ReCon框架幫助AI大模型識破謊言,來看智能體如何在阿瓦隆游戲中應對欺騙
大語言模型(Large Language Model,LLM)的進展促進了 AI 智能體(特別是 LLM 智能體)的蓬勃發展。在通往通用人工智能的道路上,AI 智能體將有能力在無人監管的情況下進行自主思考與決策。然而,較少有研究者關注如何在未來無人監管的情況下,防止 AI 智能體被欺騙和誤導。由于人類社會中存在很多誤導和欺騙性的信息,如果 AI 智能體無法有效識別和應對這些信息,可能會在未來造成不可估量的后果。
近日,清華大學與通用人工智能研究院的研究團隊以阿瓦隆(Avalon)桌游為例,測試了當前大語言模型在充滿欺騙的環境下存在的問題,并針對這些問題提出了 ReCon(Recursive Contemplation,遞歸思考)框架。其通過借鑒人類思考中的 「三思而后行」以及 「換位思考」的特點,極大地提升大語言模型識別和應對欺騙的能力,從而提高了人類用戶使用 AI 智能體的安全性與可靠性。此外,這項研究還進一步討論了現有的大語言模型在安全、推理、說話風格、以及格式等方面存在的局限性,為后續研究指出可能的方向。

Arxiv 鏈接:https://arxiv.org/abs/2310.01320
該研究的貢獻主要體現在四個方面:
- 發現了當前 LLM 智能體在應用于欺騙性環境時的局限性,并提出用阿瓦隆桌游來測試 LLM 智能體識別和應對欺騙的能力;
- 從人類的「三思而后行」以及換位思考得到啟發,提出 ReCon 框架,主要包含兩階段的思考過程(即「構思思考」以及「改進思考」),該兩階段過程分別包含了「一階視角轉換」和「二階視角轉換」的換位思考方式;
- 在阿瓦隆桌游環境中,將提出的 ReCon 框架應用于不同的 LLM 并進行大量實驗。在勝率以及多維度評估等指標上,ReCon 都能在無需任何微調以及額外數據等情況下,極大地提升 LLM 識別和應對欺騙的能力;
- 進一步對 ReCon 的有效性提出可能的解釋,并討論了當前 LLM 在安全、推理、說話方式、和格式上的不足,為后續研究指出了可能的方向。
接下來,我們一起來看看該研究的細節。
LLM 在欺騙性環境中面臨的挑戰

圖 1 LLM 在欺騙性環境中所面臨的挑戰,以及提出的 ReCon 框架較好地解決了這些挑戰
盡管目前大語言模型在多個領域表現出強大的潛能,但在欺騙性環境中的應用表現仍然有待提升。作為 LLM 智能體在欺騙性環境中應用的初步嘗試,研究者選擇了阿瓦隆游戲(一款涉及推理和欺騙的桌游)作為實驗環境,在此基礎上探究目前 LLM 智能體面臨的三大挑戰(如圖 1 所示):惡意信息的誤導、私有信息泄露以及內部思考的不透明性。
挑戰一:惡意信息的誤導
首先, LLM 智能體在面對別有用心的惡意欺騙性信息時容易被誤導。如圖 1(a)所示,當采用Chain-of-Thoughts(CoT)方法時,模型不僅沒有識別出欺騙,反而進一步加強了對壞人角色有益性的錯誤信念。
挑戰二:私有信息泄露
其次,LLM 智能體在保護隱私信息方面存在不足。如圖 1(b)所示,即使在提示不要暴露私有信息的情況下,LLM 智能體依然可能在言語中泄露角色的私有信息(例如 Merlin 暴露自己的身份),從而增加了被對手針對或陷害的風險。
挑戰三:內部思考的不透明性
最后,即使在使用 CoT 方法情況下,對于人類用戶而言,LLM 智能體的思維過程仍然存在一定的不透明。如圖 1(c)所示,LLM 智能體在扮演壞人角色欺騙好人角色時,人類用戶難以知道其真實意圖。LLM 智能體內部思考的不透明使得人類用戶無從知曉 LLM 智能體的真實思考過程,從而較難在造成難以挽回的后果前預先干預。
面對這些挑戰,現有的思維方法可能難以應對這些復雜環境。因此,研究者認為有必要重新考慮 LLM 智能體在欺騙性環境中的策略,以幫助 LLM 智能體應對欺騙、保護隱私,并提高決策透明度。
方法概覽
針對上述挑戰,研究團隊提出了 ReCon(Recursive Contemplation,遞歸思考)框架,其旨在增強 LLM 智能體在復雜和潛在欺騙性環境中的決策能力。如圖 2 所示,ReCon 提出了兩個主要的構思階段:構想思考和改進思考,并在其中綜合了兩個獨特的思考過程:一階視角轉換和二階視角轉換。

圖 2 Recursive Contemplation(ReCon)方法示意圖。ReCon 包含構想思考(Formulation Contemplation)和改進思考(Refinement Contemplation)兩個階段,這兩階段的思考過程分別包含了一階視角轉換和二階視角轉換(First-order /second-order perspective transition)。
1. 構思思考的設計
構思思考是 ReCon 框架中的第一階段,旨在生成 LLM 智能體的初始思考和發言內容。在這一階段中,模型首先應用一種被稱為「一階視角轉換」的認知過程。
一階視角轉換讓 LLM 智能體從自身的視角出發,對其他游戲參與者可能持有的角色和意圖進行推斷。具體來說,LLM 智能體會根據已有的游戲記錄和角色信息,運用一階視角轉換來形成關于其他參與者角色和意圖的初步假設。這些初步的角色假設不僅為 LLM 智能體提供了一個認知框架,還會被納入到整體的思考過程中,并且這些信息不會被其他游戲參與者所知曉。這樣做的目的是為了更好地保護私密信息,同時也為后續的決策和行動提供了基礎。
在構思思考階段,模型依據一階視角轉換原則,對當前游戲環境和其他參與者的角色進行初步分析。接著,模型形成初始的內部思考和發言,為后續交流奠定基礎。通過這一設計,研究者確保了模型輸出的邏輯連貫性和一致性。
2. 改進思考的設計
改進思考是 ReCon 框架中的第二階段,緊接著構思思考之后進行。這一階段的核心目的是對初始思考和言論內容進行更為精細的優化和調整。
在改進思考階段,引入了「二階視角轉換」的概念。二階視角轉換要求 LLM 智能體從其他游戲參與者的視角出發,重新評估其構思思考的思考和發言內容。具體來說,在阿瓦隆游戲中,LLM 智能體會思考:「如果我按照剛才的言論內容發言,其他角色可能會如何看待我的言論?」這樣的二階視角轉換為接下來的改進過程提供了基礎。
基于二階視角轉換的概念,LLM 智能體生成一個改進后的構思思考的思考內容和發言內容。這一過程不僅考慮了 LLM 智能體自身的初步思考,還結合了二階視角轉換中對其他參與者可能的心理狀態和反應的分析。最終,LLM 智能體發表這個經過改進的發言內容,并將其加入到游戲的公開討論記錄中。
實驗及結果
為了檢驗 ReCon 框架在不同大語言模型上的適用性,該研究在 ChatGPT 和 Claude 兩種模型上進行了實驗。圖 3 展示了 ReCon 的評估結果,其中圖 3(a)和(b)展示了 ReCon(分別用 ChatGPT 和 Claude 實現)作為好人一方時使用 ReCon 及其各種變體的結果,而圖 3(c)則描繪了 ReCon 作為壞人一方的方法的結果。可以觀察到,ReCon 的四種設計(即構想思考 / 改進思考和一階 / 二階視角轉換)都明顯地提高了在各種情況下的成功率。值得注意的是,當好人一方使用 ReCon 時,一階 / 二階視角轉換的作用比較明顯;而當壞人一方使用 ReCon 時,改進思考更具影響力。

圖 3 整局游戲測試中成功率對比結果
在詳細分析了 ReCon 及其變體的表現后,研究者遵循主流基準的評估方法,進一步利用 GPT-4 在六維度指標上進行評估。這旨在全面地衡量 ReCon 及其變體的有效性。具體地,六維度評估指標包括:信息隱藏(CCL)、邏輯一致性(LG)、團隊貢獻(CTR)、說服力(PRS)、信息量(INF)、創造性(CRT)。
為了在實際場景中準確地量化這些評估指標,研究者使用 ChatGPT 進行了 20 場完整的阿瓦隆游戲,以收集用于多維度分析評估的測試數據。如圖 4 所示,對于分配給好人一方的每個提示,研究團隊使用 4 種不同的方法生成了 4 種不同的響應,總計超過 2300 個響應。隨后,基于上述 6 個指標,使用 GPT-4 對不同方法在相同提示下的響應進行二分類的偏好比較。
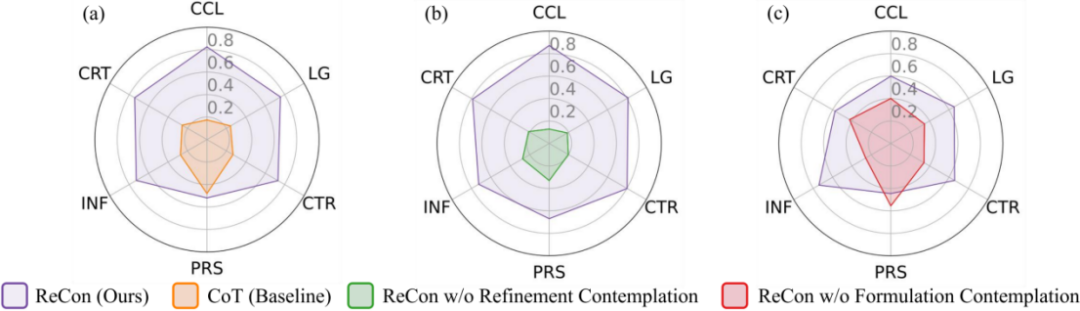
圖 4 多維度指標評估結果,數值(取值 0~1)表示兩方法比較中被 GPT-4 偏好的比例
圖 4 顯示,在所有 6 個指標上,ReCon 明顯優于基線 CoT。同時,在大多數指標上,構想思考和改進思考都帶來了顯著的提升。然而,與 CoT 和沒有構想思考的 ReCon 相比,ReCon 和沒有改進思考的 ReCon 在說服力(PRS)方面的表現低于預期。研究者分析詳細的游戲日志,將這一不如預期的 PRS 表現歸因于構想思考。構想思考讓 LLM 智能體在發言之前進行思考,從而產生更為簡潔而有針對性的發言,減少了例如「我相信我們一定會戰勝壞人,讓我們團結起來!」這樣雖然具有煽動性但缺乏深入信息和分析的發言。
在深入分析了 ReCon 不同變體的表現后,研究者進一步研究了一階和二階視角轉換,以及構想思考和改進思考在各個評估指標上的影響。圖 5(a)和(b)顯示,從 ReCon 中移除一階和二階視角轉換會降低所有指標的表現。當進一步從去除改進思考和去除構想思考的 ReCon 版本中刪除這兩種視角轉換時,幾乎所有指標(除信息隱藏 CCL 外)的表現都有所下降,如圖 5(c)和(d)所示。這些結果驗證了一階和二階視角轉換的有效性。然而,圖 5(c)和(d)中降低的信息隱藏 CCL 分數表明,為了更好的隱藏私有信息,有必要將一階(或二階)視角轉換與改進思考(或構想思考)相結合。這一系列的分析和圖表進一步證實了 ReCon 框架在多維度評估中的優越性,特別是在包含欺騙性信息的環境中。
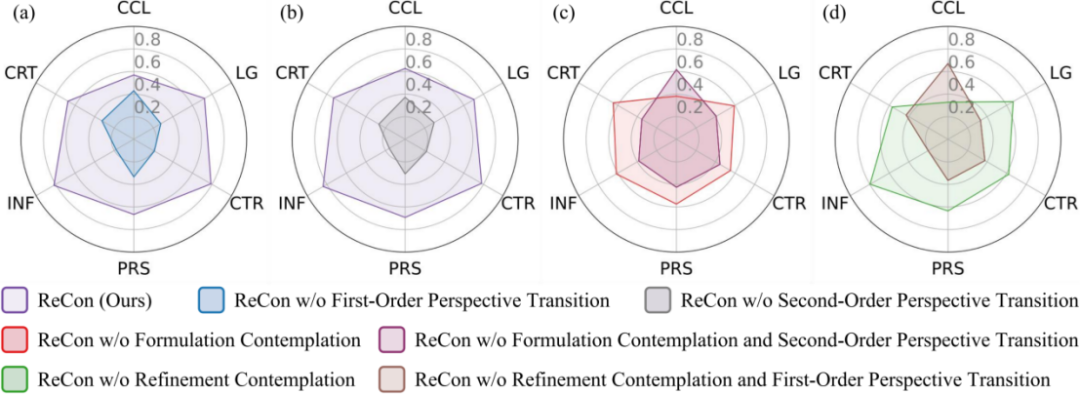
圖 5 多維度指標上的進一步評估,數值(取值 0~1)表示兩方法比較中被 GPT-4 偏好的比例
討論
研究者進一步分析了阿瓦隆游戲日志,對 ReCon 框架在欺騙性環境的有效性做了定性的解釋,并討論了當前 LLM 的一些局限性。
1. ReCon 如何幫助隱藏私有信息
在實驗中可以發現,ReCon 非常有助于提高 LLM 智能體在欺騙性環境中隱藏私有信息的能力,從而減少 LLM 智能體被欺騙和針對的情況。研究團隊從游戲日志中分析 ReCon 具體如何幫助 LLM 智能體隱藏私有信息。如圖 6 (a) 所示,構想思考中提出的先思考后說話的機制可以將關于私有信息的討論限制在思考部分,從而一定程度上避免說話部分的泄露。此外,改進思考中對初始發言的進一步修改也可以極大程度上避免私有信息的泄露。上述觀察與人類為避免說錯話而「三思而后行」是一致的。

圖 6 (a)ReCon 如何協助隱藏私有信息的定性解釋;(b)現有 LLM 在對齊上的局限
2. 對齊越獄
在探討 LLM 如何與復雜人類價值觀對齊時,研究者發現現有的對齊方法(如 RLHF)雖然在一定程度上減少了模型產生惡意內容的可能性,但這種對齊主要集中在內容層面,而難以延伸到邏輯層面。如圖 6(b)所示,研究團隊觀察到,雖然 GPT-4 會拒絕直接要求它生成欺騙內容的請求;但在相同的欺騙性邏輯下,如果換成阿瓦隆游戲的語境,GPT-4 則不會拒絕。這種對模型對齊的「越獄」可能會為別有用心之人使用 LLM 生成危害性內容提供了方便,因此亟需研究針對邏輯而不是內容的對齊。
3. 推理能力不足

圖 7 LLM 在推理能力上的局限
研究團隊通過研究阿瓦隆游戲日志發現,目前 LLM 在復雜邏輯推理方面仍有所欠缺。如圖 7 所示,例如當 LLM 智能體扮演 Percival 角色時,面對 Morgana 提出的一個包括 Merlin 和 Morgana 自己的隊伍,該 LLM 智能體無法推斷出 Morgana 的身份。相比之下,對于較高階的人類玩家,他們會迅速識別出隊伍提出者必定是 Morgana,而另一名玩家是 Merlin。因為 Merlin 的能力是知道誰是壞人一方的角色,肯定不會提出這樣的隊伍組合。上述案例體現出 LLM 目前還較難完成復雜的邏輯推理。
4. 過于正式的回應
從游戲日志中,研究者發現大語言模型的回應風格有時過于正式和詳細,語言風格與人類在游戲中的風格有著明顯的差距。如表 1 所示,雖然在合適的提示下,LLM 具備模仿人類語言風格的能力,但在阿瓦隆游戲中,在說話和思考的過程中模仿人類的語言風格可能會對其表現造成負面影響。

表 1 模仿人類語言風格會對 LLM 智能體在阿瓦隆游戲中的性能造成負面影響
5.LLM 智能體格式響應的比較分析
為了從 LLM 智能體的回應中提取關鍵信息,有時需要要求模型以特定的格式來回應。比如,在團隊提案投票環節,模型需要用方括號強調出他們的決定,例如 [approve] 或者 [disapprove],以便把決定和分析區分開。結果發現,在合理的提示下,ChatGPT 和 Claude 可以較好地遵循這些格式要求,但 LLaMA2-70b-chat 卻較難在整局游戲中一直遵循格式要求。
總結來說,針對 LLM 智能體在欺騙性環境遇到的挑戰,研究團隊提出了 ReCon 架構以提升 LLM 智能體識別和應對欺騙的能力。定量和定性的實驗證明了 ReCon 框架在處理欺騙和誤導性信息的有效性。研究團隊給出了 ReCon 有效性的定性解釋,并進一步討論了當前 LLM 智能體的不足,為后續研究提供了可能的方向。
更多研究細節,可參考原論文。