













玩轉(zhuǎn)圍棋、國際象棋、撲克,DeepMind推出通用學(xué)習(xí)算法SoG
2016 年 3 月,一場機(jī)器人與圍棋世界冠軍、職業(yè)九段棋手李世石展開的圍棋人機(jī)大戰(zhàn)受到全球的高度關(guān)注。我們知道,最后的結(jié)果是 DeepMind 的機(jī)器人 AlphaGo 以 4 比 1 的總比分獲勝。這是人工智能領(lǐng)域一個里程碑性的事件,也讓「博弈」成為一個熱門的 AI 研究方向。
AlphaGo 之后,DeepMind 又推出了贏得國際象棋的 AlphaZero、擊敗《星際爭霸 II》的 AlphaStar 等等。使用搜索和學(xué)習(xí)的方法,AI 在許多完美信息博弈中表現(xiàn)出強(qiáng)大的性能,而使用博弈論推理和學(xué)習(xí)的方法在特定的不完美信息博弈中表現(xiàn)出強(qiáng)大的性能。
然而,大多數(shù)成功案例有一個重要的共同點:專注于單一博弈項目。例如,AlphaGo 不會下國際象棋,而 AlphaZero 雖然掌握了三種不同的完美信息博弈,但 AlphaZero 無法玩撲克牌,也不清楚能否擴(kuò)展到不完美信息博弈。此外,現(xiàn)有研究往往會使用特定領(lǐng)域的知識和結(jié)構(gòu)使 AI 實現(xiàn)強(qiáng)大的性能。
現(xiàn)在,來自 Google Deepmind 的研究團(tuán)隊提出了一種利用自我博弈學(xué)習(xí)、搜索和博弈論推理實現(xiàn)強(qiáng)大博弈性能的通用學(xué)習(xí)算法 ——Student of Games(SoG)。研究論文發(fā)表在《Science Advances》上。

論文地址:https://www.science.org/doi/full/10.1126/sciadv.adg3256
SoG 算法結(jié)合了引導(dǎo)式搜索(guided search)、自我對弈(self-play)學(xué)習(xí)和博弈論推理(game-theoretic reasoning)。實驗結(jié)果表明,SoG 可以在大型完美和不完美信息博弈中表現(xiàn)出強(qiáng)大的性能,這是邁向任意環(huán)境真正通用算法的重要一步。
方法簡介
SoG 模型可以在不同的游戲中自由發(fā)揮,并教會自己如何與自己的另一個版本進(jìn)行對戰(zhàn),能夠?qū)W習(xí)新策略并逐漸變得更有能力。雖然 AlphaZero 也可以適應(yīng)完美信息博弈,但 SoG 可以適應(yīng)完美和不完美信息博弈,從而具有更強(qiáng)的通用性。
SoG 采用成長樹虛擬遺憾最小化(growing-tree counterfactual regret minimization,GT-CFR)算法。GT-CFR 算法是一種隨時可以進(jìn)行局部搜索,非均勻地構(gòu)建子博弈,并將樹擴(kuò)展至最相關(guān)的未來狀態(tài),同時可以迭代地細(xì)化價值與策略。
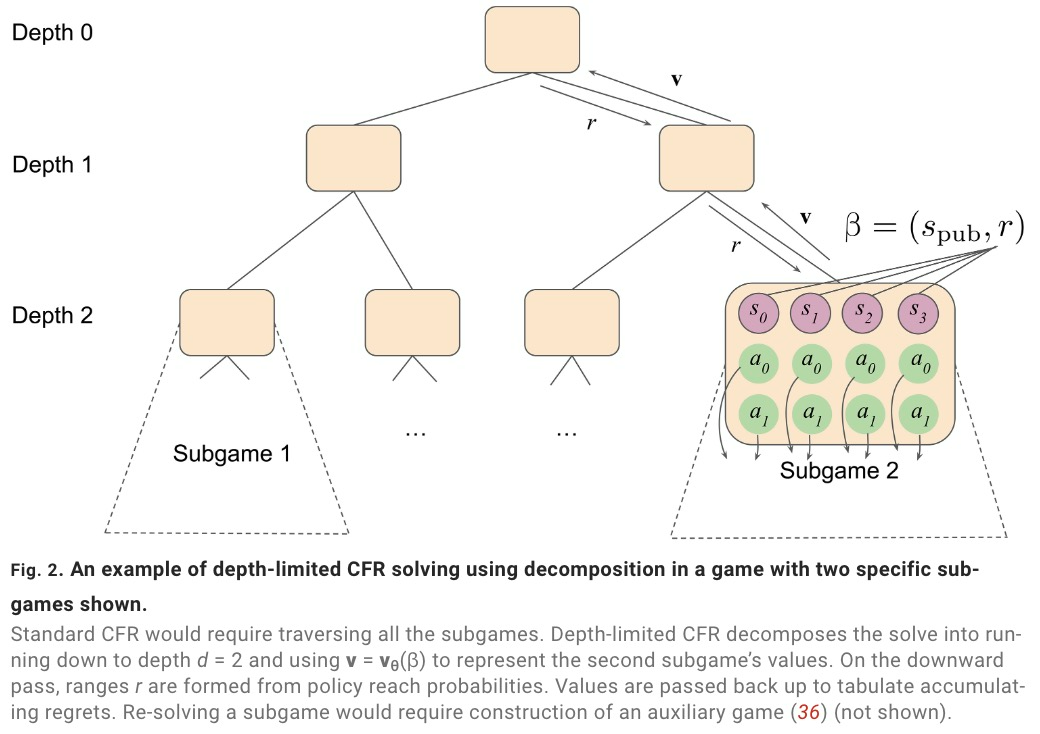
此外,SoG 還采用了有效的自我對弈:利用博弈結(jié)果和遞歸子搜索來訓(xùn)練價值與策略網(wǎng)絡(luò),并應(yīng)用于之前搜索中出現(xiàn)過的情況。
SoG 算法通過聲音自我對弈來訓(xùn)練智能體:每個玩家在面臨決策時,使用配備虛擬價值與策略網(wǎng)絡(luò)(Counterfactual Value-and-Policy Network,CVPN)的聲音 GT-CFR 搜索來生成當(dāng)前狀態(tài)的策略,并根據(jù)該策略采取行動。

自我對弈過程會生成兩種類型的訓(xùn)練數(shù)據(jù),用于更新價值與策略網(wǎng)絡(luò),一種是搜索查詢,一種是完整博弈軌跡。在實際應(yīng)用中,自我對弈數(shù)據(jù)生成和訓(xùn)練是并行發(fā)生的:參與者生成自我對弈數(shù)據(jù)(并解決查詢);訓(xùn)練者學(xué)習(xí)新網(wǎng)絡(luò)并定期更新參與者。
實驗結(jié)果
眾所周知,傳統(tǒng)搜索在不完美信息博弈中存在缺陷,并且評估集中在單一領(lǐng)域(如撲克牌),SoG 填補(bǔ)了這一空白。通過重新解決子博弈,SoG 保證可以找到近似納什均衡,并且在小型博弈中保證可計算性。
具體來說,SoG 在四種不同的游戲中展示了強(qiáng)大的性能:兩種完美信息博弈(國際象棋和圍棋)和兩種不完美信息博弈(撲克和 Scotland Yard)。值得注意的是,與撲克相比,Scotland Yard 的搜索范圍和游戲長度要長得多,需要長期規(guī)劃。
SoG 與 AlphaZero 一樣,利用最少的領(lǐng)域知識,將搜索與自我對弈相結(jié)合。與 MCTS 不同,SoG 的搜索算法基于虛擬遺憾最小化,對完美和不完美信息博弈都是有效的。
下圖展示了 SoG 在不同數(shù)量 GT-CFR 下的可利用性。

A 表為 Leduc 撲克,B 表為蘇格蘭場
下圖展示了 SoG 隨著神經(jīng)網(wǎng)絡(luò)評估次數(shù)的增加與 AlphaZero 可擴(kuò)展性的比較,測量方式為相對 Elo 評分尺度。

A 表為國際象棋,B 表為圍棋






















