FP8 訓練新范式:減少 40% 顯存占用,訓練速度提高 1.4 倍
近期DeepSeek V3 引爆國內外的社交媒體,他們在訓練中成功應用了 FP8 精度,顯著降低了 GPU 內存使用和計算開銷。這表明,FP8 量化技術在優化大型模型訓練方面正發揮著越來越重要的作用。

近期,來自伯克利,英偉達,MIT 和清華的研究者們提出了顯存高效的 FP8 訓練方法:COAT(Compressing Optimizer states and Activation for Memory-Efficient FP8 Training),致力于通過 FP8 量化來壓縮優化器狀態和激活值,從而提高內存利用率和訓練速度。COAT 實現了端到端內存占用減少 1.54 倍,端到端訓練速度提高 1.43 倍,同時保持模型精度。它還可以使訓練批次大小加倍,從而更好地利用 GPU 資源。通過利用 FP8 精度,COAT 使大型模型的高效全參數訓練在更少的 GPU 上成為可能,并有助于在分布式訓練環境中加倍批次大小,為大規模模型訓練的擴展提供了實用的解決方案。最重要的是,他們的訓練代碼完全開源。
論文第一作者席浩誠本科畢業于清華大學姚班,目前在伯克利攻讀博士學位,他在英偉達實習期間完成了這篇工作。論文共同通訊作者為 MIT 韓松副教授和清華大學陳鍵飛副教授。

- 論文標題:COAT: Compressing Optimizer States and Activation for memory efficient FP8 Training
- 論文鏈接:https://arxiv.org/abs/2410.19313
- 開源代碼:https://github.com/NVlabs/COAT
一、FP8 優化器狀態
1. FP8 量化優化器狀態的難點
論文作者發現,當前的量化方法無法充分利用 FP8 的表示范圍,因此在使用每組量化(per-group quantization)對優化器狀態進行量化時會導致較大的量化誤差。對于 FP8 的 E4M3 格式,我們希望量化組 X 的動態范圍覆蓋 E4M3 的最小可表示值(0.00195)和最大可表示值(448)之間的整個跨度,以充分利用其表示能力。然而,E4M3 的動態范圍通常未被充分利用:E4M3 的動態范圍約為 200000,但一階動量的每個量化組的最大值最小值之比通常為 1000,二階動量的該比值則通常為 10,遠小于 E4M3 的動態范圍。這使得用 FP8 來量化優化器狀態的誤差非常大。

2. 解決方案:動態范圍擴展
論文作者發現,在量化之前引入一個擴展函數 f (?),能夠擴大量化組的動態范圍,并使其與 E4M3 對齊。使用的擴展函數為:

其中,k 是即時計算的參數,每個量化組共享一個 k。當 k > 1 時,動態范圍將被擴大,并更接近 E4M3 的動態范圍。在每一步訓練中,都可以即時的計算出最優的 k,從而可以充分利用 E4M3 的表示范圍,而原始的量化方法只能利用其中的一小部分。

動態范圍擴展方法可以大大減少量化誤差,并充分利用 E4M3 的動態范圍。除此之外,還發現,E4M3 比 E5M2 更適合一階動量。而對于二階動量,雖然在原始設置中 E4M3 優于 E5M2,但在應用我們的擴展函數后,它們的量化誤差幾乎相同。因此,建議在量化優化器狀態時使用 E4M3 + E4M3 量化策略或 E4M3 + E5M2 量化策略。

二、FP8 激活
1. 動機:非線性層占用大量內存
在語言模型的前向傳播中,必須保留激活值以用于反向傳播計算梯度。在 Llama 模型系列中,非線性層通常占內存占用的約 50%。相比之下,線性層的貢獻不到 25%。因此,優化線性和非線性層以減少激活內存占用至關重要。

2. 解決方案:混合粒度 FP8 精度流
FP8 精度流要求所有線性和非線性層的輸入和輸出采用 FP8 格式。通過直接以 FP8 格式保存輸入張量用于反向傳播,這消除了額外的量化操作需求,從而減少了相關開銷。FP8 精度流自然地將非線性和線性層的內存占用減少了 50%,因為它們只需要保存 FP8 激活值,而不是 BF16。為了進一步提高該方法的準確性,作者提出在不同層中變化量化粒度,以混合粒度的方式平衡精度和效率。
三、實驗結果
COAT 在多個任務中展示了其在內存占用和訓練速度方面的優勢,同時保持了模型性能。
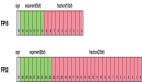
1. 訓練加速 1.43 倍,顯存降低 1.54 倍
在使用 4 張 H100 訓練 Llama-2-13B 模型時,COAT 將每個 GPU 的內存占用從 BF16 的 76.1GB 減少到 49.1GB,實現了 1.54 倍的內存縮減。同時,COAT 將訓練速度從 BF16 的每秒 2345 個 token 提升至每秒 5295 個 token,達到 1.43 倍的加速。在幾乎所有的訓練場景下,COAT 都能夠使 Batch Size 翻倍,或是讓訓練所需的卡數減小。

2. 訓練完全不掉點,FP8 訓練表現和 BF16 吻合
COAT 在各種應用場景下,均展現出了出色的精度,完全不會導致模型性能下降。例如,在大語言模型預訓練任務中,COAT 可以保持近乎無損的模型性能,訓練中的 loss 曲線也和 BF16 完全吻合。

COAT 在視覺語言模型微調中同樣實現了和 BF16 訓練完全一致的表現。無論是 loss 曲線,還是下游任務上的表現,COAT 均和 BF16 基準相持平。

在一些實際的下游任務例子中,經過 COAT 訓練過的模型也有著相當優秀的生成和總結能力。

四、總結
COAT 的核心價值在于使用 FP8 進行訓練的同時做到了顯存優化。動態范圍擴展減少量化誤差,混合粒度量化優化激活存儲,兩者協同作用使得端到端內存占用降低 1.54 倍。這種優化不僅適用于單機訓練,更在分布式訓練中發揮關鍵作用 —— 通過批量大小翻倍,可在相同硬件條件下處理更多數據,顯著提升訓練效率。而對于顯存資源緊張的研究者,COAT 也提供了全參數訓練的可行路徑,降低了大模型訓練的門檻。