













用GPT-2監(jiān)督GPT-4,防止AI毀滅人類(lèi)? OpenAI Ilya超級(jí)對(duì)齊團(tuán)隊(duì)首篇論文出爐
就在剛剛,OpenAI首席科學(xué)家Ilya領(lǐng)銜的超級(jí)對(duì)齊團(tuán)隊(duì),發(fā)布了成立以來(lái)的首篇論文!

團(tuán)隊(duì)聲稱(chēng),已經(jīng)發(fā)現(xiàn)了對(duì)超人類(lèi)模型進(jìn)行實(shí)證對(duì)齊的新研究方向。
未來(lái)超級(jí)AI系統(tǒng)對(duì)齊的一個(gè)核心挑戰(zhàn)——人類(lèi)需要監(jiān)督比自己更聰明人工智能系統(tǒng)。
OpenAI的最新研究做了一個(gè)簡(jiǎn)單的類(lèi)比:小模型可以監(jiān)督大模型嗎?

論文地址:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
經(jīng)驗(yàn)證,通過(guò)GPT-2可以激發(fā)出GPT-4的大部分能力(接近GPT-3.5的性能),甚至可以正確地泛化到小模型失敗的難題上。
OpenAI此舉開(kāi)辟了一個(gè)新的研究方向,讓我們能夠直接解決一個(gè)核心挑戰(zhàn),即調(diào)整未來(lái)的超級(jí)AI模型,同時(shí)在迭代的實(shí)證中取得進(jìn)展。
為了便于大家理解,超級(jí)對(duì)齊共同負(fù)責(zé)人Jan Leike,也發(fā)表了對(duì)這項(xiàng)研究的簡(jiǎn)要概括:

人類(lèi)如何控制比自己更智能的AI?
OpenAI認(rèn)為,超級(jí)智能(比人類(lèi)聰明得多的人工智能),很可能在未來(lái)十年內(nèi)出現(xiàn)。
然而,人類(lèi)卻仍然不知道,該如何可靠地引導(dǎo)和控制超人AI系統(tǒng)。
這個(gè)問(wèn)題,對(duì)于確保未來(lái)最先進(jìn)的AI系統(tǒng)安全且造福人類(lèi),是至關(guān)重要的。
解決這個(gè)問(wèn)題對(duì)于確保未來(lái)最先進(jìn)的人工智能系統(tǒng)仍然安全并造福人類(lèi)至關(guān)重要。

為此,今年7月OpenAI成立了「超級(jí)對(duì)齊團(tuán)隊(duì)」,來(lái)解決這類(lèi)超級(jí)智能的對(duì)齊難題。
5個(gè)月后,團(tuán)隊(duì)發(fā)表第一篇論文,介紹了實(shí)證對(duì)齊超人模型的新研究方向。
當(dāng)前的對(duì)齊方法,例如基于人類(lèi)反饋的強(qiáng)化學(xué)習(xí) (RLHF),非常依賴(lài)于人類(lèi)的監(jiān)督。
但未來(lái)的人工智能系統(tǒng),顯然能夠做出極其復(fù)雜且極具創(chuàng)造性的行為,而這將使人類(lèi)很難對(duì)其進(jìn)行可靠的監(jiān)督。
比如,超人模型寫(xiě)出了數(shù)百萬(wàn)行新穎的且具有潛在危險(xiǎn)的計(jì)算機(jī)代碼,即便是專(zhuān)業(yè)人士也難以完全理解,這時(shí)人類(lèi)該怎么辦呢?
可見(jiàn),相比于超人的AI模型,人類(lèi)將成為一個(gè)「弱監(jiān)督者」。
而這正是AGI對(duì)齊的核心挑戰(zhàn)——「弱小」的人類(lèi),如何信任并控制比他們更智能的AI系統(tǒng)?
超級(jí)對(duì)齊:用小模型監(jiān)督大模型?
為了在這個(gè)核心挑戰(zhàn)上取得進(jìn)展,OpenAI提出了一可以實(shí)證研究的類(lèi)比:能否用一個(gè)更小(能力較弱)的模型來(lái)監(jiān)督一個(gè)更大(能力更強(qiáng))的模型?

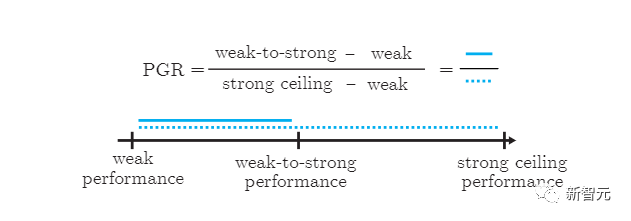
超級(jí)對(duì)齊的簡(jiǎn)單類(lèi)比:在傳統(tǒng)的ML中,人類(lèi)監(jiān)督的人工智能系統(tǒng)比自己弱(左)。為了對(duì)齊超級(jí)智能,人類(lèi)將需要監(jiān)督比他們更聰明的人工智能系統(tǒng)(中)。我們今天無(wú)法直接研究這個(gè)問(wèn)題,但我們可以研究一個(gè)簡(jiǎn)單的類(lèi)比:小模型能否監(jiān)督大模型(右圖)?
我們可能會(huì)天真的認(rèn)為,一個(gè)強(qiáng)大的模型不會(huì)比提供訓(xùn)練信號(hào)的弱監(jiān)督表現(xiàn)得更好。它可能只是學(xué)會(huì)模仿弱監(jiān)督所犯的所有錯(cuò)誤。
另一方面,強(qiáng)大的預(yù)訓(xùn)練模型具有出色的原始能力——不需要從頭開(kāi)始教它們新任務(wù),只需要引出其潛在知識(shí)。
那么關(guān)鍵的問(wèn)題是:強(qiáng)模型是否會(huì)根據(jù)弱監(jiān)督的潛在意圖進(jìn)行泛化,利用其全部能力來(lái)解決任務(wù),即使是在弱監(jiān)督只能提供不完整或有缺陷的訓(xùn)練標(biāo)簽的難題上?
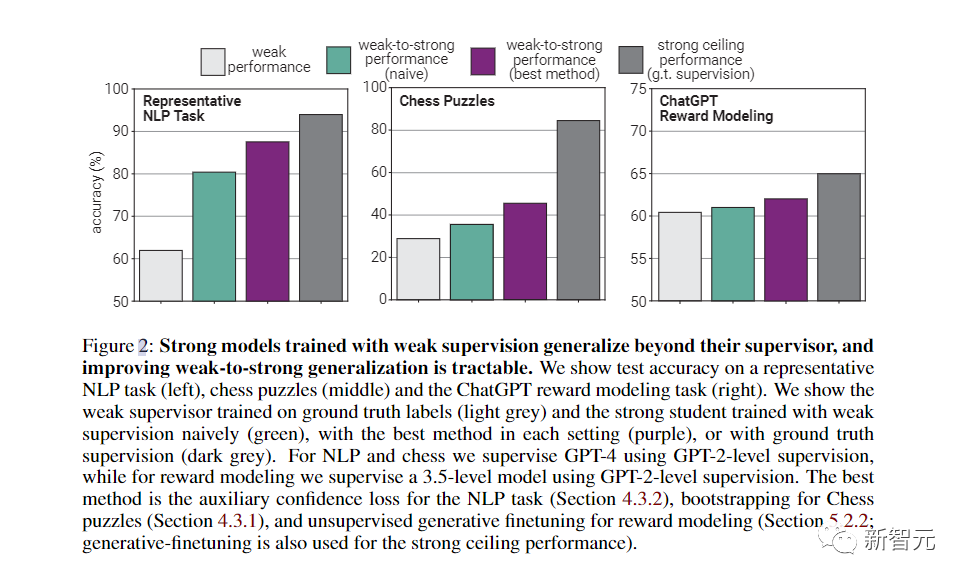
團(tuán)隊(duì)放出首個(gè)成果:用GPT-2監(jiān)督GPT-4
對(duì)此,團(tuán)隊(duì)使用了NLP基準(zhǔn)測(cè)試的典型弱到強(qiáng)泛化——用GPT-2級(jí)別的模型作為弱監(jiān)督,來(lái)微調(diào)GPT-4。
在很多情況下,這種方法都能顯著提高泛化能力。
使用一種簡(jiǎn)單的方法,就鼓勵(lì)性能更強(qiáng)的模型更加自信,包括在必要時(shí)自信地說(shuō)出與弱監(jiān)督意見(jiàn)不同的意見(jiàn)。
在NLP任務(wù)上使用這種方法用GPT-2級(jí)模型監(jiān)督GPT-4時(shí),生成的模型通常在GPT-3和GPT-3.5之間。
而在更弱的監(jiān)督下,就可以恢復(fù)GPT-4的大部分功能。
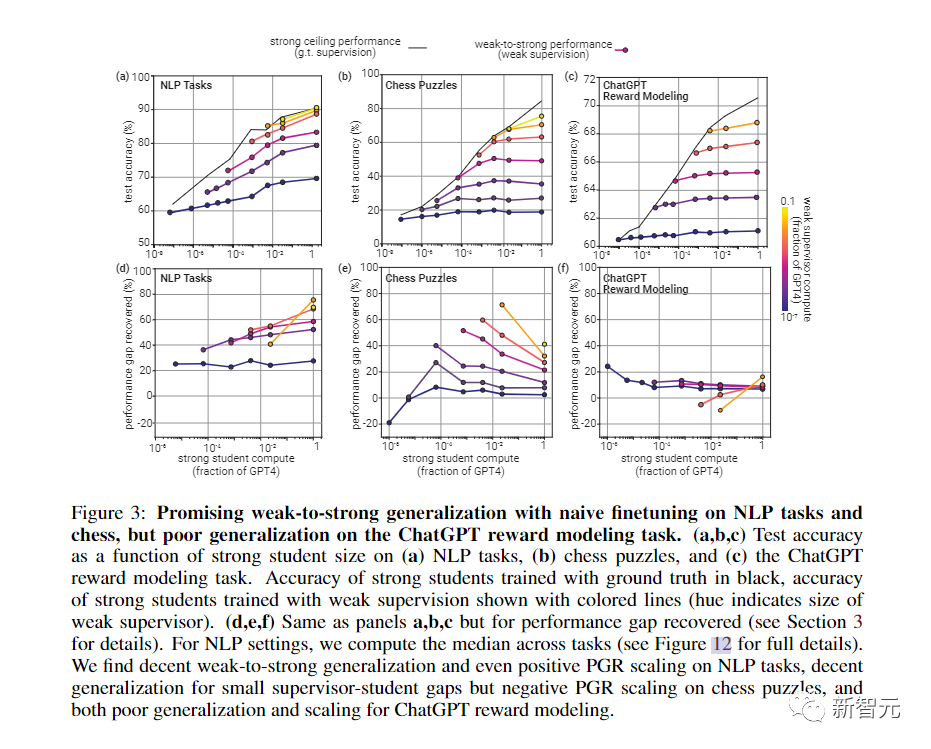
當(dāng)然,這種方法更像是概念證明,具有很多局限性,比如,它并不適用于ChatGPT偏好數(shù)據(jù)。
不過(guò),團(tuán)隊(duì)也發(fā)現(xiàn)了其他方法,比如最佳的早期停止和從小型到中型再到大型模型的引導(dǎo)。
總的來(lái)說(shuō),結(jié)果表明,(1)幼稚的人類(lèi)監(jiān)督(比如RLHF)可以在沒(méi)有進(jìn)一步工作的情況下。很好地?cái)U(kuò)展到超人模型,但(2)大幅改善弱到強(qiáng)的泛化是可行的。
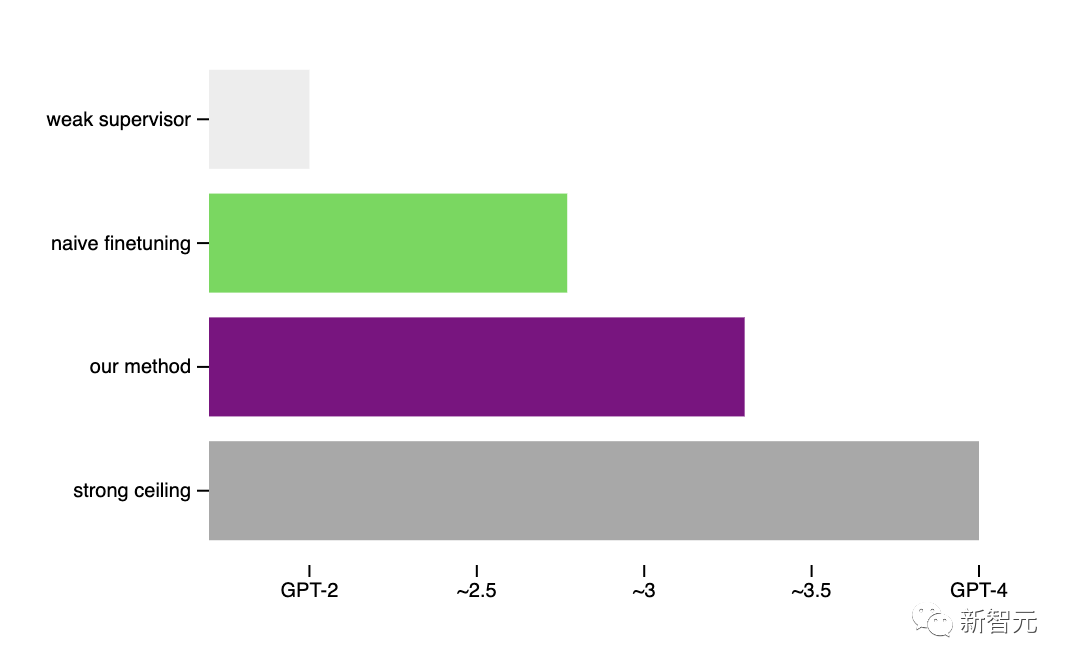
代碼開(kāi)源,社區(qū)共創(chuàng)
OpenAI目前的經(jīng)驗(yàn)設(shè)置與對(duì)齊超級(jí)模型的終極問(wèn)題之間,仍然存在重要的差異。
比如,未來(lái)的模型可能比當(dāng)前強(qiáng)模型,模仿當(dāng)前的弱模型錯(cuò)誤更容易,這可能會(huì)使未來(lái)的泛化更加困難。
盡管如此,OpenAI團(tuán)隊(duì)相信實(shí)驗(yàn)設(shè)置,抓住了對(duì)齊未來(lái)超級(jí)模型的一些關(guān)鍵難點(diǎn),使OpenAI能夠在這個(gè)問(wèn)題上取得可以驗(yàn)證的進(jìn)展。

同時(shí),他們還透露了未來(lái)工作方向,包括修正設(shè)置,開(kāi)發(fā)更好的可擴(kuò)展方法,以及推進(jìn)對(duì)何時(shí)以及如何獲得良好的「弱到強(qiáng)」泛化的科學(xué)理解。
OpenAI表示,他們正在開(kāi)源代碼,讓機(jī)器學(xué)習(xí)社區(qū)研究人員立即輕松開(kāi)始從弱到強(qiáng)的泛化實(shí)驗(yàn)。

1千萬(wàn)美元資助,解決超級(jí)對(duì)齊難題
這次,OpenAI還與Eric Schmidt合作,啟動(dòng)了一個(gè)價(jià)值1000萬(wàn)美元的資助計(jì)劃,支持確保超人類(lèi)AI系統(tǒng)對(duì)齊并安全的技術(shù)研究:

- OpenAI為學(xué)術(shù)實(shí)驗(yàn)室、非營(yíng)利組織和個(gè)人研究人員提供10萬(wàn)至200萬(wàn)美元的資助。
- 對(duì)于研究生,OpenAI設(shè)立了為期一年、總額為15萬(wàn)美元的OpenAI Superalignment獎(jiǎng)學(xué)金,包括7.5萬(wàn)美元的津貼和7.5萬(wàn)美元的計(jì)算及研究資金。
- 申請(qǐng)者無(wú)需有對(duì)齊工作經(jīng)驗(yàn);OpenAI會(huì)特別支持首次從事對(duì)齊研究的研究人員。
- 申請(qǐng)過(guò)程簡(jiǎn)潔高效,具體回復(fù)將會(huì)在申請(qǐng)截止后的四周內(nèi)給出。
OpenAI尤其關(guān)注以下幾個(gè)研究方向:
- 弱到強(qiáng)的泛化:面對(duì)超人類(lèi)模型,人類(lèi)將是相對(duì)弱勢(shì)的監(jiān)督者。人類(lèi)能否理解并控制強(qiáng)大模型是如何從弱監(jiān)督中學(xué)習(xí)和泛化的?
- 可解釋性:人類(lèi)如何理解模型的內(nèi)部工作原理?人類(lèi)能否利用這種理解來(lái)開(kāi)發(fā)像AI謊言檢測(cè)器這類(lèi)的工具來(lái)幫助人類(lèi)?
- 可擴(kuò)展的監(jiān)督:人類(lèi)如何利用AI系統(tǒng)幫助人類(lèi)評(píng)估其他AI系統(tǒng)在復(fù)雜任務(wù)上的表現(xiàn)?
- 還有包括但不限于以下方向的多個(gè)研究領(lǐng)域:誠(chéng)實(shí)度、思維鏈的誠(chéng)實(shí)度、對(duì)抗魯棒性(adversarial robustness)、評(píng)估和測(cè)試平臺(tái)等等方向。






























