DeepMind長文掀開AlphaZero黑盒 神經網絡所學知識和人類基本相似
AlphaZero下棋和人類下棋究竟有什么區別?是否掌握了一些人類未曾了解過的知識?DeepMind最近攜手國際象棋世界冠軍發69頁論文,深度解剖AlphaZero后發現,神經網絡學到的知識和人類基本相似!
機器學習系統通常被認為是不透明的、不可預測的,和人類所接受的訓練幾乎沒有任何共通之處。
難道,黑盒模型和可解釋性的學習注定是兩條路?
但最近有研究表明,至少在某些情況下,神經網絡能夠學習到一些人類可理解的表征!
例如分類器中的單個神經元可以表示一些語義信息,語言模型中也包含語法信息,在視覺和文本數據的對齊數據中也能發現一些復雜的概念表示,這些神經網絡學到的概念都和人類接受的概念訓練相關。
但還有一個問題,這些學習到的概念是通用的嗎?我們是否也希望其他深度學習的系統具有類似的有意義的表示?
如果這些問題的答案都是沒有的話,那么一些關于反映模型計算過程可解釋性的研究將受到種種限制,并且很難找到其他合理的方法來解釋。
雖然上面提到的幾個例子能一定程度上能展現機器學習模型能夠理解人類的語義,但本質上是因為它們只能接觸到人類生成的數據,并且在分類任務中是將人類的類別概念強加給模型才導致它們能捕捉到類別語義。
或者說,這些任務也相對簡單,解釋起來也更加容易。
為了進一步測試機器學習模型是否真正獲取到了人類可理解概念(human-understandable concepts),需要找到一個在沒有使用人類標簽數據的情況下,表現出超越人類表現的模型。
這不巧了嗎?AlphaZero就同時滿足這兩個要求。
首先,AlphaZero是通過self-play的方式訓練的,所以從未接觸過人類數據,并且它在國際象棋,圍棋和將棋(Shogi)這三項競技游戲上借助蒙特卡洛樹搜索成功戰勝人類。
所以AlphaZero就成了研究機器學習模型和人類理解之間關系的一座重要橋梁,如果AlphaZero中能找到人類可理解的概念,那其他模型應該也會有!
說干就干!
DeepMind、Google Brain的研究人員攜手國際象棋世界冠軍共同打造了一篇長達69頁的論文,主要研究了像AlphaZero這樣的超越人類的神經網絡模型正在學習什么,這是一個既科學又實用的問題。
在論文中研究人員證明了人類獲取知識和AlphaZero在國際象棋中獲得的知識都是相似的。并通過對大量人類關于國際象棋的概念的探索,還可以觀察到其中一些概念在AlphaZero網絡是如何表示的。

https://arxiv.org/abs/2111.09259
論文中邀請到的國際象棋大師是弗拉基米爾·克拉姆尼克(Vladimir Kramnik),俄羅斯著名國際象棋手,1992年獲特級大師頭銜。2000年至2007年,是國際象棋世界冠軍。他的等級積分為2801分,世界排名第四(活躍選手排名第三)。
研究方法主要分為三個方面:
1、概念的探測(Probe of Concepts)
研究人員的首要任務是研究AlphaZero的內部表征,即其神經網絡內神經元的激活(activation)情況是否與人類關于國際象棋的概念相關。
如果從網絡的內部表示可以很容易地預測人類概念,那么通過深入研究來揭示更多的信息也是有可能的。如果學習到的表征與人類概念沒有關系,那么AlphaZero的內部計算在進一步研究后可能仍然不透明。
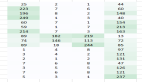
基于概念的方法就是在一個大的輸入數據集上從網絡激活中檢測人類概念。因為國際象棋經過多年的發展,已經是高度理論化了,所以已經有大量現成的人類定義過的概念可以使用,并且這些概念也足夠復雜。而所有這些概念結合在一起就能夠得到一次完整的位置評估(position evaluation)。
此外,整個探索過程是自動化的,因此研究人員可以在self-play訓練中探索每個概念、每個區塊和多個檢查點,從而能夠建立一個學習內容的藍圖。
當然,基于概念的方法遠遠不是理解神經網絡計算的唯一方法,
2、研究行為變化(Study behavioural changes)
在研究了內部表征如何隨著時間的推移而變化之后,自然要研究這些變化的表征是如何導致行為變化的。
在訓練過程中,有些動作(move)優先于處于相同位置的其他動作,這種偏好會隨著訓練進程而發展。
當AlphaZero在沒有蒙特卡羅樹搜索(MCTS)的情況下運行時,行為變化僅限于其先前動作選擇概率的變化。通過測量一組棋局某一手的動作概率變化能夠發現模型行為的變化,并將self-play訓練中的游戲演變與高級人類游戲中運動選擇的演變進行比較。
3、直接研究激活(Investigate activations directly)
在確定了許多人類概念可以從Alphazero的訓練后激活中預測出來后,就可以開始研究這些網絡神經元的激活究竟是什么情況了。
研究人員使用非負矩陣因子分解(NMF)技術將AlphZero的表征分解為多個因子。這種方法提供了與現有人類概念無關的信息,也提供了AlphaZero網絡計算內容的補充視圖。
直接測量單神經元激活和輸入之間的協方差也是一種方案,這種方法能夠提供輸入特征的組合,找到哪些特征的存在與給定神經元的激活最相關。
最后研究結果發現:
許多人類的概念都可以在AlphaZero網絡中找到。
研究人員證明了AlphaZero網絡的國際象棋內部學習表征可以用來可靠地重建許多人的象棋概念。采用概念激活向量(CAV)的方法,通過訓練稀疏線性探針來處理更廣泛的概念。這也表明相關信息是由AlphaZero網絡計算的。
結果還表明,雖然AlphaZero的象棋知識似乎與人類的概念探針密切相關,但它們之間確實存在差異,因為重建往往是不完整的。
通過使用概念探針方法論(concept probing methodology),可以衡量訓練過程中以及網絡中每個層相關信息的出現情況,這也能夠繪制出一副模型何時何地發現什么概念的一副畫面。
研究人員還發現,許多概念在訓練的早期就出現驚人的一致性,AlphaZero的動作選擇也會迅速發生變化。
概念的使用和相對概念值(Use of Concept and Relative concept value)側重于描述 AlphaZero值函數隨時間的演變。
研究人員再次使用了一種基于概念的方法試圖預測一組人類概念的價值函數的輸出。通過研究訓練過程中概念權重的演變,可以看到AlphaZero的行為如何與高水平的人體象棋概念相關,這也是其下棋風格(style)的一種展現。
可以發現,早期的AlphaZero訓練主要集中在材料(material)中更復雜和微妙的概念。如King Safety和Mobility,作為價值函數的重要預測因素,在訓練過程較晚中才會出現。
分析表明,人類下棋的發展過程和AlphaZero既有相似之處,也有差異。AlphaZero并沒有回顧人類下棋的發展歷程,而是從一些招式直接開始訓練。但在self-play策略上,人類和AlphaZero基本是相似的。
也許,神經網絡的發展終于到了要揭開黑盒的時候了,看一看到底是不是和生物學神經相同!