(shí),都只得讓大量機(jī)器閑置下來(lái),造成巨大浪費(fèi)。這些方面都有需要攻克的難題。
盡管現(xiàn)在已經(jīng)有 Llama-2 等一些模型讓人可以更輕松地訓(xùn)練給定大小的模型,但是進(jìn)一步擴(kuò)展就困難重重了。
后訓(xùn)練也很重要

所以,擴(kuò)大規(guī)模并非萬(wàn)能方法,還需要開發(fā)出很多工程方法,其中很多都可以歸類為后訓(xùn)練(post-training)。
為什么我們需要后訓(xùn)練?
首先,我們無(wú)法直接與預(yù)訓(xùn)練模型對(duì)話,因?yàn)槠溆?xùn)練目標(biāo)就只是預(yù)測(cè)下一個(gè) token。下面給出了一個(gè)例子:對(duì)于左側(cè)的輸入,預(yù)訓(xùn)練后的 PaLM 540B 就只會(huì)不斷預(yù)測(cè)下一個(gè)詞;但我們期望是類似右側(cè)的答案。
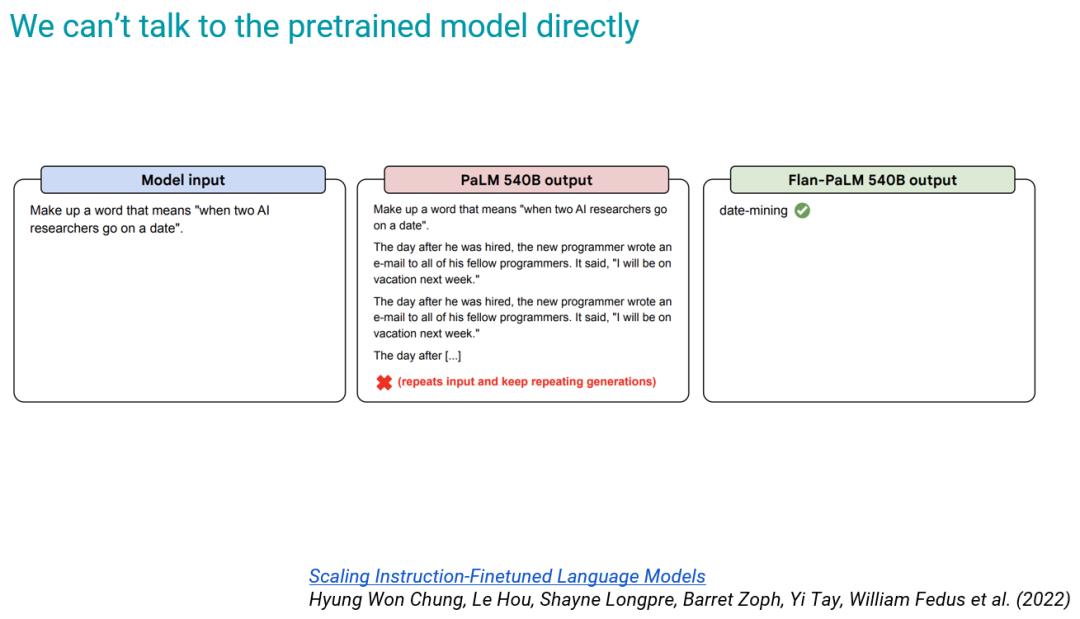
當(dāng)然,我們可以通過(guò)一個(gè)技巧來(lái)解決這個(gè)問(wèn)題,也就是將問(wèn)題構(gòu)造成某種形式,使得下一個(gè) token 就是答案本身。下圖給出了一個(gè)示例:

如果模型還是不回答問(wèn)題,那么我們就可以在前面提供一些示例,演示模型該如何給出下一個(gè) token。這種方法被稱為 few-shot prompting。這種方法很強(qiáng)大,但并不普遍適用。
預(yù)訓(xùn)練模型還有另一個(gè)問(wèn)題:總是生成 prompt 的自然延續(xù),即便 prompt 本身是惡意和有害的。預(yù)訓(xùn)練模型不知道如何拒絕響應(yīng)惡意 prompt。而這些能力可通過(guò)后訓(xùn)練方法來(lái)獲得;人們通常將這樣的過(guò)程稱為對(duì)齊人類價(jià)值觀。
對(duì)于當(dāng)前的 LLM,后訓(xùn)練是指下圖中預(yù)訓(xùn)練之后的階段。

指令微調(diào)
概括來(lái)說(shuō),指令微調(diào)是將所有任務(wù)都表述成自然語(yǔ)言指令到自然語(yǔ)言響應(yīng)的映射。

以文本分類任務(wù)為例,就是文本到標(biāo)簽的映射。但 2018 年的 BERT 在這個(gè)過(guò)程中必需要有針對(duì)這個(gè)特定任務(wù)的線性層,以將句子投影到分類空間。這樣一來(lái),用于本文分類任務(wù)的模型就很難用于其它任務(wù)了。

一年后誕生的 T5 模型就不需要這樣的線性層了。它做的是文本到文本的映射,能廣泛地適用于各種不同的文本任務(wù)。

但這也會(huì)有個(gè)問(wèn)題:T5 支持多種不同任務(wù),但它怎么知道當(dāng)前任務(wù)是什么任務(wù)呢?研究者的做法是在輸入中添加元數(shù)據(jù),比如 cola 和 stsb。

但這種做法不自然,不符合人類的表達(dá)習(xí)慣。接下來(lái)的發(fā)展就是讓模型能夠理解以自然語(yǔ)言表達(dá)的任務(wù)。比如現(xiàn)在我們不再使用 cola 來(lái)指示模型執(zhí)行 GLUE 中的 CoLA 任務(wù),而是問(wèn):「下面的句子是否是可接受的?」

為什么 T5 模型誕生的時(shí)候沒(méi)有采用這種方法呢?Chung 表示是因?yàn)楫?dāng)時(shí)人們認(rèn)為語(yǔ)言模型不能理解自然語(yǔ)言指令,反而覺得使用元數(shù)據(jù)的方式更自然。
當(dāng)更大的模型出現(xiàn)后,理解自然語(yǔ)言的能力就涌現(xiàn)出來(lái)了,然后我們就能使用豐富的自然語(yǔ)言將各種任務(wù)統(tǒng)一起來(lái)。之后,當(dāng)模型遇到未曾見過(guò)的任務(wù)時(shí),模型只需響應(yīng)自然語(yǔ)言指令即可。這也是一種泛化。
這就引出了一個(gè)問(wèn)題:如果訓(xùn)練集中有更多指令,能不能得到更好的模型,實(shí)現(xiàn)更好的泛化呢?

Chung 等人通過(guò)一個(gè)大規(guī)模實(shí)驗(yàn)檢驗(yàn)了這一假設(shè)。為此,他們收集了 1836 個(gè)學(xué)術(shù)任務(wù),然后將它們混合起來(lái)用于訓(xùn)練。
如下圖所示,y 軸是在評(píng)估集上的平均分?jǐn)?shù)。他們選擇了 80 億參數(shù)的 PaLM 模型難以應(yīng)對(duì)的 6 個(gè)訓(xùn)練期間未曾見過(guò)的任務(wù)來(lái)進(jìn)行測(cè)試,發(fā)現(xiàn)隨著模型增大以及訓(xùn)練任務(wù)增多,模型的表現(xiàn)越來(lái)越好。但可以看出來(lái),任務(wù)數(shù)量增至一定程度時(shí),模型的性能增幅也會(huì)降低。這是因?yàn)槿蝿?wù)的數(shù)量沒(méi)有任務(wù)的多樣性重要。

機(jī)器之心曾經(jīng)報(bào)道過(guò)這項(xiàng)研究,參閱《30 億跑贏 GPT-3 的 1750 億,谷歌新模型引熱議,然而卻把 Hinton 年齡搞錯(cuò)了》。
于是 Chung 得出了結(jié)論:指令微調(diào)的效果很好,但卻存在固有的限制。這一現(xiàn)象的根本原因是什么呢?
首先我們確定一下指令微調(diào)的學(xué)習(xí)目標(biāo):不管是使用交叉熵?fù)p失還是最大似然,目標(biāo)都是對(duì)于給定輸入都能給出單個(gè)正確回答,而其它答案都是錯(cuò)的。在強(qiáng)化學(xué)習(xí)文獻(xiàn)中,這被稱為行為克隆(behavior cloning)。

我們希望如果能有足夠多的這些答案的變體,模型就能泛化用于不同的任務(wù)類型。為此,就需要形式化模型在給定輸入下的正確行為,以便模型克隆。
過(guò)去,這種操作執(zhí)行起來(lái)很簡(jiǎn)單,但現(xiàn)在難度卻在增大。
下面將通過(guò)一些示例來(lái)說(shuō)明。
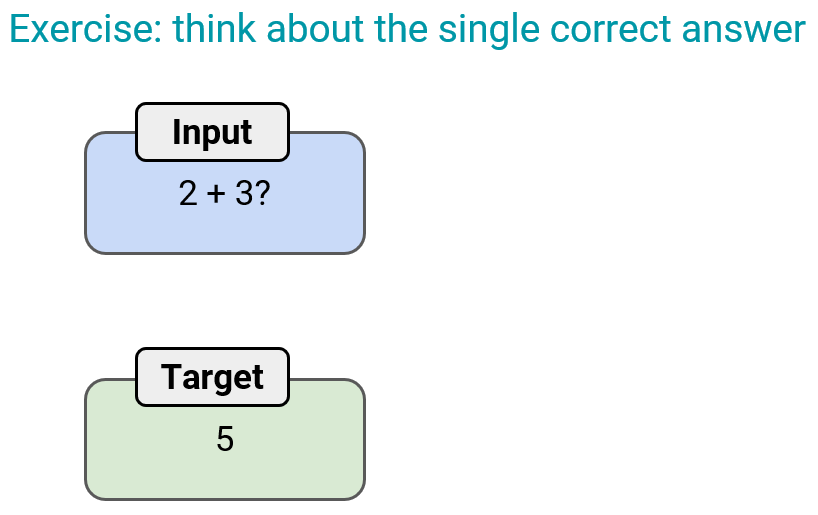
首先是一個(gè)思想實(shí)驗(yàn),假設(shè)有一個(gè)問(wèn)題,它只有唯一正確的答案,比如「2+3=?」有唯一正確答案「5」。這沒(méi)有異議。
而對(duì)于翻譯任務(wù),我們也可以大致提供一個(gè)唯一正確答案,當(dāng)然,一個(gè)句子翻譯成另一種語(yǔ)言時(shí)可能會(huì)有多種變體。

但對(duì)于以下任務(wù)呢:以圣誕老人的口吻寫一封信給一位五歲孩童,解釋圣誕老人不是真的,要求語(yǔ)氣溫柔,不要讓這個(gè)孩子傷心。

Chung 表示自己沒(méi)信心為這個(gè)任務(wù)給出一個(gè)好答案。
對(duì)于這樣的任務(wù),Chung 認(rèn)為并不適合使用最大似然作為大模型的學(xué)習(xí)目標(biāo)。
接下來(lái)是一個(gè)更為實(shí)際的例子,Chung 表示自己經(jīng)常使用這一 prompt 來(lái)測(cè)試新模型:用 Python 通過(guò)梯度下降實(shí)現(xiàn) logistic 回歸。

這個(gè)任務(wù)并不存在唯一正確的答案 —— 可能有函數(shù)式編程風(fēng)格的答案,也可能有面向?qū)ο笫降拇鸢浮_@些不同的答案可能都是正確的。這樣一來(lái),使用其中一個(gè)作為唯一正確答案是合適的做法嗎?
Chung 給出了一些觀察:

- 我們?cè)絹?lái)越希望教會(huì)模型掌握更抽象的行為
- 指令微調(diào)的目標(biāo)函數(shù)似乎是教授這些行為的「瓶頸」
- 最大似然目標(biāo)是「預(yù)定義的」函數(shù)(即不可學(xué)習(xí)的參數(shù))
- 我們能否參數(shù)化目標(biāo)函數(shù)并學(xué)習(xí)它?
這就是 RLHF 的核心思想。
使用人類反饋的強(qiáng)化學(xué)習(xí)(RLHF)
強(qiáng)化學(xué)習(xí)(RL)提供了一種學(xué)習(xí)目標(biāo)函數(shù)的方法。

強(qiáng)化學(xué)習(xí)的目標(biāo)是最大化預(yù)期的獎(jiǎng)勵(lì)函數(shù),而我們可以使用一個(gè)神經(jīng)網(wǎng)絡(luò)模型(獎(jiǎng)勵(lì)模型)來(lái)為更為復(fù)雜的情況制定獎(jiǎng)勵(lì)。
那么怎么訓(xùn)練這個(gè)獎(jiǎng)勵(lì)模型呢?

對(duì)于給定的輸入,為其提供兩個(gè)可能的答案,然后讓人類提供對(duì)這兩個(gè)答案的偏好。也就是說(shuō)不是提供一個(gè)最佳答案,而是讓人類評(píng)估兩個(gè)答案中哪個(gè)更好。AI 模型就可以依照這種方式學(xué)習(xí)人類的偏好。
比如在上圖的例子中,人類更偏好結(jié)果 2,但這個(gè)結(jié)果并不見得就是最佳結(jié)果,只能說(shuō)比結(jié)果 1 更好。
對(duì)于有著清晰明確答案的簡(jiǎn)單任務(wù),這種比較方法可能用處不大,不如使用有最大似然目標(biāo)的監(jiān)督學(xué)習(xí)。

但對(duì)于開放式的生成任務(wù),相比于為答案打分,比較候選答案之間的相對(duì)優(yōu)劣會(huì)更容易。

下面是這種獎(jiǎng)勵(lì)模式的數(shù)學(xué)描述:

有了獎(jiǎng)勵(lì)模型之后,就可以通過(guò)強(qiáng)化學(xué)習(xí)來(lái)學(xué)習(xí)語(yǔ)言模型的參數(shù),以最大化預(yù)期獎(jiǎng)勵(lì)。

這里,目標(biāo)函數(shù)就是剛剛的獎(jiǎng)勵(lì)模型,也就是參數(shù) Φ,其在初始的強(qiáng)化學(xué)習(xí)后就固定了。
在這個(gè)公式中,對(duì)于一個(gè) prompt,策略模型(通常是根據(jù)監(jiān)督式指令微調(diào)的檢查點(diǎn)模型進(jìn)行初始化)會(huì)生成一些候選結(jié)果;然后它們被提供給獎(jiǎng)勵(lì)模型,獎(jiǎng)勵(lì)模型返回分?jǐn)?shù),策略模型就可以根據(jù)這個(gè)反饋進(jìn)行調(diào)整。這就像是一個(gè)試錯(cuò)過(guò)程。
我們可以通過(guò)基于梯度的迭代方法來(lái)最大化預(yù)期獎(jiǎng)勵(lì),這個(gè)過(guò)程要用到一些策略梯度算法,如 PPO。

總結(jié)起來(lái)即為:獎(jiǎng)勵(lì)模型編碼人類偏好,然后將其傳遞給策略模型,讓其通過(guò)強(qiáng)化學(xué)習(xí)進(jìn)行學(xué)習(xí)。
但在實(shí)踐中,很多人并不喜歡 RLHF,甚至希望拋棄這個(gè)方法,因?yàn)樗茈y做好。

RLHF 的一個(gè)常見問(wèn)題是「獎(jiǎng)勵(lì)攻擊(reward hacking)」。
舉個(gè)例子,假設(shè)有人類標(biāo)注者對(duì)一些完成結(jié)果進(jìn)行標(biāo)注 —— 標(biāo)記一對(duì)結(jié)果中哪一個(gè)更好,而如果他們標(biāo)記的都剛好是更長(zhǎng)的結(jié)果更好,那么策略模型就會(huì)認(rèn)為獎(jiǎng)勵(lì)模型更喜歡更長(zhǎng)的結(jié)果,然后漸漸地,它就會(huì)越來(lái)越多地給出很長(zhǎng)但看起來(lái)很蠢的結(jié)果。這時(shí)候獎(jiǎng)勵(lì)模型給出的獎(jiǎng)勵(lì)越來(lái)越高,但人類的滿意度卻會(huì)下降。這種現(xiàn)象其實(shí)很難控制,Chung 表示目前還沒(méi)有徹底解決這一問(wèn)題的方法。
但即使存在這些問(wèn)題,Chung 認(rèn)為我們還是應(yīng)該繼續(xù)研究 RLHF,他認(rèn)為原因包括:
- 最大似然有過(guò)于強(qiáng)大的歸納偏見,當(dāng)模型規(guī)模變大時(shí),這個(gè)問(wèn)題會(huì)更顯著;
- 學(xué)習(xí)目標(biāo)函數(shù)是一種不同的范式,有助于緩解這個(gè)問(wèn)題,能提供很大的提升空間,ChatGPT 等一些成功利用 RLHF 的案例只是一個(gè)開始;
- 其原理很可靠,值得進(jìn)一步發(fā)掘其功效。
AI 的未來(lái)發(fā)展
Chung 最后簡(jiǎn)單回顧了 AI 過(guò)去的發(fā)展歷程并談到了自己對(duì) AI 未來(lái)發(fā)展的展望。

他分享說(shuō),從基于規(guī)則的系統(tǒng)到經(jīng)典機(jī)器學(xué)習(xí)技術(shù),再到深度學(xué)習(xí)以及使用 RLHF 的深度學(xué)習(xí),AI 系統(tǒng)中可學(xué)習(xí)的部分(圖中藍(lán)色部分)在不斷增多,其能力也越來(lái)越強(qiáng)大。
現(xiàn)在,損失函數(shù)也正在變成系統(tǒng)中的可學(xué)習(xí)部分,并且已經(jīng)有 GAN 和 RLHF 這樣的成功案例。這讓 AI 系統(tǒng)可以學(xué)習(xí)去做那些正確行為難以形式化的任務(wù)。
Chung 認(rèn)為這就是未來(lái)的下一個(gè)范式,其將帶來(lái)的技術(shù)進(jìn)步不會(huì)亞于之前每一次范式轉(zhuǎn)變。

至于哪個(gè) AI 模型將成為這個(gè)新范式的旗艦代表,就讓我們拭目以待吧。





















