













最強開源大模型剛剛易主!李開復率隊問鼎全球多項榜單,40萬文本處理破紀錄
百模大戰,最備受期待的一位選手,終于正式亮相!
它便是來自李開復博士創辦的AI 2.0公司零一萬物的首款開源大模型——Yi系列大模型:
Yi-34B和Yi-6B。
雖然Yi系列大模型出道時間相對較晚,但從效果上來看,絕對稱得上是后發制人。
一出手即問鼎多項全球第一:
- Hugging Face英文測試榜單位居第一,以34B的大小碾壓Llama-2 70B和Falcon-180B等一眾大尺寸大模型;
- 唯一成功登頂HuggingFace的國產大模型;
- C-Eval中文能力排行榜位居第一,超越了全球所有開源模型;
- MMLU、BBH等八大綜合能力表現全部勝出;
- 拿下全球最長上下文窗口寶座,達到200K,可直接處理40萬漢字超長文本輸入。
- ……

值得注意的是,零一萬物及其大模型并非是一蹴而就,而是醞釀了足足半年有余。
由此不免讓人產生諸多疑問:
例如為什么要憋半年之久的大招,選擇在臨近歲末之際出手?
再如是如何做到一面世即能拿下如此之多的第一?
帶著這些問題,我們與零一萬物做了獨家交流,現在就來一一揭秘。
擊敗千億參數大模型
具體來看,零一萬物最新發布開源的Yi系列大模型主要有兩大亮點:
- “以小博大”擊敗千億參數模型
- 全球最長上下文窗口支持40萬字
在Hugging Face英文測試公開單 Pretrained 預訓練開源模型排名中,Yi-34B以70.72分數位列全球第一,超過了LLaMA-70B和Falcon-180B。
要知道,Yi-34B的參數量僅為后兩者的1/2、1/5。不僅“以小博大”問鼎榜單,而且實現了跨數量級的反超,以百億規模擊敗千億級大模型。
其中在MMLU(大規模多任務語言理解)、TruthfulQA(真實性基準)兩項指標中,Yi-34B都大幅超越其他大模型。

△Hugging Face Open LLM Leaderboard (pretrained) 大模型排行榜,Yi-34B高居榜首(2023年11月5日)
聚焦到中文能力方面,Yi-34B在C-Eval中文能力能力排行榜上超越所有開源模型。
同樣開源的Yi-6B也超過了同規模所有開源模型。

△C-Eval 排行榜:公開訪問的模型,Yi-34B 全球第一(2023年11月5日)
在CMMLU、E-Eval、Gaokao三個主要中文指標上,明顯領先于GPT-4,彰顯強大的中文優勢,對咱們更知根知底。
在BooIQ、OBQA兩個問答指標上,和GPT-4水平相當。

另外,在大模型最關鍵評測指標MMLU(Massive Multitask Language Understanding,大規模多任務語言理解)、BBH等反映模型綜合能力的評測集上,Yi-34B在通用能力、知識推理、閱讀理解等多項指標評比中全面超越,與Hugging Face評測高度一致。
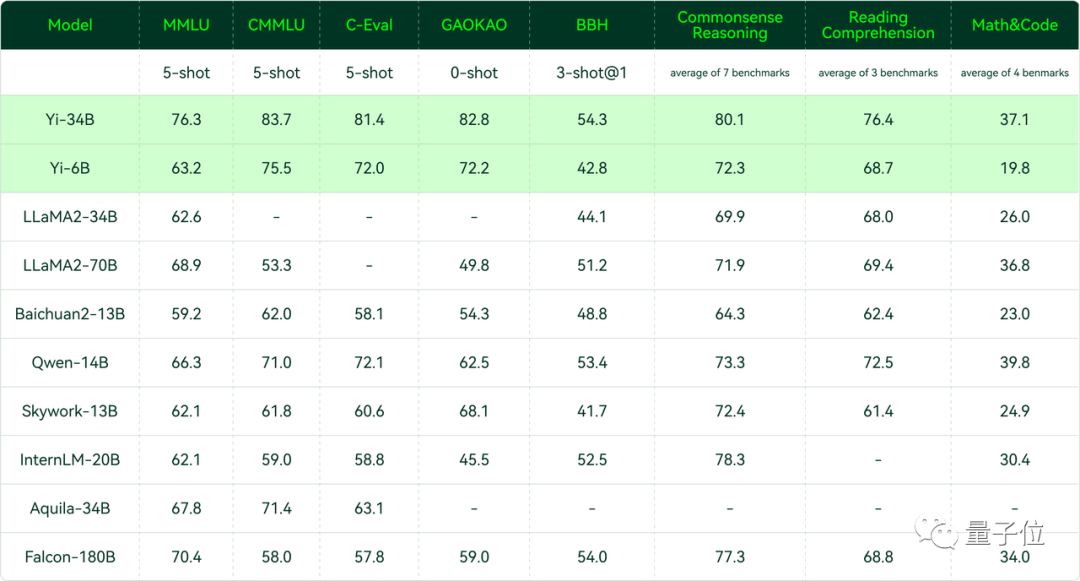
△各評測集得分:Yi 模型 v.s. 其他開源模型
不過在發布中零一萬物也表示,Yi系列模型在GSM8k、MBPP的數學和代碼測評中表現還不及GPT模型。
這是因為團隊希望在預訓練階段先盡可能保留模型的通用能力,所以訓練數據中沒有加入過多數學和代碼數據。
目前團隊正在針對數學方向展開研究,提出了可以解決一般數學問題的大模型MammoTH,利用CoT和PoT解決數學問題,在各個規模版本、內外部測試集上均優于SOTA模型。其中MammoTH-34B在MATH上的準確率達到44%,超過了GPT-4的CoT結果。
后續Yi系列也將推出專長代碼和數學的繼續訓練模型。

而除了亮眼的刷榜成績外,Yi-34B還將大模型上下文窗口長度刷新到了200K,可處理約40萬漢字超長文本輸入。
這相當于能一次處理兩本《三體 1》小說、理解超過1000頁的PDF文檔,甚至能替代很多依賴于向量數據庫構建外部知識庫的場景。
超長上下文窗口是體現大模型實力的一個重要維度,擁有更長的上下文窗口則能處理更豐富的知識庫信息,生成更連貫、準確的文本,也能支持大模型更好處理文檔摘要/問答等任務。
要知道,目前大模型的諸多垂直行業應用中(如金融、法律、財務等),文檔處理能力是剛需。
如GPT-4可支持32K、約2.5萬漢字,Claude 2可支持100K、約20萬字。
零一萬物不僅刷新了業界紀錄,同時也是首家將超長上下文窗口在開源社區開放的大模型公司。
所以,Yi系列是如何煉成的?
超強Infra+自研訓練平臺
零一萬物表示,Yi系列煉成的秘訣來自兩方面:
- 自研規模化訓練實驗平臺
- 超強Infra團隊
如上二者結合,能讓大模型訓練過程更加高效、準確、自動化。在多模混戰的當下,節省寶貴的時間、計算、人力成本。
它們是Yi系列大模型為何會“慢”的原因之一,但也因為有了它們,所以“慢即是快”。
首先來看模型訓練部分。
這是大模型能力打基礎的環節,訓練數據質量和方法如何,直接關乎模型最終效果。
所以,零一萬物自建了智能數據處理管線和規模化訓練實驗平臺。
智能數據處理管線高效、自動、可評價、可擴展,團隊由前Google大數據和知識圖譜專家領銜。
“規模化訓練實驗平臺”可以指導模型的設計和優化,提升模型訓練效率、減少計算資源浪費。
基于這一平臺,Yi-34B每個節點的預測誤差都控制在0.5%以內,如數據配比、超參搜索、模型結構實驗都可以在上面進行。
由此,與過往的“粗放煉丹”訓練比較,Yi系列大模型的訓練進階到“訓模科學”:變得更加細致、科學化,實驗結果可以更加穩定,未來模型規模進一步擴大的速度也能更快。
再來看Infra部分。
AI Infra是指人工智能基礎框架技術,它包含了大模型訓練、部署方面的各種底層技術設施,包括處理器、操作系統、存儲系統、網絡基礎設施、云計算平臺等——是大模型領域絕對的硬技術。
如果說訓練環節是為模型質量打地基,那么AI Infra則是為這一環節提供保障,讓地基更加牢固,亦是直接關乎大模型底層的部分。
零一萬物團隊用了一個更加形象的比喻解釋:
如果說大模型訓練是登山,Infra的能力定義了大模型訓練算法和模型的能力邊界,也就是“登山高度”的天花板。
尤其在業內算力資源緊張的當下,如何更快、更穩地推進大模型研發,非常關鍵。
這就是為何零一萬物如此重視Infra部分。
李開復也曾表示,做過大模型Infra的人,比作算法的人才還要稀缺。
而零一萬物的Infra團隊曾參與支持多個千億級大模型規模化訓練。
在他們的支持下,Yi-34B模型訓練成本實測下降40%,模擬千億規模訓練成本可下降多達50%。實際訓練完成達標時間域預測的時間誤差不到1小時——要知道,一般業內都會預留幾天時間作為誤差。
團隊表示,截至目前零一萬物Infra能力實現故障預測準確率超過90%,故障提前發現率達到99.9%,無需人工參與的故障自愈率超過95%,能有力保障模型訓練順暢進行。
李開復透露,在完成Yi-34B預訓練的同時,零一萬物千億級參數模型訓練已正式啟動。
而且暗示更大模型的面世速度,很可能超出大家預期:
零一萬物的數據處理管線、算法研究、實驗平臺、GPU 資源和 AI Infra 都已經準備好,我們的動作會越來越快。
后發制人的的零一萬物
最后,我們來回答一下最開始我們提到的那幾個問題。
零一萬物之所以選擇在年底搭乘“晚班車”入局,實則與它自身的目標息息相關。
正如李開復在此次發布中所述:
零一萬物堅定進軍全球第一梯隊目標,從招的第一個人,寫的第一行代碼,設計的第一個模型開始,就一直抱著成為“World’s No.1”的初衷和決心。
而要做到第一,需是得能耐得住性子,潛心修煉扎實的功底,方可在出道之際做到一鳴驚人。
不僅如此,在零一萬物成立之際,它的出發點便與其它大模型廠商有著本質的不同。
零一代表的是整個數字世界,從零到一,乃至宇宙萬物,所謂道生一……生萬物,寓意 “零一智能,萬物賦能” 的雄心。
這也與李開復關于AI2.0的思考判斷一以貫之,在ChatGPT帶動大模型熱潮之后,他就曾公開表示過:
以基座大模型為突破的AI 2.0時代,將掀起技術、平臺到應用多個層面的革命。如同Windows帶動了PC普及,Android催生了移動互聯網的生態,AI2.0將誕生比移動互聯網大十倍的平臺機會,將把既有的軟件、使用界面和應用重寫一次,也將誕生新一批AI-first的應用,并催生由AI主導的商業模式。
理念就是AI-first,驅動力是技術愿景,背靠卓越的中國工程底蘊,突破點是基座大模型,覆蓋范圍包含技術、平臺到應用多個層面。
為此,零一萬物從成立以來選擇的創業路線便是自研大模型。
雖說發布時間較晚,但在速度上絕對不算慢。
例如在頭三個月的時間里,零一萬物就已經實現了百億參數規模的模型內測;而再時隔三個月,便可以用34B的參數規模解鎖全球第一。
如此速度,如此高目標,定然也是離不開零一萬物背后雄厚的團隊實力。
零一萬物由李開復博士親自掛帥、任CEO。
在早期階段,零一萬物已經聚集起了數十名核心成員的團隊,集中在大模型技術、人工智能算法、自然語言處理、系統架構、算力架構、數據安全、產品研發等領域。
其中已加入的聯創團隊成員包含前阿里巴巴副總裁、前百度副總裁、前谷歌中國高管、前微軟/SAP/Cisco/副總裁,算法和產品團隊背景均來自國內外大廠。
以算法和模型團隊成員為例,有論文曾被GPT-4引用的算法大拿,有獲得過微軟內部研究大獎的優秀研究員,曾獲得過阿里CEO特別獎的超級工程師。總計在ICLR、NeurIPS、CVPR、ICCV等知名學術會議上發表過大模型相關學術論文100余篇。
而且零一萬物在成立之初便已經開始搭建實驗平臺,構建了個數千卡GPU集群,進行訓練、調優和推理。在數據方面,主打一個提高有效參數量和使用的高質量數據密度。
由此,不難看出零一萬物Yi系列大模型敢于后發制人的底氣何在了。
據了解,零一萬物接下來還將Yi系列大模型為基礎,快速迭代開源更多量化的版本、對話模型、數學模型、代碼模型和多模態模型等。
總而言之,隨著零一萬物這匹黑馬的入局,百模大戰已然變得更加激烈與熱鬧。
對于Yi系列大模型還將在未來顛覆多少“全球第一”,是值得期待一波了。
One More Thing
為什么取名“Yi” ?
命名來自“一”的拼音,“Yi”中的“Y”上下顛倒,巧妙形同漢字的 “人”,結合AI里的 i,代表 Human + AI。
零一萬物相信 AI 賦能推動人類社會前行,AI 應本著以人為本的精神,為人類創造巨大的價值。






















