













用FP8訓(xùn)練大模型有多香?微軟:比BF16快64%,省42%內(nèi)存
大型語言模型(LLM)具有前所未有的語言理解和生成能力,但是解鎖這些高級的能力需要巨大的模型規(guī)模和訓(xùn)練計算量。在這種背景下,尤其是當我們關(guān)注擴展至 OpenAI 提出的超級智能 (Super Intelligence) 模型規(guī)模時,低精度訓(xùn)練是其中最有效且最關(guān)鍵的技術(shù)之一,其優(yōu)勢包括內(nèi)存占用小、訓(xùn)練速度快,通信開銷低。目前大多數(shù)訓(xùn)練框架(如 Megatron-LM、MetaSeq 和 Colossal-AI)訓(xùn)練 LLM 默認使用 FP32 全精度或者 FP16/BF16 混合精度。
但這仍然沒有推至極限:隨著英偉達 H100 GPU 的發(fā)布,F(xiàn)P8 正在成為下一代低精度表征的數(shù)據(jù)類型。理論上,相比于當前的 FP16/BF16 浮點混合精度訓(xùn)練,F(xiàn)P8 能帶來 2 倍的速度提升,節(jié)省 50% - 75% 的內(nèi)存成本和 50% - 75% 的通信成本。
盡管如此,目前對 FP8 訓(xùn)練的支持還很有限。英偉達的 Transformer Engine (TE),只將 FP8 用于 GEMM 計算,其所帶來的端到端加速、內(nèi)存和通信成本節(jié)省優(yōu)勢就非常有限了。
但現(xiàn)在微軟開源的 FP8-LM FP8 混合精度框架極大地解決了這個問題:FP8-LM 框架經(jīng)過高度優(yōu)化,在訓(xùn)練前向和后向傳遞中全程使用 FP8 格式,極大降低了系統(tǒng)的計算,顯存和通信開銷。

- 論文地址:https://arxiv.org/abs/2310.18313
- 開源框架:https://github.com/Azure/MS-AMP
實驗結(jié)果表明,在 H100 GPU 平臺上訓(xùn)練 GPT-175B 模型時, FP8-LM 混合精度訓(xùn)練框架不僅減少了 42% 的實際內(nèi)存占用,而且運行速度比廣泛采用的 BF16 框架(即 Megatron-LM)快 64%,比 Nvidia Transformer Engine 快 17%。而且在預(yù)訓(xùn)練和多個下游任務(wù)上,使用 FP8-LM 訓(xùn)練框架可以得到目前標準的 BF16 混合精度框架相似結(jié)果的模型。
在給定計算資源情況下,使用 FP8-LM 框架能夠無痛提升可訓(xùn)練的模型大小多達 2.5 倍。有研發(fā)人員在推特上熱議:如果 GPT-5 使用 FP8 訓(xùn)練,即使只使用同樣數(shù)量的 H100,模型大小也將會是 GPT-4 的 2.5 倍!
Huggingface 研發(fā)工程師調(diào)侃:「太酷啦,通過 FP8 大規(guī)模訓(xùn)練技術(shù),可以實現(xiàn)計算欺騙!」
FP8-LM 主要貢獻:
- 一個新的 FP8 混合精度訓(xùn)練框架。其能以一種附加方式逐漸解鎖 8 位的權(quán)重、梯度、優(yōu)化器和分布式訓(xùn)練,這很便于使用。這個 8 位框架可以簡單直接地替代現(xiàn)有 16/32 位混合精度方法中相應(yīng)部分,而無需對超參數(shù)和訓(xùn)練方式做任何修改。此外,微軟的這個團隊還發(fā)布了一個 PyTorch 實現(xiàn),讓用戶可通過少量代碼就實現(xiàn) 8 位低精度訓(xùn)練。?
- 一個使用 FP8 訓(xùn)練的 GPT 式模型系列。他們使用了新提出的 FP8 方案來執(zhí)行 GPT 預(yù)訓(xùn)練和微調(diào)(包括 SFT 和 RLHF),結(jié)果表明新方法在參數(shù)量從 70 億到 1750 億的各種大小的模型都頗具潛力。他們讓常用的并行計算范式都有了 FP8 支持,包括張量、流水線和序列并行化,從而讓用戶可以使用 FP8 來訓(xùn)練大型基礎(chǔ)模型。他們也以開源方式發(fā)布了首個基于 Megatron-LM 實現(xiàn)的 FP8 GPT 訓(xùn)練代碼庫。
FP8-LM 實現(xiàn)
具體來說,對于使用 FP8 來簡化混合精度和分布式訓(xùn)練的目標,他們設(shè)計了三個優(yōu)化層級。這三個層級能以一種漸進方式來逐漸整合 8 位的集體通信優(yōu)化器和分布式并行訓(xùn)練。優(yōu)化層級越高,就說明 LLM 訓(xùn)練中使用的 FP8 就越多。
此外,對于大規(guī)模訓(xùn)練(比如在數(shù)千臺 GPU 上訓(xùn)練 GPT-175B),該框架能提供 FP8 精度的低位數(shù)并行化,包括張量、訓(xùn)練流程和訓(xùn)練的并行化,這能鋪就通往下一代低精度并行訓(xùn)練的道路。
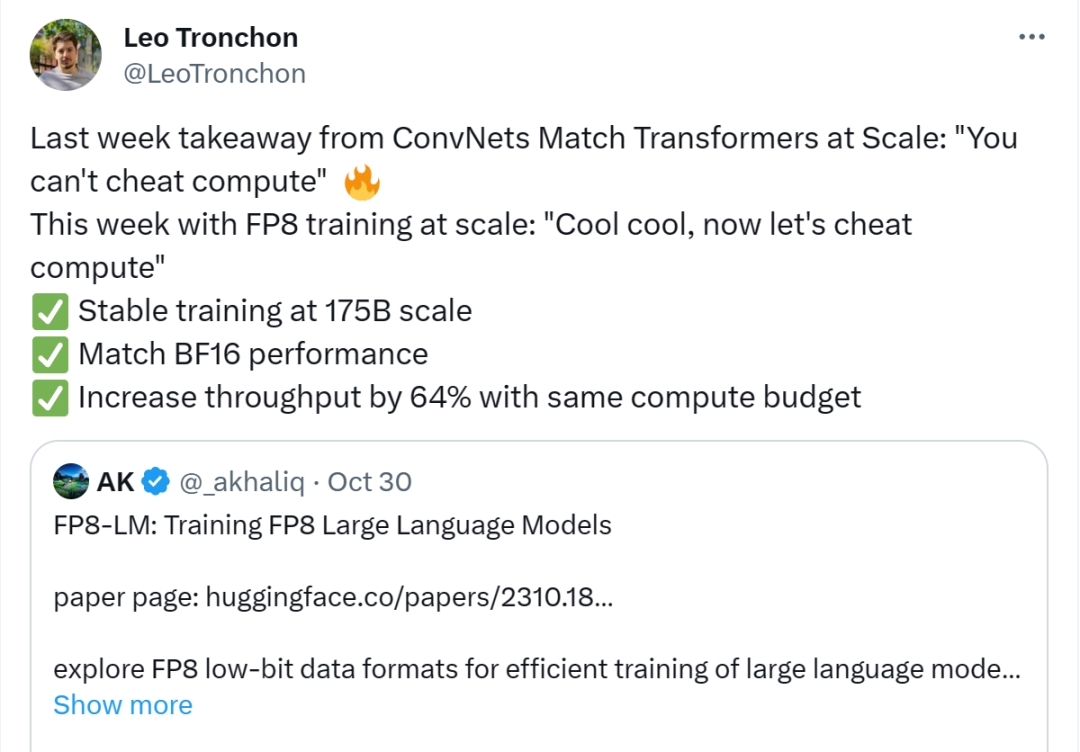
張量并行化是將一個模型的各個層分散到多臺設(shè)備上,從而將權(quán)重、梯度和激活張量的分片放在不同的 GPU 上。
為了讓張量并行化支持 FP8,微軟這個團隊的做法是將分片的權(quán)重和激活張量轉(zhuǎn)換成 FP8 格式,以便線性層計算,從而讓前向計算和后向梯度集體通信全都使用 FP8。
另一方面,序列并行化則是將輸入序列切分成多個數(shù)據(jù)塊,然后將子序列饋送到不同設(shè)備以節(jié)省激活內(nèi)存。
如圖 2 所示,在一個 Transformer 模型中的不同部分,序列并行化和張量并行化正在執(zhí)行,以充分利用可用內(nèi)存并提高訓(xùn)練效率。
而對于 ZeRO(零冗余優(yōu)化器 / Zero Redundancy Optimizer),卻無法直接應(yīng)用 FP8,因為其難以處理與 FP8 劃分有關(guān)的縮放因子。因此針對每個張量的縮放因子應(yīng)當沿著 FP8 的劃分方式分布。
為了解決這個問題,研究者實現(xiàn)了一種新的 FP8 分配方案,其可將每個張量作為一個整體分散到多臺設(shè)備上,而不是像 ZeRO 方法一樣將其切分成多個子張量。該方法是以一種貪婪的方式來處理 FP8 張量的分配,如算法 1 所示。

具體來說,該方法首先根據(jù)大小對模型狀態(tài)的張量排序,然后根據(jù)每個 GPU 的剩余內(nèi)存大小將張量分配到不同的 GPU。這種分配遵循的原則是:剩余內(nèi)存更大的 GPU 更優(yōu)先接收新分配的張量。通過這種方式,可以平滑地沿張量分配張量縮放因子,同時還能降低通信和計算復(fù)雜度。圖 3 展示了使用和不使用縮放因子時,ZeRO 張量劃分方式之間的差異。

使用 FP8 訓(xùn)練 LLM 并不容易。其中涉及到很多挑戰(zhàn)性問題,比如數(shù)據(jù)下溢或溢出;另外還有源自窄動態(tài)范圍的量化錯誤和 FP8 數(shù)據(jù)格式固有的精度下降問題。這些難題會導(dǎo)致訓(xùn)練過程中出現(xiàn)數(shù)值不穩(wěn)定問題和不可逆的分歧問題。為了解決這些問題,微軟提出了兩種技術(shù):精度解耦(precision decoupling)和自動縮放(automatic scaling),以防止關(guān)鍵信息丟失。
精度解耦
精度解耦涉及到解耦數(shù)據(jù)精度對權(quán)重、梯度、優(yōu)化器狀態(tài)等參數(shù)的影響,并將經(jīng)過約簡的精度分配給對精度不敏感的組件。
針對精度解耦,該團隊表示他們發(fā)現(xiàn)了一個指導(dǎo)原則:梯度統(tǒng)計可以使用較低的精度,而主權(quán)重必需高精度。
更具體而言,一階梯度矩可以容忍較高的量化誤差,可以配備低精度的 FP8,而二階矩則需要更高的精度。這是因為在使用 Adam 時,在模型更新期間,梯度的方向比其幅度更重要。具有張量縮放能力的 FP8 可以有效地將一階矩的分布保留成高精度張量,盡管它也會導(dǎo)致精度出現(xiàn)一定程度的下降。由于梯度值通常很小,所以為二階梯度矩計算梯度的平方可能導(dǎo)致數(shù)據(jù)下溢問題。因此,為了保留數(shù)值準確度,有必要分配更高的 16 位精度。
另一方面,他們還發(fā)現(xiàn)使用高精度來保存主權(quán)重也很關(guān)鍵。其根本原因是在訓(xùn)練過程中,權(quán)重更新有時候會變得非常大或非常小,對于主權(quán)重而言,更高的精度有助于防止權(quán)重更新時丟失信息,實現(xiàn)更穩(wěn)定和更準確的訓(xùn)練。
在該實現(xiàn)中,主權(quán)重有兩個可行選項:要么使用 FP32 全精度,要么使用帶張量縮放的 FP16。帶張量縮放的 FP16 的優(yōu)勢是能在無損于準確度的前提下節(jié)省內(nèi)存。因此,新框架的默認選擇是使用帶張量縮放的 FP16 來存儲優(yōu)化器中的主權(quán)重。在訓(xùn)練中,對于 FP8 混合精度優(yōu)化器,每個參數(shù)需要 6 個字節(jié)的內(nèi)存:
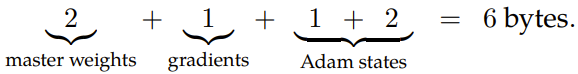
相比于之前的解決方案,這種新的低位數(shù)優(yōu)化器可將內(nèi)存足跡降低 2.6 倍。值得說明的是:這是首個用于 LLM 訓(xùn)練的 FP8 優(yōu)化器。實驗表明 FP8 優(yōu)化器能在從 1.25 億到 1750 億參數(shù)的各種模型大小下保持模型準確度。
自動縮放
自動縮放是為了將梯度值保存到 FP8 數(shù)據(jù)格式的表征范圍內(nèi),這需要動態(tài)調(diào)整張量縮放因子,由此可以減少 all-reduce 通信過程中出現(xiàn)的數(shù)據(jù)下溢和溢出問題。
具體來說,研究者引入了一個自動縮放因子 μ,其可以在訓(xùn)練過程中根據(jù)情況變化。
實驗結(jié)果
為了驗證新提出的 FP8 低精度框架,研究者實驗了用它來訓(xùn)練 GPT 式的模型,其中包括預(yù)訓(xùn)練和監(jiān)督式微調(diào)(SFT)。實驗在 Azure 云計算最新 NDv5 H100 超算平臺上進行。
實驗結(jié)果表明新提出的 FP8 方法是有效的:相比于之前廣泛使用 BF16 混合精度訓(xùn)練方法,新方法優(yōu)勢明顯,包括真實內(nèi)存用量下降了 27%-42%(比如對于 GPT-7B 模型下降了 27%,對于 GPT-175B 模型則下降了 42%);權(quán)重梯度通信開銷更是下降了 63%-65%。

不修改學(xué)習(xí)率和權(quán)重衰減等任何超參數(shù),不管是預(yù)訓(xùn)練任務(wù)還是下游任務(wù),使用 FP8 訓(xùn)練的模型與使用 BF16 高精度訓(xùn)練的模型的表現(xiàn)相當。值得注意的是,在 GPT-175B 模型的訓(xùn)練期間,相比于 TE 方法,在 H100 GPU 平臺上,新提出的 FP8 混合精度框架可將訓(xùn)練時間減少 17%,同時內(nèi)存占用少 21%。更重要的是,隨著模型規(guī)模繼續(xù)擴展,通過使用低精度的 FP8 還能進一步降低成本,如圖 1 所示。

對于微調(diào),他們使用了 FP8 混合精度來進行指令微調(diào),并使用了使用人類反饋的強化學(xué)習(xí)(RLHF)來更好地將預(yù)訓(xùn)練后的 LLM 與終端任務(wù)和用戶偏好對齊。 
結(jié)果發(fā)現(xiàn),在 AlpacaEval 和 MT-Bench 基準上,使用 FP8 混合精度微調(diào)的模型與使用半精度 BF16 微調(diào)的模型的性能相當,而使用 FP8 的訓(xùn)練速度還快 27%。此外,F(xiàn)P8 混合精度在 RLHF 方面也展現(xiàn)出了巨大的潛力,該過程需要在訓(xùn)練期間加載多個模型。通過在訓(xùn)練中使用 FP8,流行的 RLHF 框架 AlpacaFarm 可將模型權(quán)重減少 46%,將優(yōu)化器狀態(tài)的內(nèi)存消耗減少 62%。這能進一步展現(xiàn)新提出的 FP8 低精度訓(xùn)練框架的多功能性和適應(yīng)性。
他們也進行了消融實驗,驗證了各組件的有效性。
可預(yù)見,F(xiàn)P8 低精度訓(xùn)練將成為未來大模型研發(fā)的新基建。
更多細節(jié)請參見原論文。




























