吳恩達團隊新作:多模態(tài)多樣本上下文學(xué)習(xí),無需微調(diào)快速適應(yīng)新任務(wù)
本研究評估了先進多模態(tài)基礎(chǔ)模型在 10 個數(shù)據(jù)集上的多樣本上下文學(xué)習(xí),揭示了持續(xù)的性能提升。批量查詢顯著降低了每個示例的延遲和推理成本而不犧牲性能。這些發(fā)現(xiàn)表明:利用大量演示示例可以快速適應(yīng)新任務(wù)和新領(lǐng)域,而無需傳統(tǒng)的微調(diào)。

- 論文地址:https://arxiv.org/abs/2405.09798
- 代碼地址:https://github.com/stanfordmlgroup/ManyICL
背景介紹
在近期的多模態(tài)基礎(chǔ)模型(Multimodal Foundation Model)研究中,上下文學(xué)習(xí)(In-Context Learning, ICL)已被證明是提高模型性能的有效方法之一。
然而,受限于基礎(chǔ)模型的上下文長度,尤其是對于需要大量視覺 token 來表示圖片的多模態(tài)基礎(chǔ)模型,已有的相關(guān)研究只局限于在上下文中提供少量樣本。
令人激動的是,最新的技術(shù)進步大大增加了模型的上下文長度,這為探索使用更多示例進行上下文學(xué)習(xí)提供了可能性。
基于此,斯坦福吳恩達團隊的最新研究——ManyICL,主要評估了目前最先進的多模態(tài)基礎(chǔ)模型在從少樣本 (少于 100) 到多樣本(最高至 2000)上下文學(xué)習(xí)中的表現(xiàn)。通過對多個領(lǐng)域和任務(wù)的數(shù)據(jù)集進行測試,團隊驗證了多樣本上下文學(xué)習(xí)在提高模型性能方面的顯著效果,并探討了批量查詢對性能和成本及延遲的影響。

Many-shot ICL與零樣本、少樣本ICL的比較。
方法概覽
本研究選擇了三種先進的多模態(tài)基礎(chǔ)模型:GPT-4o、GPT4 (V)-Turbo 和 Gemini 1.5 Pro。出于 GPT-4o 優(yōu)越的表現(xiàn),研究團隊在正文中著重討論 GPT-4o 和 Gemini 1.5 Pro, GPT4 (V)-Turbo 的相關(guān)內(nèi)容請于附錄中查看。
數(shù)據(jù)集方面,研究團隊在 10 個跨越不同領(lǐng)域(包括自然影像、醫(yī)學(xué)影像、遙感影像和分子影像等)和任務(wù)(包括多分類、多標(biāo)簽分類和細(xì)粒度分類)的數(shù)據(jù)集上進行了廣泛的實驗。

基準(zhǔn)數(shù)據(jù)集匯總。
為了測試增加示例數(shù)量對模型性能的影響,研究團隊逐步增加了上下文中提供的示例數(shù)量,最高達到近 2000 個示例。同時,考慮到多樣本學(xué)習(xí)的高成本和高延遲,研究團隊還探索了批量處理查詢的影響。在這里,批量查詢指的是在單次 API 調(diào)用中處理多個查詢。
實驗結(jié)果
多樣本上下文學(xué)習(xí)性能評估
總體表現(xiàn):包含近 2000 個示例的多樣本上下文學(xué)習(xí)在所有數(shù)據(jù)集上均優(yōu)于少樣本學(xué)習(xí)。隨著示例數(shù)量的增加,Gemini 1.5 Pro 模型的性能呈現(xiàn)出持續(xù)的對數(shù)線性提升,而 GPT-4o 的表現(xiàn)則較不穩(wěn)定。
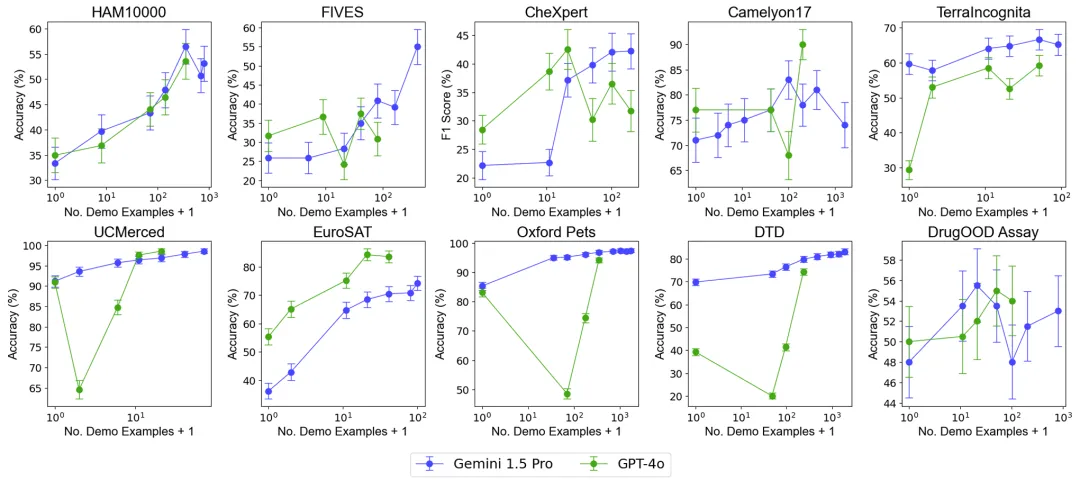
數(shù)據(jù)效率:研究測量了模型的上下文學(xué)習(xí)數(shù)據(jù)效率,即模型從示例中學(xué)習(xí)的速度。結(jié)果表明,Gemini 1.5 Pro 在絕大部分?jǐn)?shù)據(jù)集上顯示出比 GPT-4o 更高的上下文學(xué)習(xí)數(shù)據(jù)效率,意味著它能夠更有效地從示例中學(xué)習(xí)。

批量查詢的影響
總體表現(xiàn):在選擇最優(yōu)示例集大小下的零樣本和多樣本情境中,將多個查詢合并為一次請求,不會降低性能。值得注意的是,在零樣本場景中,單個查詢在許多數(shù)據(jù)集上表現(xiàn)較差。相比之下,批量查詢甚至可以提高性能。
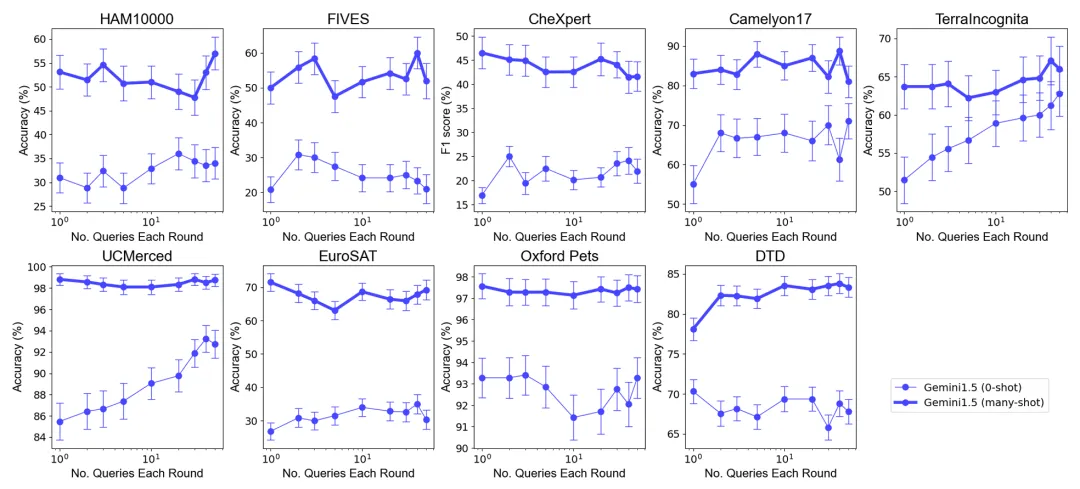
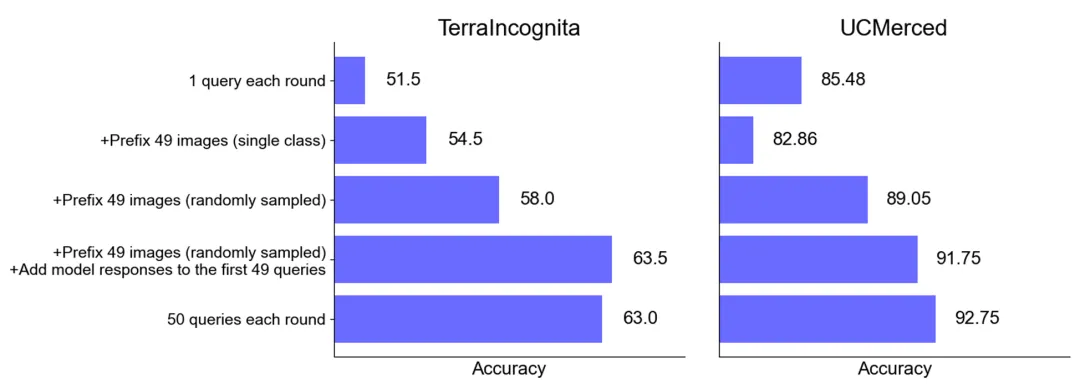
零樣本場景下的性能提升:對于某些數(shù)據(jù)集(如 UCMerced),批量查詢在零樣本場景下顯著提高了性能。研究團隊分析認(rèn)為,這主要歸因于領(lǐng)域校準(zhǔn) (domain calibration)、類別校準(zhǔn) (class calibration) 以及自我學(xué)習(xí) (self-ICL)。
成本和延遲分析
多樣本上下文學(xué)習(xí)雖然在推理時需要處理更長的輸入上下文,但通過批量查詢可以顯著降低每個示例的延遲和推理成本。例如,在 HAM10000 數(shù)據(jù)集中,使用 Gemini 1.5 Pro 模型進行 350 個示例的批量查詢,延遲從 17.3 秒降至 0.54 秒,成本從每個示例 0.842 美元降至 0.0877 美元。

結(jié)論
研究結(jié)果表明,多樣本上下文學(xué)習(xí)能夠顯著提高多模態(tài)基礎(chǔ)模型的表現(xiàn),尤其是 Gemini 1.5 Pro 模型在多個數(shù)據(jù)集上表現(xiàn)出持續(xù)的性能提升,使其能夠更有效地適應(yīng)新任務(wù)和新領(lǐng)域,而無需傳統(tǒng)的微調(diào)。
其次,批量處理查詢可以在相似甚至更好的模型表現(xiàn)的同時,降低推理成本和延遲,顯示出在實際應(yīng)用中的巨大潛力。
總的來說,吳恩達團隊的這項研究為多模態(tài)基礎(chǔ)模型的應(yīng)用開辟了新的路徑,特別是在快速適應(yīng)新任務(wù)和領(lǐng)域方面。