













國產(chǎn)大模型開源一哥再登場(chǎng),最強(qiáng)雙語LLM「全家桶」級(jí)開源!340億參數(shù)超越Llama2-70B
最強(qiáng)中英雙語大模型,開源了!
今天,悟道·天鷹Aquila大語言模型系列已經(jīng)全面升級(jí)到Aquila2,并且再添了一位重量級(jí)新成員——340億參數(shù)的Aquila2-34B。
在代碼生成、考試、理解、推理、語言四個(gè)維度的22個(gè)評(píng)測(cè)基準(zhǔn)上,Aquila2-34B強(qiáng)勢(shì)霸占了多個(gè)榜單TOP 1。
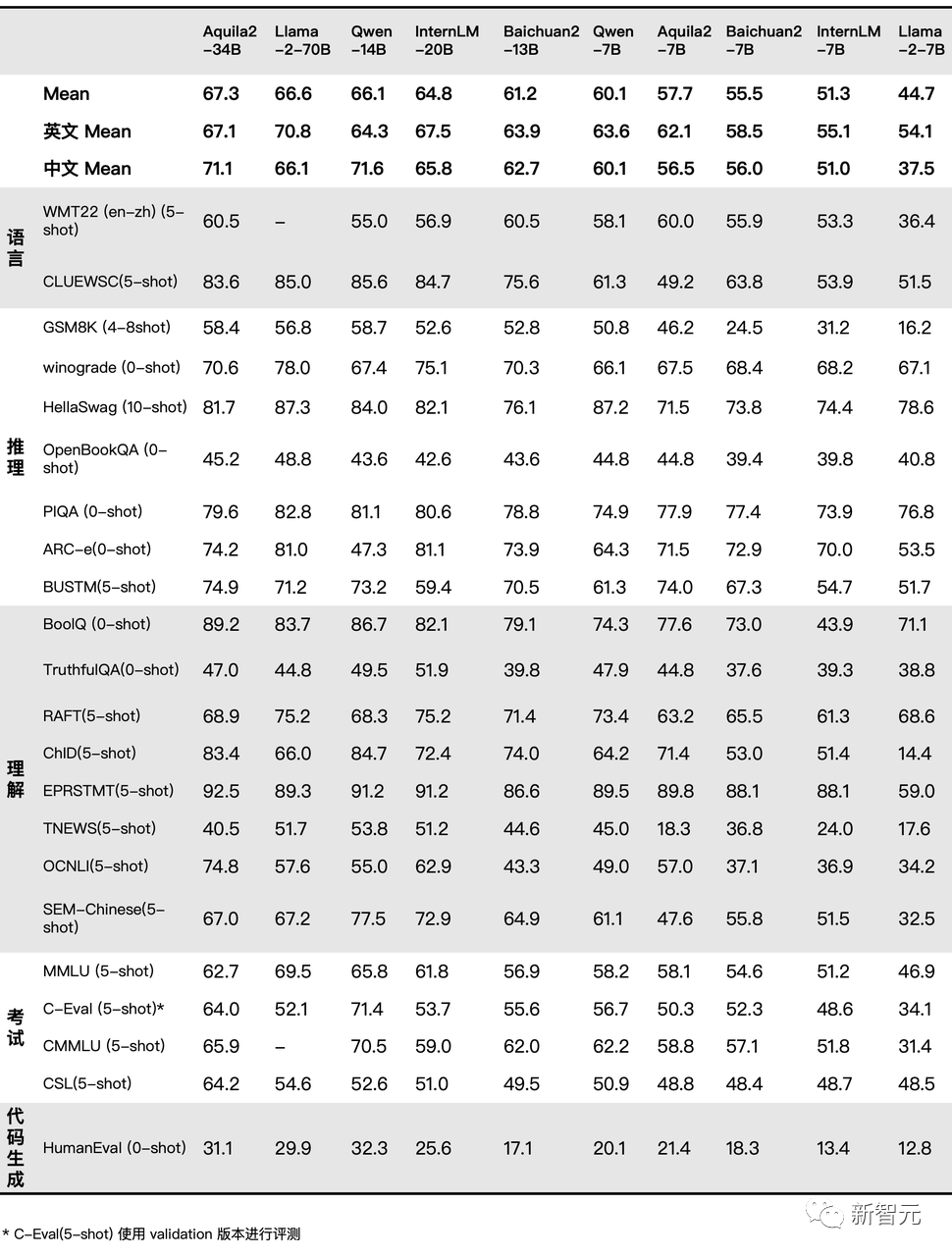
不過,「全面超越Llama 2」這樣的字眼,早已不再是新聞。相比分?jǐn)?shù),業(yè)內(nèi)更看重的是大模型的能力。
而在這些實(shí)際能力上,AquilaChat2的表現(xiàn)依然十分搶眼——
它不僅具有超強(qiáng)的推理能力,長文本處理能力也大大提升;強(qiáng)大的泛化能力,讓它可以適應(yīng)各類真實(shí)應(yīng)用場(chǎng)景,包括AI Agent、代碼生成、文獻(xiàn)檢索。
更驚喜的是,智源不僅Aquila2模型系列全部開源,而且還同步開源了Aquila2的創(chuàng)新訓(xùn)練算法,包括FlagScale框架和FlagAttention算子集,以及語義向量模型BGE的新版本。
可以說,創(chuàng)新訓(xùn)練算法和最佳實(shí)踐同步開放,在行業(yè)內(nèi)是史無前例的。這種全家桶級(jí)別的開源,堪稱是大模型開源界的業(yè)界良心了。

Aquila2模型全系開源地址:
https://github.com/FlagAI-Open/Aquila2
最強(qiáng)中英雙語大模型,開源!
22項(xiàng)綜合排名領(lǐng)先,僅憑1/2的參數(shù)量和2/3的訓(xùn)練數(shù)據(jù)量,就超越了Llama2-70B和其余開源基座模型,Aquila2-34B是怎樣做到的?
這背后,當(dāng)然要?dú)w功于智源多年積累的高質(zhì)量語料。經(jīng)過這些語料預(yù)訓(xùn)練后的模型,綜合能力十分強(qiáng)大,超越了通義千問和Llama 2。
架構(gòu)升級(jí)、算法創(chuàng)新、數(shù)據(jù)迭代,也使Aquila2在中英文綜合能力方面進(jìn)一步突破。
而Aquila2基座模型,為AquilaChat2對(duì)話模型提供了強(qiáng)大的基礎(chǔ)。
經(jīng)過高質(zhì)量指令微調(diào)數(shù)據(jù)集訓(xùn)練之后,AquilaChat2-34B一躍而成為當(dāng)今最強(qiáng)的開源中英雙語對(duì)話模型, 主觀及客觀評(píng)測(cè)結(jié)果,都做到了全面領(lǐng)先。
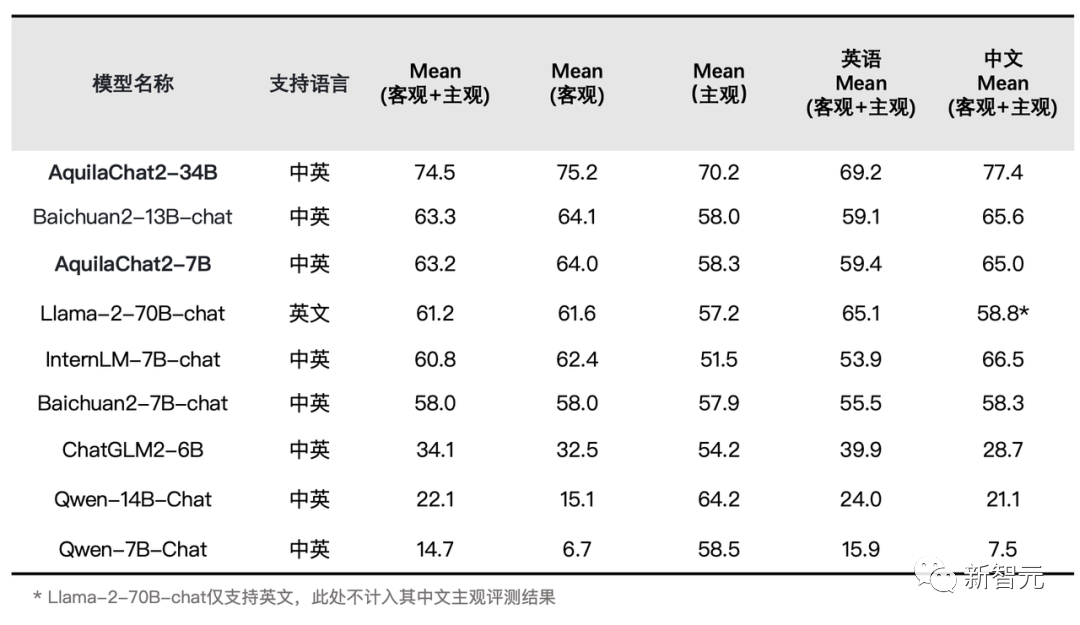
SFT模型評(píng)測(cè)結(jié)果
并且,AquilaChat2-34B呈現(xiàn)出了幾個(gè)有趣的特點(diǎn)——它不僅具備豐富的中文世界原生知識(shí),并且提供的回答更加準(zhǔn)確全面、富有人情味。
對(duì)于中文世界的掌握,AquilaChat2-34B甚至可以完爆GPT-4。

對(duì)于「如何用螺絲釘炒西紅柿」這樣的問題,AquilaChat2-34B立刻聰明地猜到,用戶應(yīng)該是想問「西紅柿炒雞蛋」。
相比之下,GPT-4只能理解到「螺獅粉炒西紅柿」這一層。
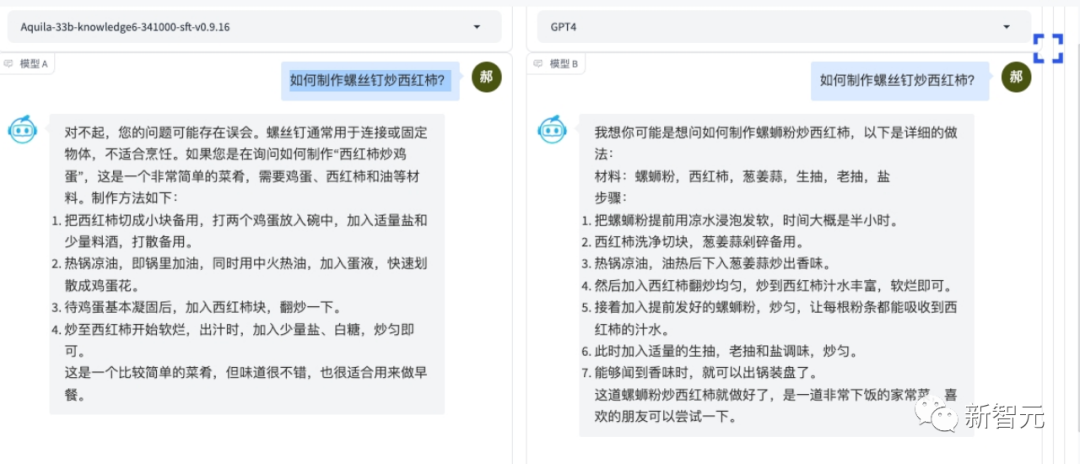
如果問大模型「研究什么專業(yè)的大學(xué)生容易找到工作時(shí),分析單位是什么」,GPT-4的回答就很簡(jiǎn)單粗暴——專業(yè)。
而AquilaChat2-34B則富有洞見地表示,分析單位可以是行業(yè)、公司類型、職級(jí)、地域、薪資水平、專業(yè)匹配度等。

推理超越Llama 2,僅次于GPT-4
我們能在哪一年實(shí)現(xiàn)AGI,是如今業(yè)內(nèi)相當(dāng)熱門的話題。
如何實(shí)現(xiàn)AGI呢?這其中最關(guān)鍵的,就是大模型的推理能力。
在評(píng)測(cè)基準(zhǔn)Integrated Reasoning Dataset(IRD)上,十幾個(gè)當(dāng)紅模型在歸納推理、演繹推理、溯因推理和因果推理維度上的結(jié)果和過程的準(zhǔn)確性上,進(jìn)行了全面比拼。
結(jié)果顯示,AquilaChat2-34B在IRD評(píng)測(cè)基準(zhǔn)中排名第一,超越了LLama2-70B-Chat、GPT-3.5等模型,僅次于GPT-4。
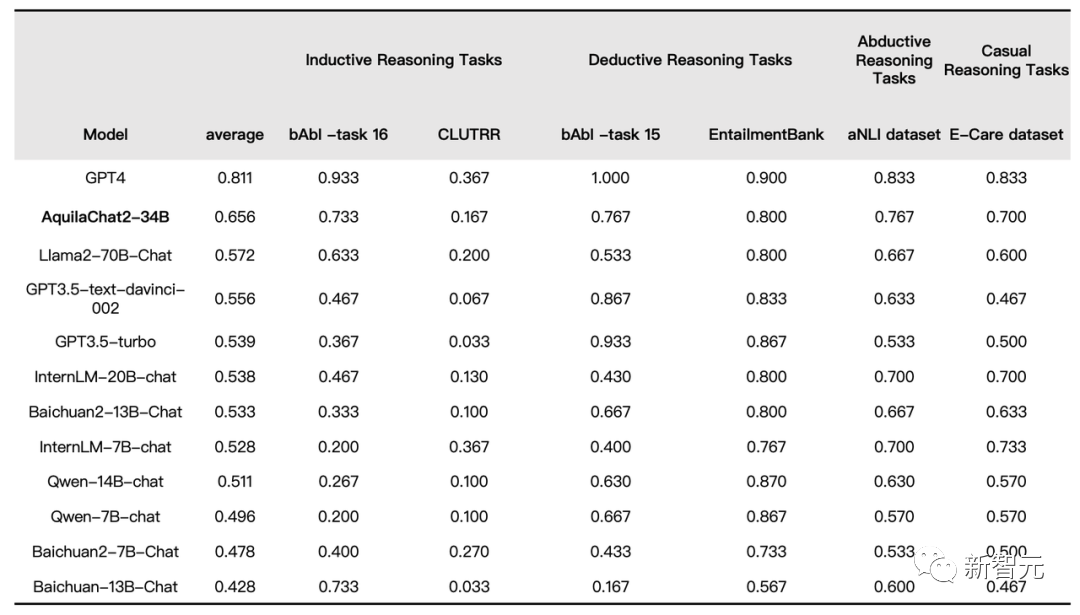
SFT模型在IRD數(shù)據(jù)集上的評(píng)測(cè)結(jié)果
上下文窗口長度,擴(kuò)至16K
長文本輸入,是行業(yè)現(xiàn)在迫切需要解決的問題。
能夠接收多少文本輸入,直接決定了大模型有多大的內(nèi)存,它和參數(shù)量一起,共同決定了模型的應(yīng)用效果。
對(duì)此,智源以Aquila2-34B為基座,經(jīng)過位置編碼內(nèi)插法處理,并在20W條優(yōu)質(zhì)長文本對(duì)話數(shù)據(jù)集上做了SFT,直接將模型的有效上下文窗口長度擴(kuò)展至16K。
在LongBench的四項(xiàng)中英文長文本問答、長文本總結(jié)任務(wù)的評(píng)測(cè)效果顯示,AquilaChat2-34B-16K處于開源長文本模型的領(lǐng)先水平,已經(jīng)接近GPT-3.5。
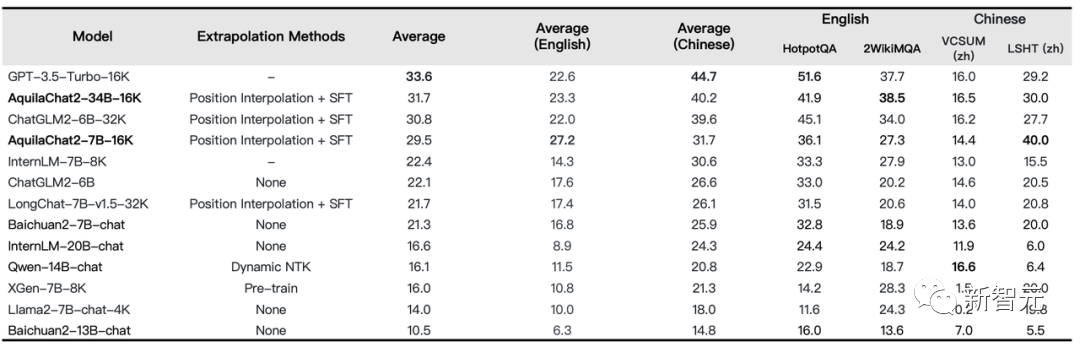
長文本理解任務(wù)評(píng)測(cè)
另外,我們都知道,大模型普遍存在著長度外延能力不足的問題,這個(gè)問題嚴(yán)重制約了大模型的長文本能力。
智源聯(lián)合北大團(tuán)隊(duì),對(duì)多個(gè)語言模型處理超長文本的注意力分布做了可視化分析。他們發(fā)現(xiàn):所有語言模型均存在固定的相對(duì)位置瓶頸,且顯著小于上下文窗口長度。
為此,智源團(tuán)隊(duì)創(chuàng)新性地提出了NLPE(Non-Linearized Position Embedding,非線性位置編碼)方法,在RoPE方法的基礎(chǔ)上,通過調(diào)整相對(duì)位置編碼、約束最大相對(duì)長度,來提升模型外延能力。
在代碼、中英文Few-Shot Leaning、電子書等多個(gè)領(lǐng)域的文本續(xù)寫實(shí)驗(yàn)顯示,NLPE可以將4K的Aquila2-34B模型外延到32K長度,且續(xù)寫文本的連貫性遠(yuǎn)好于Dynamic-NTK、位置插值等方法。
如下圖所示,在長度為5K~15K的HotpotQA、2WikiMultihopQA等數(shù)據(jù)集上的指令跟隨能力測(cè)試顯示,經(jīng)過NLPE外延的AquilaChat2-7B(2K)準(zhǔn)確率為17.2%,而Dynamic-NTK外延的AquilaChat2-7B準(zhǔn)確率僅為0.4%。
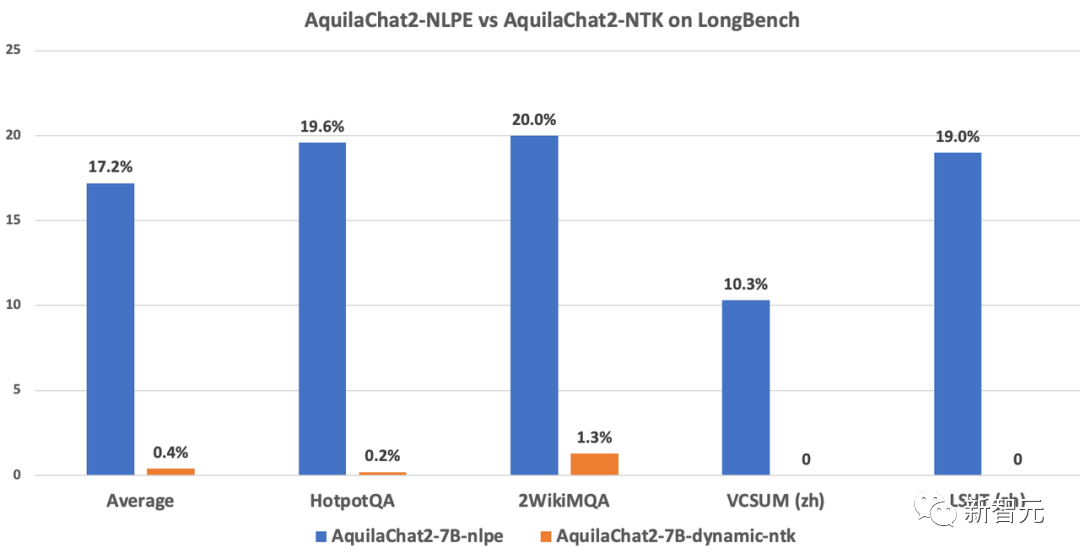
NLPE與主流Dynamic-NTK外延方法在SFT模型上的能力對(duì)比
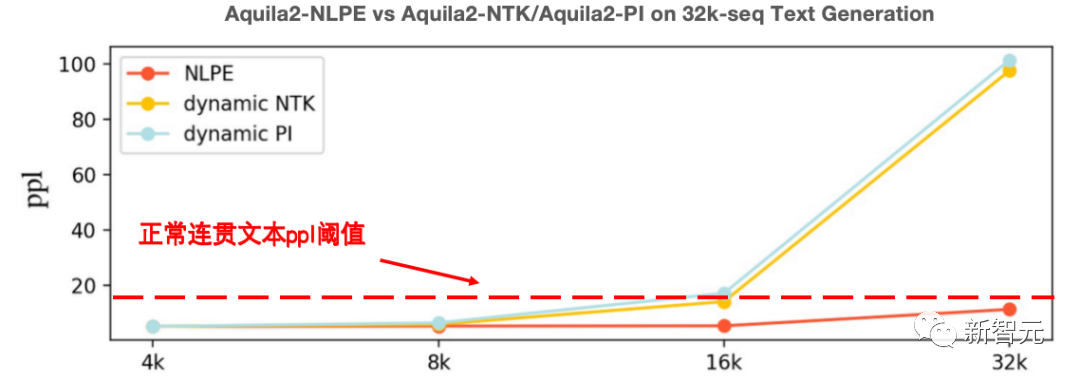
NLPE與主流Dynamic-NTK外延方法在Base模型上的能力對(duì)比(ppl值越低越好)
同時(shí),智源團(tuán)還開發(fā)了適配長文本推理的分段式Attention算子PiecewiseAttention,來高效地支持NLPE等面向Attention Map的優(yōu)化算法,進(jìn)一步減少顯存占用、提升運(yùn)算速度。
泛化能力超強(qiáng),絕不「高分低能」
說起來,許多大模型雖然在標(biāo)準(zhǔn)測(cè)試中表現(xiàn)出色,一到實(shí)際應(yīng)用的時(shí)候卻抓瞎了。
相比之下,Aquila2模型在考試上成績(jī)優(yōu)異,在真實(shí)應(yīng)用場(chǎng)景的表現(xiàn)又如何呢?
要知道,大模型泛化能力,也就是舉一反三的能力至關(guān)重要。

這意味著,LLM在訓(xùn)練數(shù)據(jù)之外,依然能夠有效應(yīng)對(duì)沒有見過的任務(wù),給出準(zhǔn)確的響應(yīng)。
若是這個(gè)大模型在基準(zhǔn)測(cè)試中取得高分,但在實(shí)際應(yīng)用中表現(xiàn)很差,也就是擅長考題但不善于解決實(shí)際問題,是「高分低能」的表現(xiàn)。
為了評(píng)估Aquila2模型的泛化能力,智源團(tuán)隊(duì)從三個(gè)真實(shí)應(yīng)用場(chǎng)景下對(duì)其進(jìn)行了驗(yàn)證。
AI智能體在「我的世界」自主思考
通用智能體,能夠在開放式的環(huán)境中學(xué)習(xí)多種任務(wù),是模型重要能力的體現(xiàn)。
一提到智能體任務(wù)的測(cè)試,我們能想到的最常見的開放世界游戲,當(dāng)然就是「我的世界」了。
這里有著無限生成的復(fù)雜世界和大量開放的任務(wù),為智能體提供豐富的交互接口。
今年3月,智源團(tuán)隊(duì)曾提出了在無專家數(shù)據(jù)的情況下,高效解決「我的世界」多任務(wù)的方法——Plan4MC。
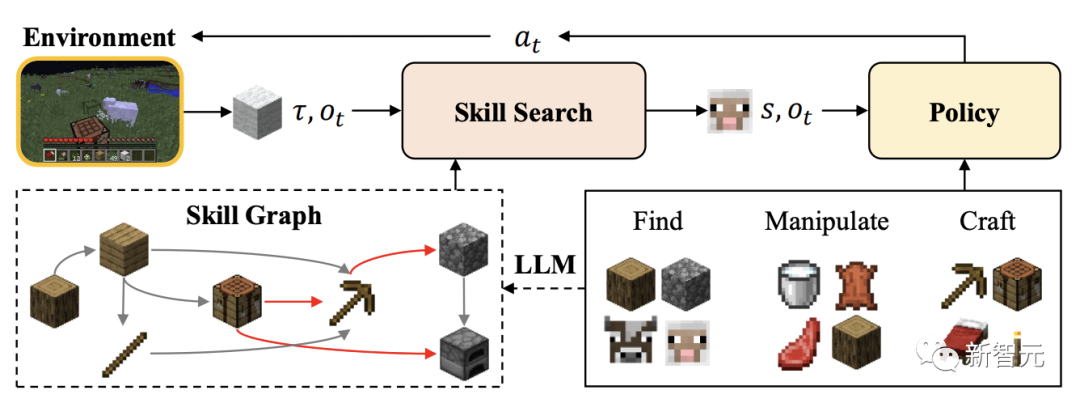
Plan4MC通過內(nèi)在獎(jiǎng)勵(lì)的強(qiáng)化學(xué)習(xí)方法,訓(xùn)練智能體的基本技能。
然后,智能體利用大模型AquilaChat2的推理能力,完成任務(wù)規(guī)劃。

比如,當(dāng)智能體收到「伐木并制作工作臺(tái)放在附近」的任務(wù)后,就會(huì)與AquilaChat2進(jìn)行多輪對(duì)話交互。
首先,智能體明確自己的主任務(wù)是——建造工作臺(tái),由此輸入prompt,包括「當(dāng)前環(huán)境狀態(tài)」、「需要完成的任務(wù)」。

然后AquilaChat2收到命令后,便開始做出反饋,告訴智能體「下一步使用什么技能」,同時(shí)還確定了下一個(gè)子任務(wù)為:尋找附近的木頭。
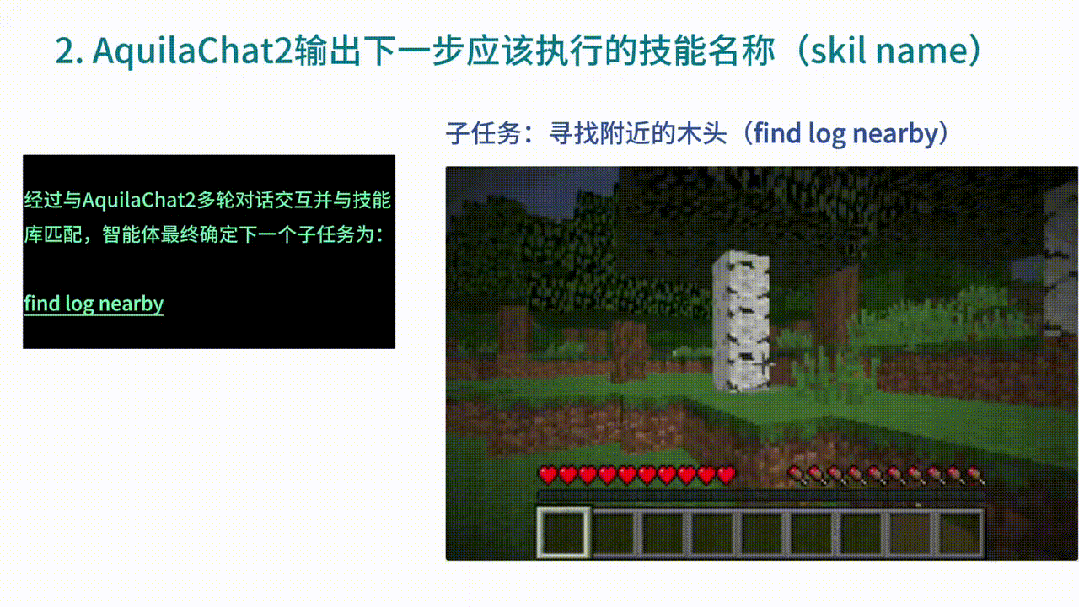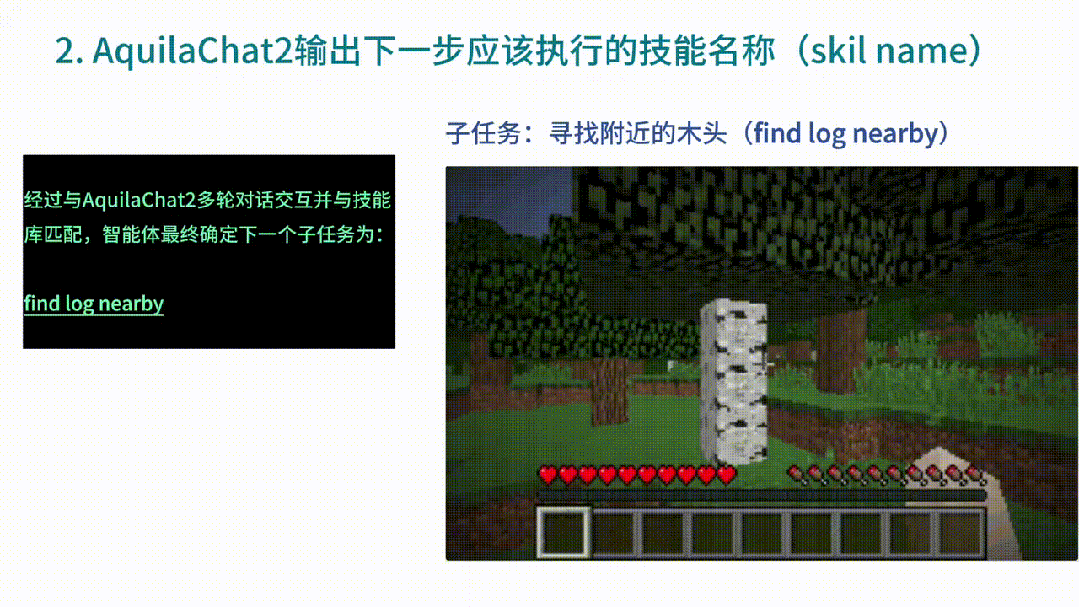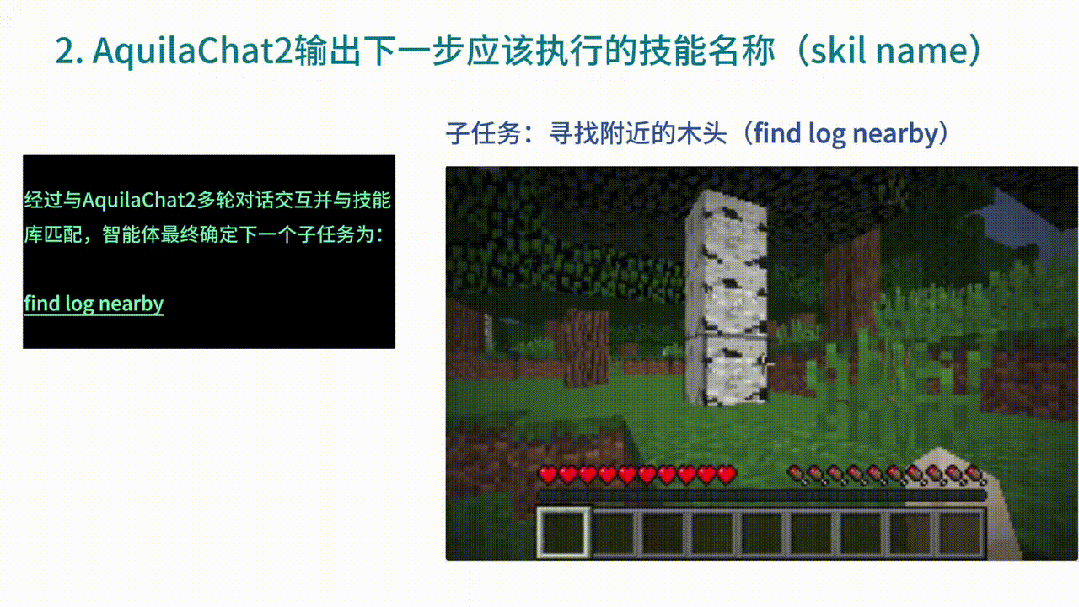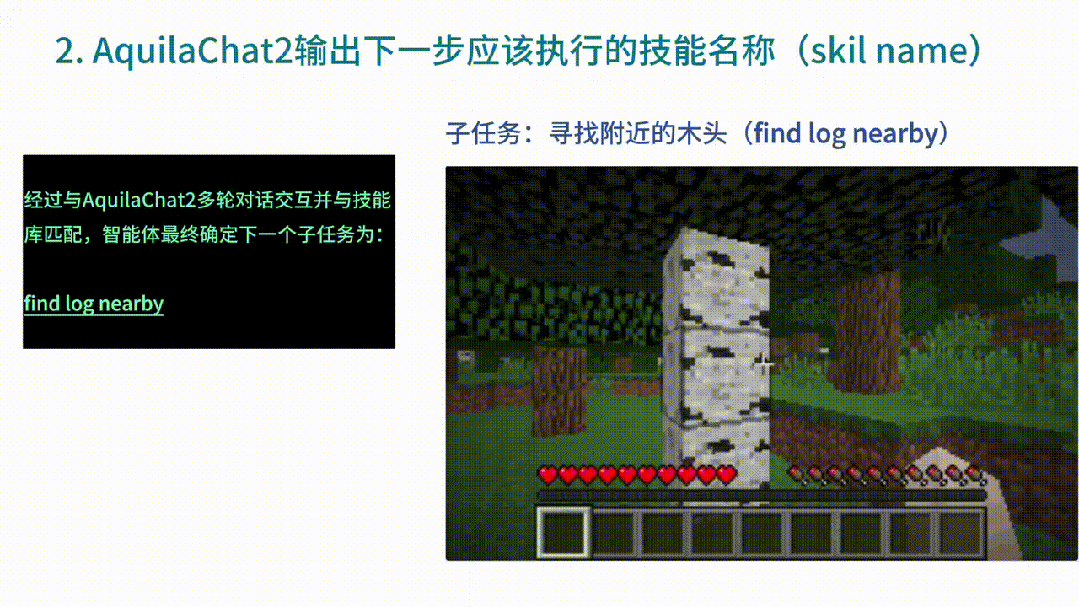
智能體找到木頭后,下一個(gè)子任務(wù)便是伐木。繼續(xù)將環(huán)境信息作為輸入,由此,AquilaChat2給出了下個(gè)技能名稱。

以此往復(fù),智能體繼續(xù)推進(jìn)自己朝著總目標(biāo)方向,與AquilaChat2進(jìn)行交互,完成任務(wù)。
就這樣,在AquilaChat2的幫助下,智能體搭出了完美的工作臺(tái)。

Aquila2+BGE2,復(fù)雜文獻(xiàn)也能檢索
復(fù)雜文獻(xiàn)的檢索,讓不少科研工作者頭禿。
基于傳統(tǒng)向量庫的檢索方式,大模型能夠在一些簡(jiǎn)單問題上表現(xiàn)出色。
然而,當(dāng)面對(duì)復(fù)雜、需要深度理解的問題時(shí),它的能力就很有限。
智源將Aqiula2與開源的語義向量模型BGE2結(jié)合,徹底解決了這一大難題。
當(dāng)你想要檢索某位作者,關(guān)于某個(gè)主題的論文時(shí),又或者要求大模型針對(duì)一個(gè)主題的多篇論文的生成總結(jié)文本,就不是難題了。

舉個(gè)栗子,讓Aqiula2給出Mirella Lapata所著關(guān)于「總結(jié)」的論文。
Aqiula2立馬給出了符合要求的復(fù)雜文獻(xiàn)。

Aquila2+BGE2文獻(xiàn)檢索場(chǎng)景復(fù)雜查詢示例
AquilaSQL:最優(yōu)「文本-SQL語言」生成模型
而AquilaSQL,則可以充當(dāng)「翻譯員」,將用戶發(fā)出的自然語言指令,準(zhǔn)確翻譯為合格的SQL查詢語句。
這樣,數(shù)據(jù)查詢分析的門檻,就大大降低了。
在實(shí)際應(yīng)用場(chǎng)景中,用戶還可以基于AquilaSQL進(jìn)行二次開發(fā),將其嫁接至本地知識(shí)庫、生成本地查詢SQL。
另外,還可以進(jìn)一步提升模型的數(shù)據(jù)分析性能,讓模型不僅返回查詢結(jié)果,更能進(jìn)一步生成分析結(jié)論、圖表等。
Aquila基座模型本身就具有優(yōu)秀的代碼生成能力。
在此基礎(chǔ)上,AquilaSQL經(jīng)過了SQL語料的繼續(xù)預(yù)訓(xùn)練和SFT兩階段訓(xùn)練,最終以67.3%準(zhǔn)確率,超過「文本-SQL語言生成模型」排行榜Cspider上的SOTA模型,而未經(jīng)SQL語料微調(diào)的GPT4模型。準(zhǔn)確率僅為30.8%。
在下圖中,我們讓AquilaSQL從身高(height)、收入(income)和位置(location)三個(gè)數(shù)據(jù)表中,篩選「居住在北京的收入大于1000的人平均身高」。

AquilaSQL開源倉庫地址:https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila/Aquila-sql
AquilaSQL順利地生成了多表查詢語句,完成了這個(gè)復(fù)雜查詢?nèi)蝿?wù)。
「全家桶」級(jí)別開源,業(yè)界良心
一個(gè)冷知識(shí)是,雖然Llama2也開源,但它的商用許可協(xié)議,對(duì)中文用戶并不那么友好。
而且,Llama2不僅在中文商用上設(shè)限,連對(duì)商用的月活都有限制。

Llama 2商業(yè)協(xié)議明確表示不允許英文以外的商業(yè)
相比之下,Aquila在全球范圍內(nèi)都可商用——既不像Llama2那樣限制重重,也不像其他可商用模型一樣需要填表登記。
此外,很多模型團(tuán)隊(duì)在開源時(shí),并不會(huì)開源模型訓(xùn)練的超參、優(yōu)化方案等關(guān)鍵數(shù)據(jù)。而Aquila2此次卻是全部開源創(chuàng)新訓(xùn)練算法,BGE、FlagScale、FlagAttention,都全部分享給了開發(fā)者。
通過這套工具,開發(fā)者就以輕松復(fù)現(xiàn)Aquila2了。
這種史無前例的「全家桶」開源,簡(jiǎn)直是大模型開源界的YYDS!
之所以毫無保留地開源訓(xùn)練工具和算法,是基于智源非盈利機(jī)構(gòu)的定位——通過徹底、全面的開源分享,促進(jìn)全球大模型生態(tài)的繁榮。
新一代語義向量模型BGE2
BGE(BAAI General Embedding)是智源在今年8月全新開源的語義向量模型。
這次,新一代BGE2也將隨著Aquila2同步開源。
BGE2中的BGE-LLM Embedder模型集成了「知識(shí)檢索」、「記憶檢索」、「示例檢索」、「工具檢索」四大能力。
它首次實(shí)現(xiàn)了單一語義向量模型對(duì)大語言模型主要檢索訴求的全面覆蓋。
結(jié)合具體的使用場(chǎng)景,BGE-LLM Embedder將顯著提升大語言模型在處理知識(shí)密集型任務(wù)、長期記憶、指令跟隨、工具使用等重要領(lǐng)域的表現(xiàn)。
高效并行訓(xùn)練框架FlagScale
FlagScale是Aquila2-34B使用的高效并行訓(xùn)練框架,能夠提供一站式語言大模型的訓(xùn)練功能。
得益于智源團(tuán)隊(duì)的分享,大模型開發(fā)者便可以通過FlagScale項(xiàng)目獲取Aquila2模型的訓(xùn)練配置、優(yōu)化方案和超參數(shù)。
FlagScale開源代碼倉庫:https://github.com/FlagOpen/FlagScale
因此,智源也成為「國內(nèi)首個(gè)」完整開源訓(xùn)練代碼和超參數(shù)的大模型團(tuán)隊(duì)。
FlagScale是在Megatron-LM基礎(chǔ)上擴(kuò)展而來,提供了一系列功能增強(qiáng),包括分布式優(yōu)化器狀態(tài)重切分、精確定位訓(xùn)練問題數(shù)據(jù),以及參數(shù)到Huggingface轉(zhuǎn)換等。
經(jīng)過實(shí)測(cè),Aquila2訓(xùn)練吞吐量和GPU利用率均達(dá)到業(yè)界領(lǐng)先水平。
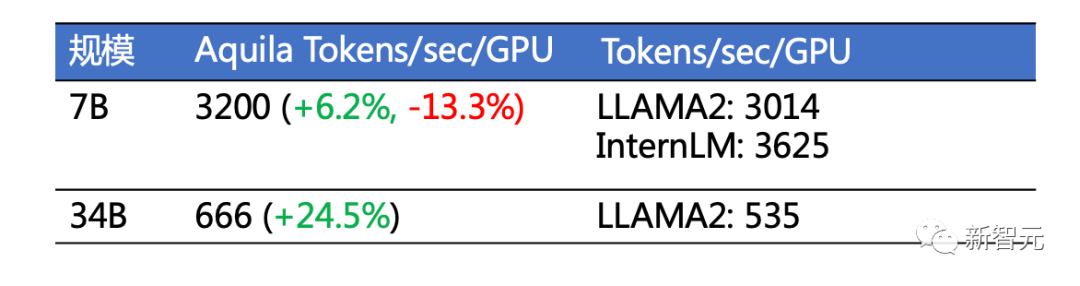
FlagScale訓(xùn)練吞吐量與GPU利用率
此外,F(xiàn)lagScale還采用了多種并行技術(shù),如數(shù)據(jù)并行、張量并行和1F1B流水線并行等,加速訓(xùn)練過程,并使用BF16進(jìn)行混合精度進(jìn)行訓(xùn)練。
在性能優(yōu)化方面,F(xiàn)lagScale采用了FlashAttn V2、計(jì)算與通信重疊、梯度累積等技術(shù),顯著提升了計(jì)算效率。
未來,F(xiàn)lagScale將繼續(xù)保持與上游項(xiàng)目Megatron-LM最新代碼同步,引入更多定制功能,融合最新的分布式訓(xùn)練與推理技術(shù)以及主流大模型、支持異構(gòu)AI硬件。
這樣就可以構(gòu)建一個(gè)通用、便捷、高效的分布式大模型訓(xùn)練推理框架,以滿足不同規(guī)模和需求的模型訓(xùn)練任務(wù)。
開源算子集FlagAttention
另外,F(xiàn)lagAttention是首個(gè)支持長文本大模型訓(xùn)練、使用Triton語言開發(fā)的定制化高性能Attention開源算子集。
針對(duì)大模型訓(xùn)練的需求,對(duì)Flash Attention系列的Memory Efficient Attention算子進(jìn)行擴(kuò)展。
目前已實(shí)現(xiàn)分段式Attention算子——PiecewiseAttention,已經(jīng)適配了國產(chǎn)芯片天數(shù),后續(xù)還會(huì)適配更多異構(gòu)芯片。
FlagAttention開源代碼倉庫:https://github.com/FlagOpen/FlagAttention
PiecewiseAttention主要解決了帶旋轉(zhuǎn)位置編碼Transformer模型(Roformer)的外推問題。
大模型推理時(shí)的序列長度超出訓(xùn)練時(shí)最大序列長度時(shí),距離較遠(yuǎn)的token之間的Attention權(quán)重異常增高。
而Flash Attention對(duì)Attention Score的計(jì)算采用分段式的處理時(shí)無法做到高效實(shí)現(xiàn),因此智源團(tuán)隊(duì)自研了分段式PiecewiseAttention算子,大模型開發(fā)者可利用該開源算子實(shí)現(xiàn)更加靈活的前處理。
簡(jiǎn)單來說,PiecewiseAttention有以下幾個(gè)特點(diǎn):
- 通用性:對(duì)使用分段式計(jì)算Attention的模型具有通用性,可以遷移至Aquila之外的大語言模型。
- 易用性:FlagAttention基于Triton語言實(shí)現(xiàn)并提供PyTorch接口,構(gòu)建和安裝過程相比CUDA C開發(fā)的Flash Attention更加便捷。
- 擴(kuò)展性:同樣得益于Triton語言,F(xiàn)lagAttention算法本身的修改和擴(kuò)展門檻較低,開發(fā)者可以便捷地在此之上拓展更多新功能。
未來,F(xiàn)lagAttention項(xiàng)目也將繼續(xù)針對(duì)大模型研究的需求,支持其他功能擴(kuò)展的Attention算子,進(jìn)一步優(yōu)化算子性能,并適配更多異構(gòu)AI硬件。
開發(fā)者指南:快速上手Aquila2
Aquila2模型權(quán)重&代碼倉庫:
使用方式一(推薦):通過FlagAI加載Aquila2系列模型
https://github.com/FlagAI-Open/Aquila2
使用方式二:通過FlagOpen模型倉庫單獨(dú)下載權(quán)重
使用方式三:通過Hugging Face加載Aquila2系列模型
Aquila2全系列兼容多個(gè)大模型生態(tài)開源項(xiàng)目:
? LoRA/QLoRA:輕量化的模型微調(diào)訓(xùn)練技術(shù),既加速了大模型訓(xùn)練,同時(shí)也降低了顯存占用。
? vLLM:支持構(gòu)建高吞吐量的大語言模型服務(wù),支持流式輸出,支持單機(jī)多卡、分布式并行推理。
? llama.cpp:支持非GPU端和4-bit 量化,進(jìn)一步降低開發(fā)者的的使用門檻。






























