30多年前的斷言打破了?大模型具備了人類水平的系統泛化能力
我們知道,人類具有「舉一反三」的能力,即學習一個新概念后立即就能用它來理解相關用法。例如,當小朋友知道如何「跳」,他們就會明白「在房間里跳兩次」是什么意思。
而對于機器來說,這種能力是極具挑戰性的。20 世紀 80 年代末,哲學家和認知科學家 Jerry Fodor 和 Zenon Pylyshyn 認為人工神經網絡缺乏系統組合的能力。幾十年來,領域內的研究人員一直在努力讓神經網絡具備一些泛化能力,但能力很有限。因此,關于 Jerry Fodor 和 Zenon Pylyshyn 的觀點的爭論也一直存在。
現在,來自紐約大學和龐培法布拉大學的研究人員聯合提出了一種稱為「組合性元學習 (Meta-learning for Compositionality,MLC) 」的新方法,該方法可以提高 ChatGPT 等工具進行組合泛化的能力。
實驗結果表明,MLC 方法不僅優于現有方法,還表現出人類水平的系統泛化(systematic generalization,SG)能力,在某些情況下甚至優于人類。組合泛化能力也是大型語言模型(LLM)有望實現通用人工智能(AGI)的基礎。
這項研究表明 AI 模型可以具備較強的組合泛化能力,具有里程碑意義。研究論文發表在《Nature》雜志上。

論文地址:https://www.nature.com/articles/s41586-023-06668-3
方法介紹
在 MLC 方法中,神經網絡會不斷更新以提高其在一系列場景(episode)中的技能。在一個場景中,MLC 會收到一個新單詞,并被要求組合使用該單詞。例如,使用單詞「jump」來創建新的單詞組合,例如「jump times」、「jump around right times」;然后 MLC 接收一個包含不同單詞的新場景,依此類推,每次都會提高神經網絡的組合技能。
如下圖所示,四個原語是從一個輸入單詞到一個輸出符號的直接映射,每個輸出符號都是一個特定顏色的圓圈。例如,「dax」對應紅色圓圈(RED),「wif」對應綠色圓圈(GREEN),「lug」對應藍色圓圈(BLUE)。「fep」、「blicket」和「kiki」是帶有參數的函數。

函數 1(fep)將前面的原語作為參數,重復其輸出其三次(例如「dax fep」是 RED RED RED);函數 2(blicket)將前面的原語和后面的原語作為參數,以特定的交替序列生成輸出(例如「wif blicket dax」是 GREEN RED GREEN);最后,函數 3(kiki)將前面和后面的字符串作為輸入,以相反的順序連接它們作為輸出(例如「dax kiki lug」為 BLUE RED)。該研究還測試了函數 3 的參數由其他函數生成的情況,例如「wif blicket dax kiki lug」為 BLUE GREEN RED GREEN)。
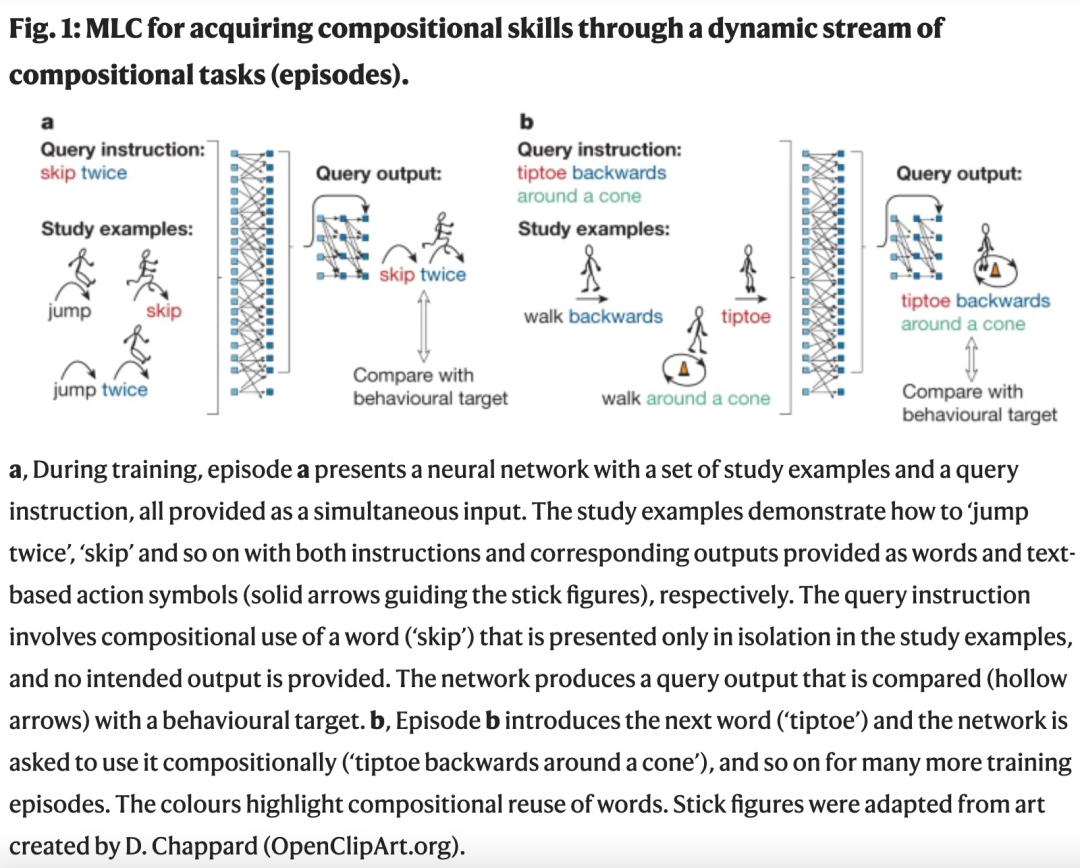
如下圖 4 所示,MLC 實現采用標準的 seq2seq transformer。該架構涉及兩個協同工作的神經網絡 —— 一個編碼器 transformer 用于處理查詢輸入和學習樣本,一個解碼器 transformer 用于生成輸出序列。編碼器和解碼器都有 3 層,每層 8 個注意力頭,輸入和隱藏嵌入大小為 128,前饋隱藏大小是 512,使用 GELU 激活函數替代 ReLU。整個架構總共有大約 140 萬個參數。
編碼器網絡(圖 4(下))負責處理一個串聯的源字符串,該字符串將查詢輸入序列與一組研究樣本(輸入 / 輸出序列對)組合在一起。解碼器網絡(圖 4(上))從編碼器接收消息并生成輸出序列。
MLC 使用標準的 transformer 架構進行基于記憶的元學習。具體來說,每個場景都會構成一個通過隨機生成的潛在語法定義的特定 seq2seq 任務。
實驗結果
為了展示 MLC 的能力,該研究在一個使用偽語言(pseudolanguage)的教學學習實驗中,將 MLC 與人類進行了比較。主要結果包括以下幾點。
人類表現出很強的系統性,但也依賴于歸納偏置,有時會偏離純粹的代數推理(algebraic reasoning)。
MLC 在實驗中實現了人類水平的系統泛化(SG)。當進行隨機響應時,MLC 還會產生類似人類的錯誤模式,例如一對一映射和圖標串聯等偏置。
MLC 在預測人類行為方面優于更嚴格的系統模型和基本的 seq2seq 模型。它在某些指標上也超過了人類的表現。聯合優化的 MLC 模型很好地捕捉了人類反應的細微差別。
MLC 通過元學習在 SCAN 和 COGS 等系統泛化基準測試中取得了較高的準確率,而 basic seq2seq 在這些測試中失敗。
該研究發現,與完美系統但嚴格的概率符號模型和完美靈活但非系統的神經網絡相比,只有 MLC 實現了模仿人類表現所需的系統泛化和靈活性。
接下來,我們看一些具體的實驗報告展示。
如上圖 2 所示,該研究給參與者 (n = 25) 提供了 14 個學習指令(輸入 / 輸出對)的課程,并要求參與者為 10 個查詢指令產生輸出。
結果顯示,在 80.7% 的情況下,參與者能夠生成與代數標準(algebraic standard )完全匹配的輸出序列(由圖 2b (i) 中的星號表示)。如果長度已知,則雙長度輸出序列的概率性能為 2.8%,而對于較長的序列則呈指數級降低。值得注意的是,在 72.5% 的情況下,參與者也正確地歸納了比訓練期間看到的更長的輸出序列 (圖 2b (i) 中的最后一個指令顯示了一個例子),這是神經網絡經常難以做到的一種泛化。
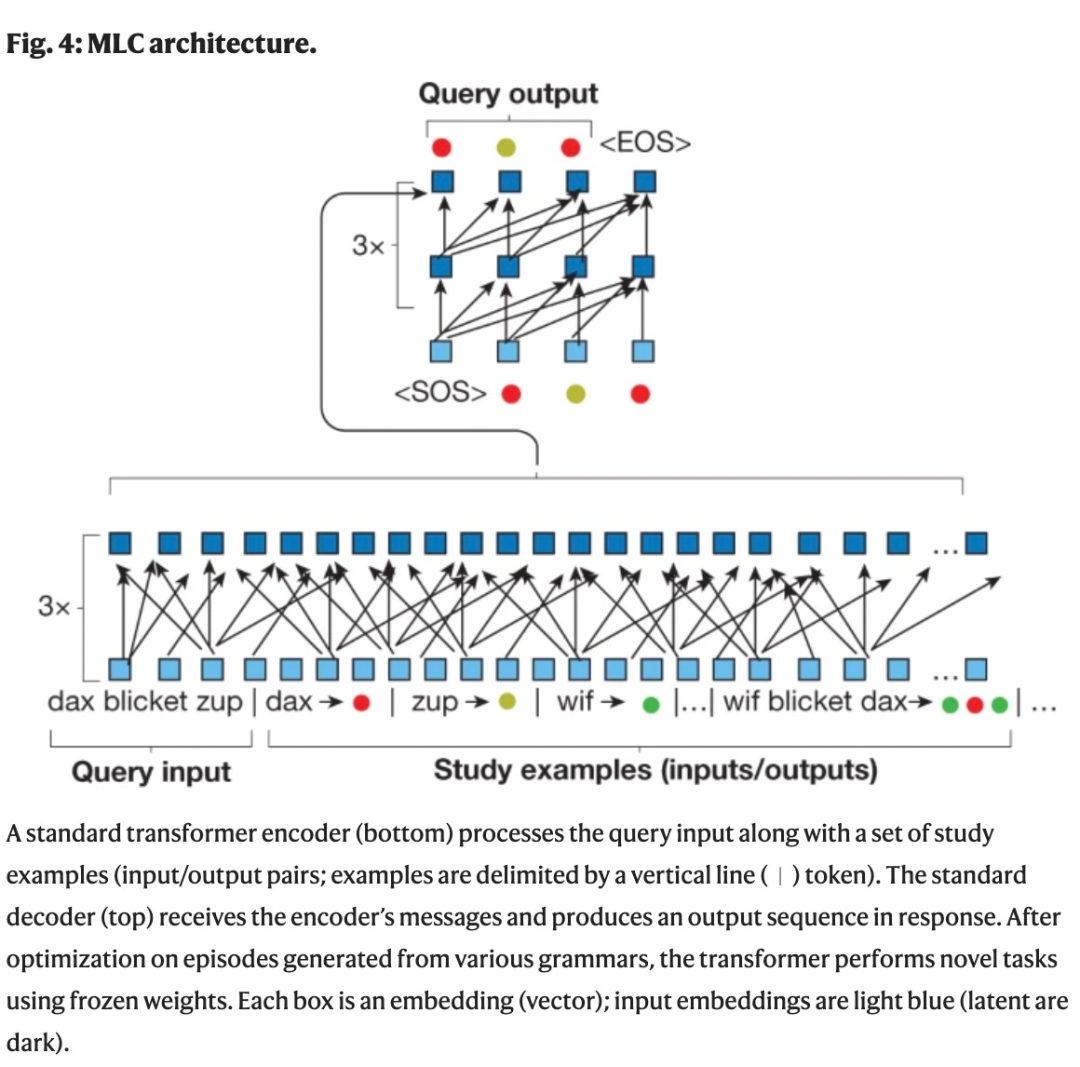
如下圖 3 是在開放式指令任務上的結果,不同的人類參與者(n=29)被要求對七個未知指令的輸出以及它們之間的關系做出合理的猜測(用一系列彩色圓圈響應 fep fep 或 fep wif),并且實驗過程中,不讓參與者看到任何的輸入、輸出示例從而影響結果。
在 29 位參與者中,有 17 位(約占 58.6%)的響應模式類似于圖 3a,b (左),這與三種歸納偏置完全一致。在所有的回答中,29 名參與者中有 18 名遵循一對一 (62.1%),29 名參與者中有 23 名 (79.3%) 遵循標志性的串聯,除了兩人之外,所有參與者都遵循相互排他性來對每個指令做出唯一的響應(29 名中的 27 名,93.1%)。
總的來說,MLC 方法通過動態的合成任務流來指導神經網絡的訓練,從而實現了模仿人類表現所需的系統泛化和靈活性。
感興趣的讀者可以閱讀論文原文,了解更多研究內容。