













GPT-4能「偽裝」成人類嗎?圖靈測試結果出爐
「機器能夠思考嗎?」
為了解答這個問題,圖靈設計了一個能間接提供答案的模仿游戲。該游戲的最初設計涉及到兩位見證者(witness)和一位審問者(interrogator)。兩位見證者一個是人類,另一個是人工智能;他們的目標是通過一個純文本的交互接口說服審問者相信他們是人類。這個游戲本質上是開放性的,因為審問者可以提出任何問題,不管是關于浪漫愛情,抑或是數學問題。圖靈認為這一性質能夠對機器的智能進行廣泛的測試。
后來這個游戲被稱為圖靈測試(Turing Test),但人們也在不斷爭論這一測試究竟測算的是什么以及哪些系統(tǒng)有能力通過它。
以 GPT-4 為代表的大型語言模型(LLM)簡直就像是專為圖靈測試而生的!它們能生成流暢自然的文本,并且在許多語言相關的任務上都已達到比肩人類的水平。實際上,已經有不少人在猜測 GPT-4 也許能夠通過圖靈測試了。
近日,加利福尼亞大學圣迭戈分校的研究者 Cameron Jones 和 Benjamin Bergen 發(fā)布了一份研究報告,給出了他們對 GPT-4 等 AI 智能體進行圖靈測試的實證研究結果。

論文地址:https://arxiv.org/pdf/2310.20216.pdf
但在介紹這份研究的結果之前,需要說明的是,圖靈測試究竟能否作為衡量智能水平的標準一直以來都頗具爭議。
但 Jones 和 Bergen 認為圖靈測試還是值得研究的,他們給出了兩點理由:
一、圖靈測試衡量的是AI 系統(tǒng)能否欺騙對話者使之相信它是人類,這項能力本身是值得評估的。因為創(chuàng)造「偽人」可能會對社會產生巨大的影響,包括實現面向客戶的工作崗位自動化、更低成本更高效地制造虛假信息、使用非對齊的 AI 模型從事欺詐活動、讓人類不再相信人與人之間的真實互動。圖靈測試能讓人穩(wěn)健地跟蹤模型的這種能力隨時間的變化情況。此外,它還能讓人理解哪些因素有助于欺騙,比如模型大小和性能、prompt 設計技術、輔助性基礎設施(例如訪問實時信息的能力)以及審問者的經驗和技能。
二、圖靈測試能提供一個幫助研究人類和類人智能的框架。圖靈測試不僅僅是評估機器;它也會涉及對人類參與者的文化、道德倫理和心理狀態(tài)的假設。當審問者設計并完善問題時,他們也會隱含地揭示自己的信念 —— 人類有哪些特質以及哪些特質最難模仿。為此,研究者以定性方式分析了參與者設計問題的策略和理由依據,以為這些信念提供一個經驗性的描述。
Cameron Jones 和 Benjamin Bergen 在 652 位人類參與者的幫助下檢驗了 GPT-4 模仿人類的能力,結果發(fā)現表現最好的設置能達到 41% 的成功率,還不及隨機亂猜,更不及人類水平的 63%,因此可認為 GPT-4 未能通過圖靈測試。他們還在測試過程中得到了一些驚人發(fā)現和有趣推斷,比如誕生于 1966 年的規(guī)則式系統(tǒng) ELIZA 的表現比 GPT-3.5 更好、AI 不犯錯或犯錯過多都容易暴露自己。
方法
在具體的圖靈測試實驗中,研究者采用了雙玩家設置,即審問者對一位見證者提問,然后說明他認為對方是人類還是 AI。
見證者
研究者創(chuàng)建了 25 個 LLM 見證者,它們使用 OpenAI API 響應用戶查詢。每個 LLM 見證者都包含一個模型(GPT-3.5 或 GPT-4)、一個溫度值(0.2、0.5 或 1.0)和一個 prompt。prompt 描述了交互的上下文以及對于智能體響應方式的指令,如圖 2 所示。、

交互界面
研究者將聊天界面設計成了一個聊天軟件的樣子,如圖 1 所示。審問者發(fā)送第一條消息,每位用戶每次只能發(fā)送一條消息。對話整體限時 5 分鐘,每條消息最多 300 個字符。

流程
參與者是通過社交媒體在網上招募的。
參與者會先進入一個在線等候室,然后被隨機分配與 AI 或另一個人類對話。AI 在響應時有一個等待時間,具體是最近 5 對人類參與者所用的平均等待時間,以防止審問者將等待時間視為一個評估指標。
當隨機配對的是兩個人類時,則隨機分配審問者和見證者角色。見證者得到的指令是說服審問者相信他們是人類。當人類與 AI 匹配時,則人類必定是審問者。
AI 模型的選取使用了「探索 / 利用」策略。對于每個模型,都從以下分布中選取一個樣本:

其中 N 是模型數量,α 和 β 分別是模型在游戲過程中的勝負次數并依照審問者對每個判定結果的信心度加權。最后選擇得到了最高樣本值的模型。
結果
實驗共有 652 位參與者參加,總共完成了 1810 場游戲。其中 389 場游戲被移出最終結果,因為這些場之前審問者已經連續(xù)三次與 AI 對話了,這種情況說明此時只有一個人類在線。用戶反饋表明,這種情況會導致審問者產生一個先驗信念 —— 相信見證者不是人類。另外還有 11 場游戲被移除的原因是審問者表示他們私下認識對話的人類見證者。
最終結果基于剩余的 1405 場游戲,其中 260 場有人類見證者參與。
51% 的參與者只玩了一場游戲,91% 的參與者少于 4 場。
游戲平均時長為 187 秒(σ = 95.3),平均消息數為 8(σ = 5.16),平均詞數為 320(σ = 210)。
下圖展示了一些游戲示例:

成功率
成功率(SR)的定義是審問者認為一個見證者是人類(即見證者成功)的游戲場數的比例。人類見證者的表現最好,成功率為 63%(見圖 4)。

表現最好的 GPT-4 prompt(Sierra)的成功率為 41%,也有其它幾個表現相近的 GPT-4 prompt(November 為 40%,Papa 為 36%)。但是,從圖中也可看出,不同 prompt 的表現差異很大。
GPT-3.5 的成功率只有 5% (Victor) 到 14% (Juliet)。而 1966 年誕生的基于規(guī)則的 ELIZA 反倒實現了 27% 的成功率,甚至超過一些 GPT-4 prompt。
不過需要注意的是,由于整體游戲場數較少,某些 prompt 被調用的次數還格外少,比如 Victor (GPT-3.5) 僅被采樣了 21 次(見表 1),因此成功率結果并不非常可靠。

審問者的人口學信息
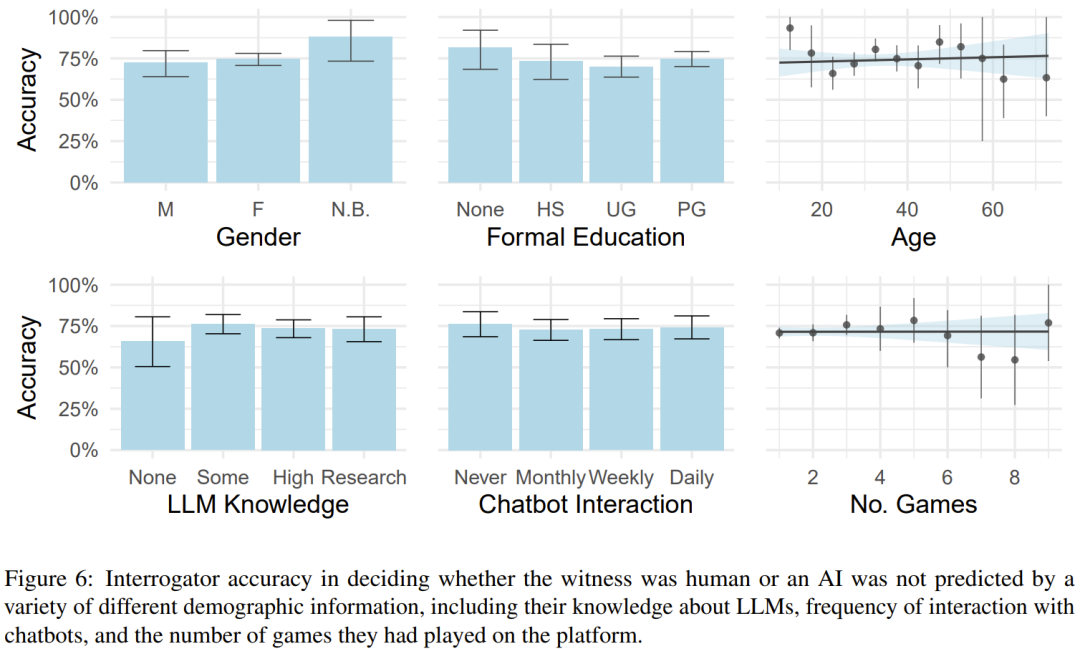
我們知道人口學因素(比如年齡、性別和教育水平)會對人機交互產生影響,而研究者也測試了是否可通過這些因素來預測審問者的辨別能力。
但他們表示并未發(fā)現這些因素對準確度有明顯影響。這里的準確度是指審問者正確猜出對方是人類或 AI 的比例,見圖 6。
策略
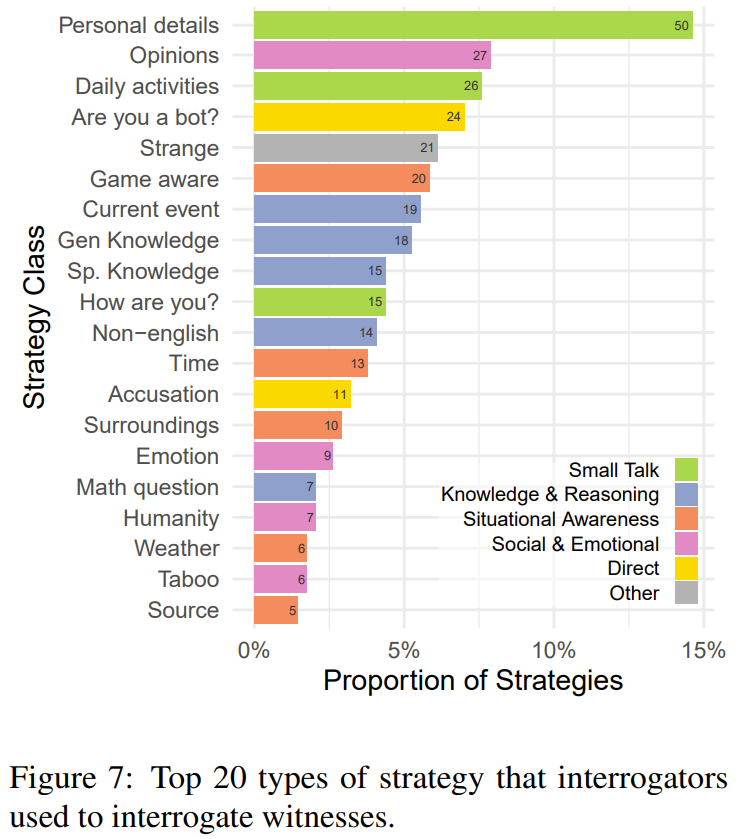
研究者基于 300 場游戲樣本,對審問者采用的策略進行了分類。
圖 7 給出了被使用最多的 20 種策略。其中最常見的策略是閑聊(27%),也就是問見證者的日常生活和個人細節(jié)。
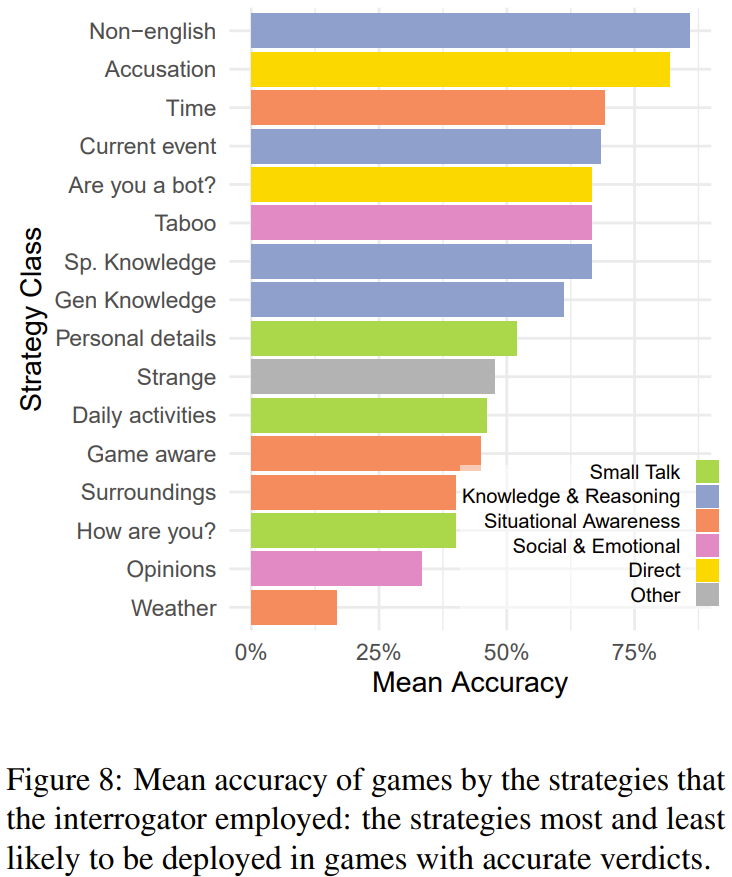
研究者分析了不同策略的有效性,給出了使用不同策略時的平均準確度(見圖 8),可以看到,最可能成功的策略是讓見證者說外語、詢問時間或時事以及直接詢問對方是不是 AI 或宣稱對方是 AI。
判斷的理由或依據
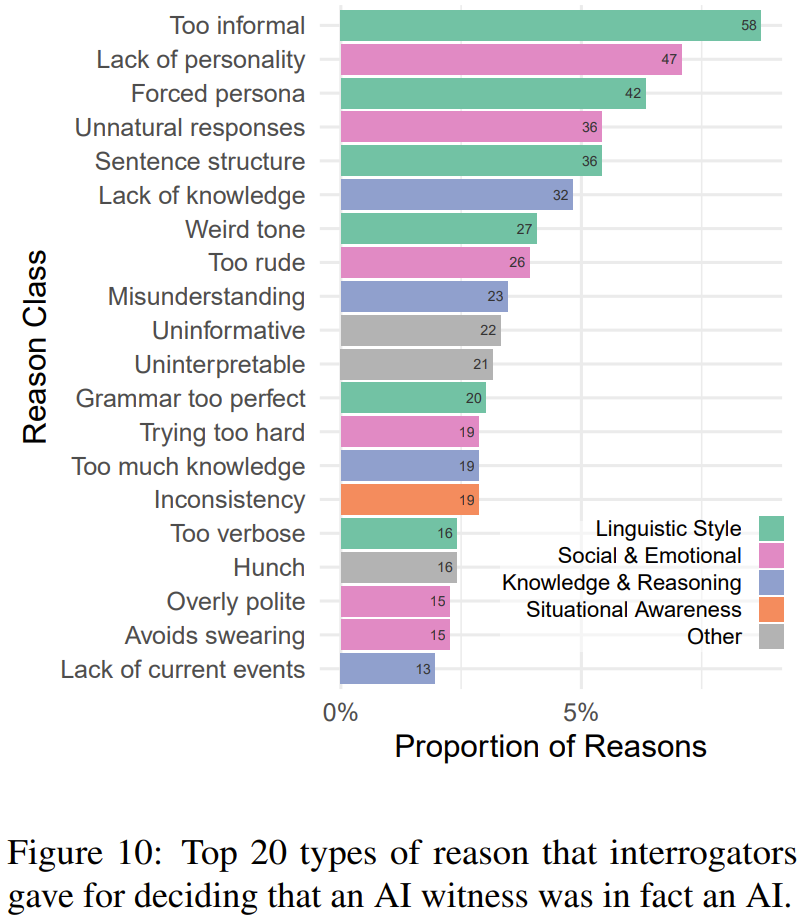
一些參與者提供了判斷的理由或依據,研究者將它們分成了 6 大類別:語言風格、社交和情感、知識和內容、情境感知能力、元信息(模型控制范圍外的游戲方面)、無信息(模糊或不相關的原因)。圖 10 給出了審問者判斷時最常采用的 20 個理由。
討論
GPT-4 通過了圖靈測試嗎?
這里的結果表明,一些 GPT-4 見證者滿足圖靈設定的標準,即 30% 的時間騙過審問者,使其判斷錯誤。但是,以 30% 為標準斷言成功恐怕并不合適。更常用的基準應該是 50%。這可以表明審問者在一般情況下無法區(qū)分 AI 模型和人類。但這一基準也有個缺陷:隨機亂猜也能達到 50% 的成功率。
研究者表示,如果要更嚴格的測試,那么至少應該要求 AI 見證者被認為是人類的頻率與人類見證者被認為是人類的頻率一樣高。也就是說 AI 見證者在圖靈測試中的表現應當與人類一樣好。但研究者又討論說這種比較可能對 AI 來說并不公平,因為 AI 必須欺騙審問者,而人類只需說實話即可。
更保守的方案是要求 AI 系統(tǒng)的表現顯著超過隨機亂猜或人類基準。從理論上講,這個標準高得沒有必要。而從實踐角度看,用頻率統(tǒng)計來展示圖靈測試結果可能是最簡單的方法。
這里測試的所有 AI 見證者都沒達到 50% 的成功率,更不及人類水平(63%)了。因此,對于這里使用的 prompt,可以判定 GPT-4 沒能通過圖靈測試。
GPT-4 能通過圖靈測試嗎?
從圖 4 可以看到,不同 prompt 得到的結果的差異很大。
研究者猜想:考慮到實驗中探索的 prompt 有限,也許存在某個 prompt 能使 GPT-4 的成功率超過 50% 或人類基準。此外,一些輔助審問者判斷見證者是 AI 的理由依據實際上很容易改正和解決,比如給出的信息過于充分、使用重復性的句子結構以及回避禁忌話題。
不過,prompt 工程設計的難度可不小。研究者談到了自己的經驗:在設計這些 prompt 時,為了解決一個問題所做的改變往往會引入新的指示因素,說明該系統(tǒng)不是人類。
其中表現最好的一些能達到 40% 左右的成功率。這一數值與另一項研究報告《Human or Not? A Gamified Approach to the Turing Test》的結果相近,因此可以認為這能代表當前 LLM 的能力。
訊問者人口學信息
令人驚訝的是,這里收集的人口學統(tǒng)計數據(包括與聊天機器人互動的頻率、有關 LLM 的知識水平和所玩游戲的場數)對審問者的準確度沒有任何顯著影響。這說明與 LLM 的交互經驗可能無助于區(qū)分 LLM 和人類。
對此,研究者給出了可能的解釋:他們在設計 prompt 時為了使 LLM 給出的答案接近人類的答案,在冗長性、正式性、是否禮貌、拼寫和語法錯誤方面都有專門設計。要是參與者原本很熟悉 LLM 的典型互動模式,可能會對這些聊天機器人給出的結果感到驚訝,因此之前的經驗在這里就用不上了。
另一個可能的解釋是選擇性偏差。由于參與者是通過社交媒體招募的,因此占大多數的是 20-30 歲、接受過研究生教育且對 LLM 感興趣的男性。
ELIZA 效應
ELIZA 相對的成功也出乎了研究者的意料,畢竟這個聊天機器人采用的是基于規(guī)則的技術,并且誕生于 1966 年。ELIZA 組合使用了模式匹配和替換,可以根據從用戶輸入中提取的關鍵內容和模板生成響應。
盡管如此,ELIZA 卻在 27% 的游戲中騙過了人類審問者,超過了一些 GPT-4 見證者和所有 GPT-3.5 見證者。
這樣的結果可以佐證:圖靈測試確實不能精準地衡量智能水平。
策略
審問者采用了大量不同策略來辨別 AI 模型,這展現了圖靈測試作為一種交互式評估方法的靈活性。很多參與者采用的策略是閑聊,但 AI 模型其實非常擅長模仿這些典型類型的人類對話,因此閑聊并不是一個很有效的策略。
最有效的策略是使用外語,因為審問者會假定如果回答很專業(yè),那就更可能是來自多語言語言模型。另一個有效的策略是詢問當前的時間和發(fā)生的事件。盡管 prompt 中包含 UTC 標準的時間戳,但模型往往在轉換時區(qū)時出錯。
許多審問者會直接問對方是不是 AI。雖然 AI 會給出否定答案,但這個策略卻相當有效。因為 AI 模型在說服審問者相信它們是人類時往往會「用力過猛」,而人類通常會給出隨意即興的回答。
判斷的理由或依據
審問者在做出正確判斷時所給出的理由中往往有語言風格一項。因為盡管 LLM 的訓練語料中包含大量不同風格的文本,但生成與語境風格一致的內容還依然是一大難題。審問者會發(fā)現 AI 模型生成的結果要么過于正式,要么就過于不正式;語法要么太好,要么就糟糕得不真實;要么過于冗長,要么就過于簡練。
這可能表明:1)在這種相當不尋常的語境中,適當的風格其實很微妙;2)不同的審問者對風格有不同的預期:沒有一種風格能夠說服每個審問者。
第二個最常見的原因類別是社交和情感。LLM 學習的是生成完備的響應,并且經過微調以避免生成自相矛盾的結果。這些過程可能會鼓勵模型生成一般化的典型響應,但也因此缺乏個性,這也算是一種生態(tài)謬誤(ecological fallacy)。
值得注意的是,很少有原因與見證者的知識或推理能力有關,這進一步證明經典意義上的智能不足以通過圖靈測試。判斷理由的分布還說明現在的 LLM 模型已經足夠智能了,因此社會 - 感情和語言風格才成為了審問者更看重的因素。當然也可能是因為這些線索一般來說可能更明顯,因此對于尚未掌握這些能力的模型,可以將這些線索用作判斷理由。
結論
人們普遍認為圖靈測試并非是一種完美的衡量智能的方法:要么太容易,要么太困難。Cameron Jones 和 Benjamin Bergen 在這個實證研究中找到了分別支持這兩種觀點的證據。
最終,他們認為 GPT-4 沒能通過圖靈測試。
盡管如此,41% 的成功率也表明使用 AI 模型來進行欺詐已經有可能實現,尤其是當人類對話者沒有提防對方可能并非人類時。
如果 AI 模型能夠穩(wěn)健地假裝成人類,可能會造成廣泛的社會和經濟后果。隨著 AI 模型能力日益增強,識別導致欺騙成功的因素并找到應對策略也會變得越來越重要。






























