譯者 | 朱先忠
審校 | 重樓
簡介
在一款完美的信息類游戲中,如果你所需要的一切都能夠讓每一個玩家在游戲規則中看到,這不是一件很神奇的事情嗎?
但遺憾的是,對于像我這樣的普通玩家來說,閱讀有關一款新游戲的玩法規則只是學習玩復雜游戲旅程中的一小部分,而大部分時間都花在玩游戲當中,當然最好是與實力相當的玩家(或者有足夠耐心幫助我們暴露弱點的更好些的玩家)比賽。經常輸掉游戲和希望獲勝有時會帶來一定的心理懲罰和獎勵,不過這將引導我們逐漸把游戲玩得更好。
也許,在不久的將來,AI語言模型能夠讀取類似于國際象棋這樣的復雜游戲的規則,并從一開始就盡可能達到最高水平。與此同時,我提出了一種更溫和的挑戰方式——通過自我游戲學習。
在本文提供的這個實戰項目中,我們將訓練一個AI助理,它能夠通過觀察以前版本的游戲結果來學習玩完美信息的雙人游戲。其中,AI助理負責近似化此游戲狀態的任何數值(游戲預期結果)。作為一個額外的挑戰,我們的AI助理將不被允許維護狀態空間的查找表,因為這種方法對于復雜的游戲來說是不可管理的。
求解SumTo100游戲
游戲規則簡介
我們要討論的游戲是SumTo100。此游戲的目標是通過對1到10之間的數字進行加法運算來達到100的總和。以下是此游戲遵循的規則:
- 初始化總和為0。
- 選擇第一個玩家;兩名選手輪流上場。
- 當總和小于100時:
- 玩家選擇一個介于1和10之間的數字(包括1和10)。所選數字將添加到總和中,但不超過100。
- 如果總和小于100,則另一個玩家進行游戲(即,我們回到第3步的開始處)。
- 加上最后一個數字(達到100)的玩家獲勝。

兩只蝸牛自顧自的樣子(作者本人圖片,基于OpenAI推出的第二代圖像生成式人工智能模型DALL-E2制作)
我們選擇從這樣一款簡單的游戲開始,這樣的做法存在很多優點:
- 狀態空間只有101個可能的值。
- 這些狀態可以繪制在1D網格上。這種特性將使我們能夠將AI助理學習的狀態值函數很容易表示為1D條形圖。
- 最佳策略是已知的:-求和為11n+1,其中n∈{0,1,2,…,9}于是,我們可以很容易地對游戲中最優策略的狀態值進行可視化展示:
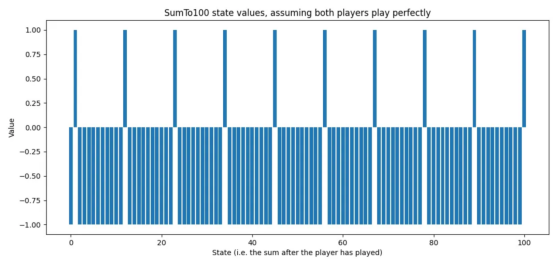 圖1:SumTo100游戲的最佳狀態值(作者本人的圖片)
圖1:SumTo100游戲的最佳狀態值(作者本人的圖片)
此圖中,游戲狀態為AI助理完成其回合后的總和。值為1.0意味著,AI助理肯定會贏(或已經贏);而值為-1.0意味著AI助理一定會輸(假設對手發揮最佳);中間值表示估計的回報值。例如,狀態值為0.2表示略微正的狀態,而狀態值為-0.8表示可能的損失。
如果您想對代碼進行深入研究,那么執行整個訓練過程的腳本就是learn_sumTo100.sh,對應的開源存儲庫地址是https://github.com/sebastiengilbert73/tutorial_learnbyplay。如果感覺不必要,那么請耐心等待,因為接下來我們將對AI助理如何通過自我游戲學習進行詳細的描述。
生成隨機玩家玩的游戲
我們希望我們的AI助理能夠從以前版本的游戲中學習。但是,在游戲第一次迭代中,由于AI助理還沒有學到任何東西;所以,我們將不得不模擬隨機玩家玩的游戲。在每一個回合中,玩家都會從游戲管理庫(即編寫游戲規則的類)獲得當前游戲狀態下的合法動作列表。隨機玩家將從該列表中隨機選擇一次移動。
圖2展示了兩個隨機玩家玩游戲的示例:
 圖2:隨機玩家玩的游戲示例(作者本人的圖片)
圖2:隨機玩家玩的游戲示例(作者本人的圖片)
在這種情況下,第二個玩家通過達到100的總和贏得了游戲。
現在,我們來實現一個可以訪問神經網絡的AI助理,該神經網絡將游戲狀態(在助理玩過之后)作為輸入,并輸出該游戲的預期回報值。對于任何給定的狀態(在助理進行游戲之前),助理都會獲得有效動作的列表及其相應的候選狀態(我們只考慮具有確定性轉換的游戲)。
圖3顯示了AI助理、對手(其移動選擇機制是未知的)和游戲狀態管理庫之間的互動:
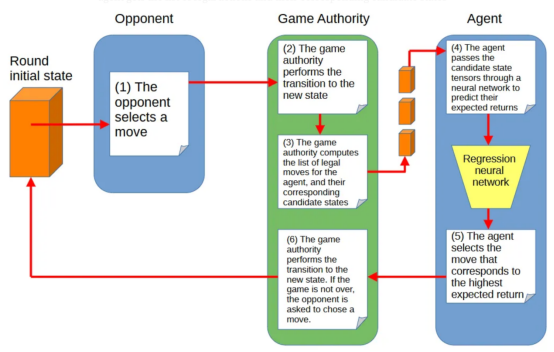 圖3:AI助理、對手和游戲管理庫之間的交互(作者本人的圖片)
圖3:AI助理、對手和游戲管理庫之間的交互(作者本人的圖片)
在這種設置中,AI助理依靠其回歸神經網絡來預測游戲狀態的預期回報值。神經網絡越能預測哪一個候選移動產生最高回報值,助理就越能發揮其作用。
我們的隨機玩法列表將為我們提供第一次訓練的數據集。以圖2中的示例游戲為例,我們想懲罰玩家1的動作,因為它的動作導致了失敗。最后一個動作產生的狀態值為-1.0,因為它允許對手獲勝。其他狀態通過γ?因子得到負值折扣。其中,d是相對于助理到達的最后狀態的距離;γ代表折扣因子,這個數范轉是[0,1],它表達了游戲進化中的不確定性:我們不想與最后一個決策那樣嚴厲地懲罰早期的決策。圖4顯示了與玩家1所做決策相關的狀態值:
 圖4:從玩家1的角度來看的狀態值列表(作者本人的圖片)
圖4:從玩家1的角度來看的狀態值列表(作者本人的圖片)
隨機游戲生成具有目標預期回報的狀態。例如,達到97的和時將對應值為-1.0的目標預期回報,而達到73的和時則對應于值為-γ3的目標預期收益。一半的狀態從玩家1的角度出發,另一半從玩家2的角度出發(盡管在SumTo100游戲中這并不重要)。當一場比賽以AI助理獲勝的結果結束時,相應的狀態會得到類似的折扣正值。
訓練AI代理以便預測比賽的結果
現在,我們準備好了開始訓練所需的一切:一個神經網絡(我們將使用兩層感知器)和一個(狀態,預期回報)數據對的數據集。接下來,讓我們看看預測預期回報值的損失是如何演變的:
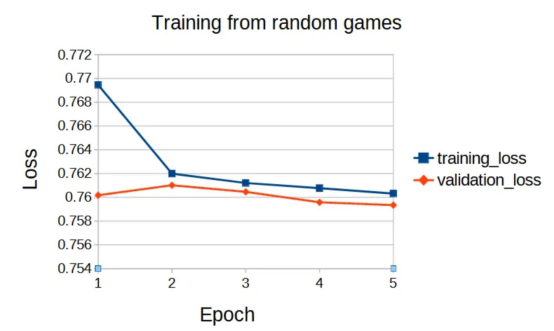 圖5:損失值隨訓練輪次的變化情況(作者本人的圖片)
圖5:損失值隨訓練輪次的變化情況(作者本人的圖片)
我們不應該感到驚訝的是,神經網絡對隨機玩家玩游戲的結果沒有表現出太大的預測能力。
那么,神經網絡到底學到了什么嗎?
幸運的是,由于狀態可以表示為0到100之間的1D數字網格;因此,我們可以繪制第一輪訓練后神經網絡的預測回報,并將其與圖1中的最佳狀態值進行比較:
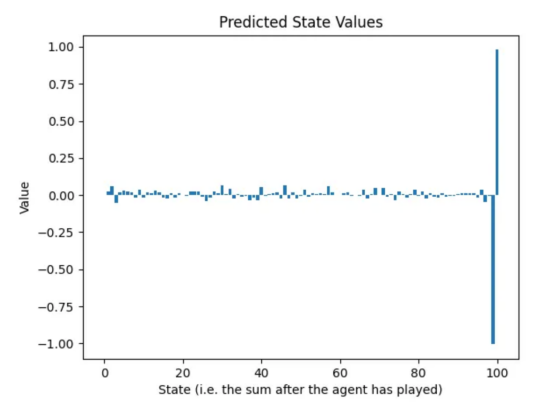 圖6:在隨機玩家玩的游戲數據集上訓練后的預測回報(作者本人的圖片)
圖6:在隨機玩家玩的游戲數據集上訓練后的預測回報(作者本人的圖片)
上述事實證明,通過隨機游戲的混亂狀態操作,神經網絡學到了兩件事:
- 如果你能達到100,就去做吧。考慮到這是比賽的目標,知道這一點很好。
- 如果你達到99,你肯定會輸。事實上,在這種情況下,對手只有一次有效動作,而這一動作會給AI助理帶來損失。至此,神經網絡基本上學會了完成游戲。
為了學會更好地發揮作用,我們必須通過使用新訓練的神經網絡模擬AI助理副本之間的游戲來重建數據集。為了避免生成相同的游戲,玩家會隨機玩一點。一種行之有效的方法是使用ε貪婪算法選擇動作,每個玩家的第一個動作使用ε=0.5,然后在游戲的其余部分使用ε=0.1。
與越來越好的玩家一起重復訓練循環
既然兩名玩家現在都知道他們必須達到100,那么達到90到99之間的總和應該受到懲罰,因為對手會抓住機會贏得比賽。這種現象在第二輪訓練后的預測狀態值中是可見的:
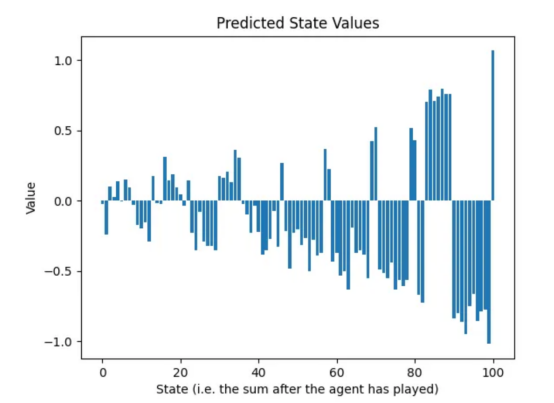 圖7:兩輪訓練后的預測狀態值:從90到99的總和顯示的值接近-1(作者本人的圖片)
圖7:兩輪訓練后的預測狀態值:從90到99的總和顯示的值接近-1(作者本人的圖片)
我們看到正在出現一種規律:第一輪訓練通知神經網絡關于最后一個動作;第二輪訓練通知倒數第二個動作,等等。我們需要重復游戲生成和預測訓練的循環,至少與游戲中的動作有一樣多的次數。
以下圖片顯示了第25輪訓練后預測狀態值的演變情形:
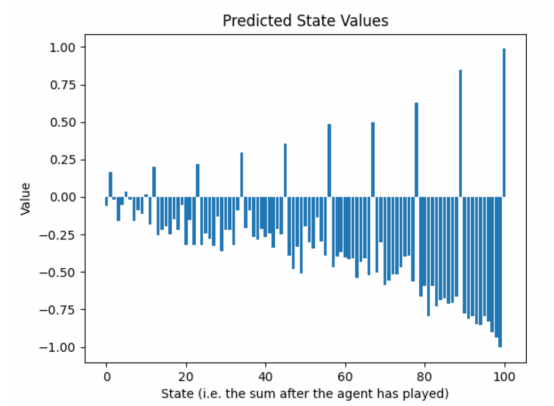 圖8:訓練過程中學習到的狀態值的瞬時截圖(作者本人的圖片)
圖8:訓練過程中學習到的狀態值的瞬時截圖(作者本人的圖片)
當我們從游戲的結束走向開始時,預測回報的包絡線指標值呈指數衰減。這是個問題嗎?
造成這種現象的因素有兩個:
- 當我們遠離比賽結束時,γ直接降低了目標的預期回報。
- ε貪婪算法在玩家動作中注入了隨機性,使結果更難預測。有動機預測接近零的值,以防止出現極高損失的情況。然而,隨機性是可取的,因為我們不希望神經網絡學習單一的游戲。我們希望神經網絡能夠見證AI助理和對手的失誤和意想不到的好動作。
在實際情況中,這應該不是一個問題,因為在任何情況下,我們都會比較給定狀態下的有效動作的值,這些動作具有可比的規模,至少在SumTo100游戲中是這樣。當我們選擇使用貪婪法移動時,數值的規模并不重要。
結論
本文中我們成功實現了對自己的挑戰——開發了一個AI助理,它可以學習掌握一個涉及兩個玩家的完美信息游戲,并能夠實現在給定一個動作的情況下,從一個狀態到下一個狀態的確定性轉換。實現過程中,不允許使用任何手動編碼的策略或戰術——一切都必須通過自我游戲來學習。
我們可以通過運行AI助理的多輪參賽副本來解決SumTo100的簡單游戲,并訓練一個回歸神經網絡來預測生成游戲的預期回報。
最后,通過此項實驗所得的收獲為我們研究更復雜的游戲做好了準備,但這將是我的下一篇文章的主要內容!
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Training an Agent to Master a Simple Game Through Self-Play,作者:Sébastien Gilbert