













上下文學習=對比學習?人大揭示ICL推理背后的隱式更新機理:梯度更新了嗎?「如更」
近些年來,基于Transformer的大語言模型表現出了驚人的In-context Learning (ICL)能力,我們只需要在查詢問題前以 {問題,標簽} 的形式增加少數示例,模型就可以學到該任務并輸出較好的結果。
然而,ICL背后的機理仍是一個開放的問題:在ICL的推理過程,模型的參數并沒有得到顯式的更新,模型如何根據示例樣本輸出相應的結果呢?
近日,來自中國人民大學的學者提出了從對比學習的視角看待基于Transformer的ICL推理過程,文章指出基于注意力機制的ICL推理過程可以等價于一種對比學習的模式,為理解ICL提供了一種全新視角。

論文地址:https://arxiv.org/abs/2310.13220
研究人員先利用核方法在常用的softmax注意力下建立了梯度下降和自注意機制之間的關系,而非線性注意力;
然后在無負樣本對比學習的角度上,對ICL中的梯度下降過程進行分析,并討論了可能的改進方式,即對自注意力層做進一步修改;
最后通過設計實驗來支持文中提出的觀點。
研究團隊表示,這項工作是首次從對比學習的角度來理解ICL,可以通過參考對比學習的相關工作來促進模型的未來設計思路。
背景與動機
相較于有監督學習下的微調,大模型在ICL推理過程中并不需要顯式的梯度更新,即可學習到示例樣本中的信息并輸出對于查詢問題的答案,基于Transformer的大模型是如何實現這一點的呢?
一個自然且直觀的想法是,模型雖然沒有在學習上下文過程存在顯式更新,但可能存在相應的隱式更新機理。
在此背景下,許多工作開始從梯度下降的角度來思考大模型的ICL能力。
然而,現有的工作或是基于Transformer線性注意力的假設,或是基于對模型參數特定的構造進行分析,實際應用中的模型并不一定符合上述的假設。
因此,有兩個問題亟需解決:
(1)不依賴于權重參數構造方法以及線性注意力的假設,如何在更為廣泛使用的softmax注意力設定下,對ICL的隱式更新機理進行分析?
(2)這種隱式更新的具體過程,如損失函數以及訓練數據,會具有什么樣的形式?
方法
作者首先假設模型輸入的token由若干示例樣本的token以及最后的查詢token組成,每個token由 {問題, 標簽} 的embedding拼接而成,其中,查詢token的標簽部分設置為0,即

在注意力機制下,模型輸出最后一個token并readout得到預測的標簽結果

進一步,作者應用核方法,將注意力矩陣的每一項看作映射函數的內積

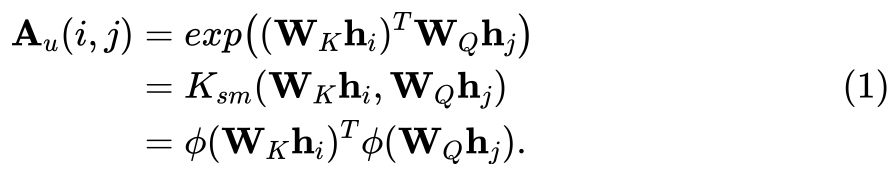
在此基礎上,作者建立了基于Transformer注意力機制的推理過程與在參考模型上進行梯度下降之間的對應關系。
在參考模型的梯度下降過程中,示例樣本與查詢的token分別提供了訓練集以及測試輸入的相關信息,模型在類似余弦相似度的損失函數下進行訓練,參考模型最后輸出測試輸入所對應的輸出。
作者指出參考模型的該輸出會與注意力機制下的推理輸出嚴格等價,即參考模型在對應數據集以及余弦相似損失上進行一步隨機梯度下降后,得到的測試輸出會與注意力機制下得到的輸出是嚴格相等的。
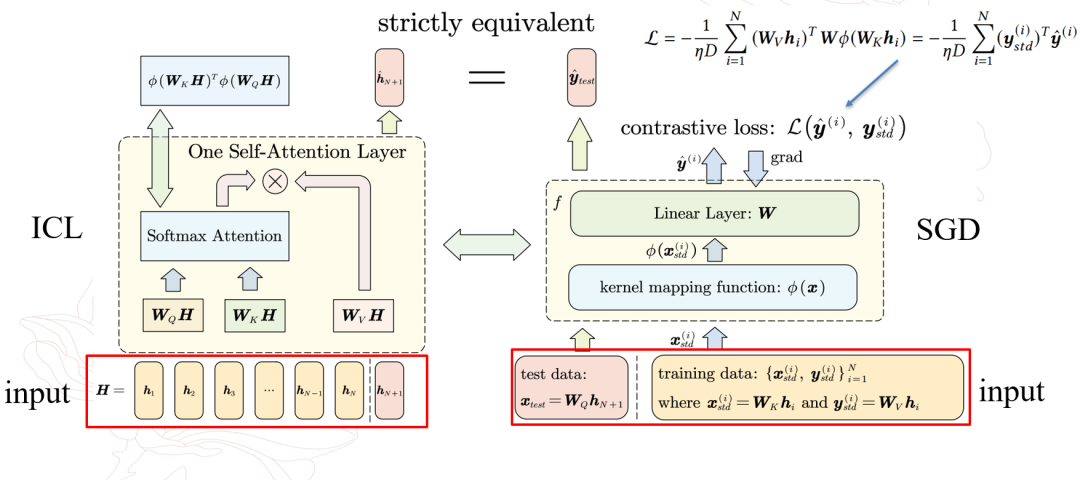
等價關系
進一步,作者發現這一對應的梯度下降過程類似于無負樣本的對比學習模式,其中,注意力機制中的K,V映射可以看作為一種「數據增強」。
而參考模型則是相當于需要學習潛在表征的encoder,其將映射后的K向量先投影到高維空間學習深層表征,然后再映射回原來的空間與V向量進行對比損失的計算,以使得兩者的盡可能的相似。
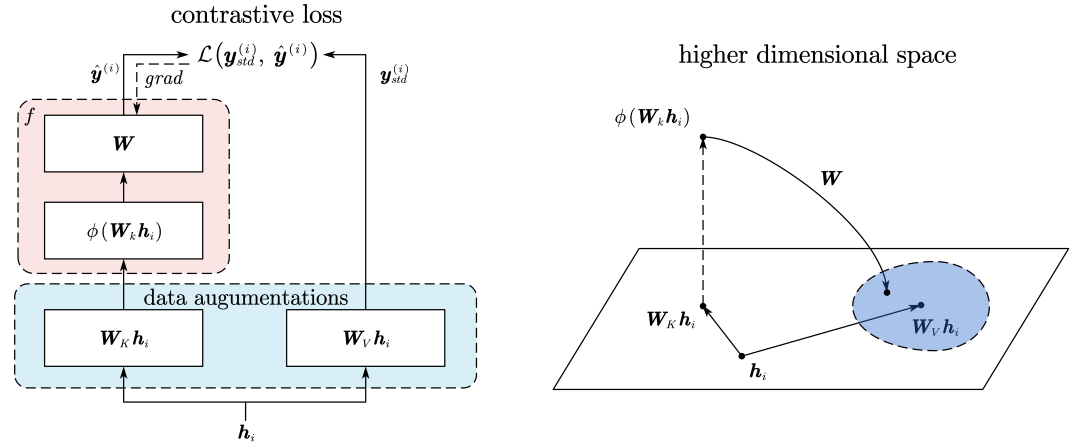
對比學習模式
基于此,作者從對比學習的角度對注意力機制作出改進,作者分別從正則化的損失函數、數據增強以及增加負樣本三個方面來進行考慮。
正則化的損失函數
作者指出在對比損失中增加正則,相當于在原有注意力機制上添加特殊的支路。

數據增強
作者認為原有的線性映射作為數據增強或不利于學習潛在表征,對于特定數據類型所設計的數據增強方式或許更為有效,相應地,作者給出了對模型進行修改的框架。

增加負樣本
此外,作者還從增加負樣本的角度,給出了ICL對比學習模式以及相應注意力機制的改進。


實驗
實驗部分中,作者在線性回歸任務上設計了仿真實驗,說明了注意力機制下的推理過程與參考模型上進行梯度下降過程的等價性,即單層注意力機制下得到的推理結果,嚴格等價于參考模型在對比損失loss上進行一步梯度下降后的測試輸出。
在實驗中,作者還選取了正隨機特征作為映射函數,來作為對注意力機制的近似,并考察了不同隨機特征維度對注意力矩陣以及輸出近似效果的影響,說明了該映射函數的有效性。

實驗圖1
作者還展示了近似得到的注意力矩陣以及輸出與實際結果的對比,說明了二者在模式上的基本一致。

實驗圖2
最后,作者進一步探究了根據對比學習視角對注意力機制改進后的表現效果,發現選擇合適的改進方式不僅可以加速模型訓練的收斂速度,還可以最終取得更好的效果,這說明了未來從對比學習視角進行模型結構設計與改進的潛力。

實驗圖3
總結與未來展望
作者在不依賴于線性注意力假設以及權重構造的方法下,探究了ICL的隱式更新機理,建立了softmax注意力機制推理過程與梯度下降的等價關系,并進一步提出了從對比學習的視角下看待注意力機制推理過程的新框架。
但是,作者也指出了該工作目前仍存在一定的缺陷:文章目前只考慮了softmax自注意力機制下的前向推理,層歸一化,FFN模塊以及decoder等Transforomer其余結構對推理過程的影響仍有待進一步的研究;從對比學習視角出發對模型結構進行進一步的改進,在諸多實際應用任務上的表現仍有待進一步探索。



























