













小紅書提出新面部視頻交換方法DynamicFace,可生成高質量且一致的視頻面部圖像
DynamicFace是一種新穎的面部視頻交換方法,旨在生成高質量且一致的視頻面部圖像。該方法結合了擴散模型的強大能力和可插拔的時間層,以解決傳統面部交換技術面臨的兩個主要挑戰:在保持源面部身份的同時,準確傳遞目標面部的運動信息。通過引入四種細粒度的面部條件,DynamicFace能夠對面部特征進行更精確的控制,從而實現高保真度的面部交換。實驗結果表明,該方法在圖像質量、身份保留和表情準確性方面均優于現有技術,并且能夠有效地擴展到視頻領域,展示了其強大的應用潛力。


unsetunset相關鏈接unsetunset
- 論文:http://arxiv.org/abs/2501.08553v1
- 主頁:https://dynamic-face.github.io/
unsetunset論文介紹unsetunset
人臉交換將源人臉的身份轉移到目標人臉,同時保留目標人臉的表情、姿勢、頭發和背景等屬性。先進的人臉交換方法取得了令人滿意的結果。然而,這些方法經常無意中從目標人臉轉移身份信息,損害與表情相關的細節和準確的身份。
論文提出了一種新方法 DynamicFace,利用擴散模型和即插即用時間層的強大功能進行視頻人臉交換。首先使用 3D 面部先驗引入了四個細粒度的人臉條件。所有條件都設計為相互分離,以實現精確和獨特的控制。然后采用 Face Former 和 ReferenceNet 進行高級和詳細的身份注入。通過在 FF++ 數據集上的實驗證明了提出的方法在人臉交換方面取得了最先進的成果,展示了卓越的圖像質量、身份保存和表情準確性。此外,該方法可以通過時間注意層輕松轉移到視頻領域。
 可組合的面部條件。提出的方法目標是將面部分解為四個條件,并捕捉每個條件的獨特用法。條件相互解開,并通過 3D 面部先驗提供必要的指導。
可組合的面部條件。提出的方法目標是將面部分解為四個條件,并捕捉每個條件的獨特用法。條件相互解開,并通過 3D 面部先驗提供必要的指導。
unsetunset方法unsetunset
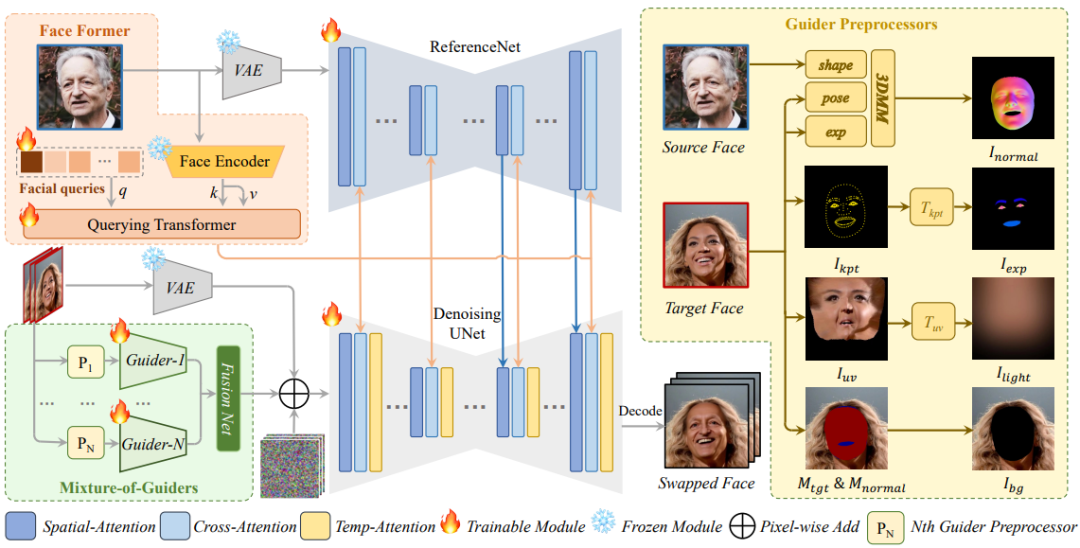
所提方法的概述。 VAE 編碼器和 ReferenceNet 從源人臉中提取詳細特征,然后通過空間注意將其合并到穩定擴散主 UNet 中。人臉編碼器使用查詢轉換器從源人臉圖像中提取高級特征,然后通過交叉注意將其注入 ReferenceNet 和主 UNet。四個可組合的人臉條件被輸入到四個專家引導器中,并在潛在空間中與融合網絡融合。時間注意旨在提高跨幀的時間一致性。在迭代去噪之后,主 UNet 的輸出由 VAE 解碼器解碼為最終的動畫視頻。
unsetunset結果unsetunset
 在 FF++ 上進行定性比較。提出的方法對于看不見的數據分布表現良好,并且還可以更好地保留身份(例如形狀和面部紋理)和包括表情和姿勢在內的運動。
在 FF++ 上進行定性比較。提出的方法對于看不見的數據分布表現良好,并且還可以更好地保留身份(例如形狀和面部紋理)和包括表情和姿勢在內的運動。
 FFHQ 上的定性比較。提出的方法可以生成具有準確身份和包含表情、姿勢和凝視的精確運動的高分辨率人臉。結果的背景也更加逼真。
FFHQ 上的定性比較。提出的方法可以生成具有準確身份和包含表情、姿勢和凝視的精確運動的高分辨率人臉。結果的背景也更加逼真。
更多結果


unsetunset結論unsetunset
論文提出了一種名為 DynamicFace 的新方法,該方法利用強大的預訓練擴散模型和精細解開的面部條件,在圖像和視頻領域實現了令人滿意的換臉效果。實驗表明,設計的面部條件可以對所需信息(例如形狀、表情、姿勢、光線和背景)提供精確而獨特的證據。已經采取了多項措施將擴散模型應用于換臉,包括 Face Former、ReferenceNet、Mixture-of-Guiders 和運動模塊。





















